一种重组哺乳动物B细胞
- 国知局
- 2024-06-20 11:02:32
本发明涉及工程化细胞系及其用于快速产生用于蛋白表达的稳定细胞和产生用于定向进化和蛋白工程的蛋白文库的用途。
背景技术:
1、目前可用的用于从哺乳动物细胞产生蛋白的方法主要依赖于三种细胞系中的随机转基因整合:人胚胎肾293(hek293)细胞、小鼠骨髓瘤细胞(sp20和ns0)和中国仓鼠卵巢(cho)细胞。这些方法既昂贵又耗时。用于治疗性蛋白生产的生物技术工业标准要求产生稳定的重组蛋白生产细胞系,当从冷冻的细胞储备恢复时,其能够几乎无限地生产蛋白。
2、通过定向进化工程化蛋白需要通过体外诱变方法(例如,易错pcr、简并引物pcr诱变、dna改组(dna shuffling),然后克隆到表达宿主中并高通量筛选。可在哺乳动物细胞中产生的文库的大小由于差的转染效率而受到限制。因此,蛋白文库的高通量筛选通常采用正交表面展示平台,主要基于体外或微生物表达(例如,核糖体、噬菌体、酵母及细菌展示)。与哺乳动物细胞相比,这些宿主可能对蛋白折叠、糖基化模式和表达具有大的影响。然而,关键的是,标准系统不能有效地表达和筛选一些复杂的蛋白(例如,全长抗体)。另外,在治疗性蛋白的情况下,在体外或微生物系统中的文库筛选之后,经常需要将基因亚克隆到哺乳动物表达系统中以进行适当的表征。
3、本发明的基础问题是提供用于产生稳定哺乳动物细胞系的快速、可靠和廉价的方法,其可用于重组蛋白表达以及用于产生和筛选用于蛋白工程和定向进化应用的大蛋白文库。该问题通过独立权利要求的主题来解决。
4、定义
5、在本说明书的上下文中,术语“序列同一性”和“序列同一性百分比”是指通过比较两个对齐的序列而确定的值。用于比较的序列比对方法是本领域公知的。用于比较的序列的比对可如下进行:通过smith和waterman,adv.appl.math.2:482(1981)的局部同源性算法,通过needleman和wunsch,j.mol.biol.48:443(1970)的全局对齐算法,通过pearson和lipman,proc.nat.acad.sci.85:2444(1988)的相似性检索方法,或通过这些算法的计算机化实施方式,包括但不限于:clustal、gap、bestfit、blast、fasta和tfasta。用于执行blast分析的软件可公开获取,例如通过美国国家生物技术信息中心(http://blast.ncbi.nlm.nih.gov/)。
6、用于比较氨基酸序列的一个实例是blastp算法,其使用默认设置:预期阈值:10;字数:3;查询范围内的最大匹配:0;矩阵:blosum62;空位成本:存在11,延伸1;合成调整:条件合成得分矩阵调整。用于比较核酸序列的一个这样的实例是blastn算法,其使用默认设置的:预期阈值:10;字数:28;查询范围内的最大匹配:0;匹配/错配得分:1.-2;空位成本:线性。除非另有说明,本文提供的序列同一性值是指分别使用用于蛋白和核酸比较的上述确定的默认参数,使用blast程序套件(altschul等,j.mol.bio.215:403-410(1990))获得的值。
7、在本说明书的上下文中,术语"b细胞"是指已经通过v(d)j重组完成免疫球蛋白重链和轻链基因座的基因组重排的淋巴系细胞。
8、在本说明书的上下文中,术语"igh基因座"指免疫球蛋白重链基因的基因座。
9、在本说明书的上下文中,术语"位点定向核酸内切酶"是指选自包括crispr相关核酸内切酶、锌指核酸酶(zfn)、基于转录激活子样效应子的核酸酶(talen)和兆核酸酶(meganuclease)的组的核酸内切酶。
10、在本说明书的上下文中,术语"crispr相关核酸内切酶(cas9)"指酿脓链球菌(streptococcus pyogenes)的cas9核酸内切酶(spycas9)、spycas9的直系同源物或者spycas9的工程化蛋白变体或其直系同源物。
11、在本说明书的上下文中,术语"直系同源物(orthologue)"是指通过来自单个祖先基因的垂直继嗣进化的基因及其相应多肽。换句话说,直系同源基因/多肽共有一个共同的祖先,并且当一个物种分裂成两个独立的物种时被分开。然后将两个所产生的物种中的单个基因的拷贝称为直系同源物。为了确定两个基因是直系同源物,本领域技术人员可以通过比较所比对对齐的基因或多肽的核苷酸或氨基酸序列来进行基因谱系的系统发育分析。
12、在本说明书的上下文中,术语“抗体”以其在细胞生物学和免疫学领域中已知的含义使用;它是指全抗体,包括但不限于免疫球蛋白g型(igg)、a型(iga)、d型(igd)、e型(ige)或m型(igm)、其任何抗原结合片段或单链及其相关或衍生的构建体。全抗体是包含通过二硫键相互连接的至少两个重链(h)和两个轻链(l)的糖蛋白。每个重链由重链可变区(vh)和重链恒定区(ch)组成。重链恒定区由三个结构域ch1、ch2和ch3组成。每个轻链包括轻链可变区(此处缩写为vl)和轻链恒定区(cl)。轻链恒定区由一个结构域cl组成。重链和轻链的可变区包含与抗原相互作用的结合结构域。抗体的恒定区可以介导免疫球蛋白与宿主组织或因子的结合,所述宿主组织或因子包括免疫系统的各种细胞(例如效应细胞)和经典补体系统的第一组分。
13、本说明书上下文中的术语“抗体样分子”是指能够以高亲和力(kd≤10e-8mol/l)特异性结合另一分子或靶标的分子。类似于抗体的特异性结合,抗体样分子与其靶标结合。术语抗体样分子包括重复蛋白,例如设计的锚蛋白重复蛋白(molecular partners,zürich)、源自犰狳重复蛋白的多肽、源自富亮氨酸重复蛋白的多肽和源自三角形四肽(tetratricopeptide)重复蛋白的多肽。
14、术语“抗体样分子”还包括衍生自蛋白a结构域的多肽(蛋白a结构域衍生多肽)、衍生自纤连蛋白结构域fn3的多肽、衍生自共有纤连蛋白结构域的多肽、衍生自脂质运载蛋白的多肽、衍生自锌指的多肽、衍生自src同源结构域2(sh2)的多肽、衍生自src同源结构域3(sh3)的多肽、衍生自pdz结构域的多肽、衍生自γ-晶状体蛋白的多肽、衍生自泛素的多肽、衍生自半胱氨酸结多肽的多肽以及衍生自打结素(knottin)的多肽。
15、术语“蛋白a结构域衍生多肽”是指作为蛋白a的衍生物并且能够特异性结合免疫球蛋白的fc区和fab区的分子。
16、术语“犰狳重复蛋白”是指包含至少一个犰狳重复序列的多肽,其中犰狳重复序列的特征在于形成发夹结构的一对α螺旋。
17、在本说明书的上下文中,术语“人源化骆驼抗体(camelid antibody)”是指仅由重链或重链的可变结构域(vhh结构域)组成的抗体,其氨基酸序列已被修饰以增加其与在人中天然产生的抗体的相似性,并因此当被施用于人类时显示降低的免疫原性。
18、vincke等"general strategy to humanize a camelid single-domainantibody and identification of a universal humanized nanobody scaffold",jbiol chem.2009年1月30日;284(5):3273-3284和us2011165621a1中显示了人源化骆驼抗体的一般策略。
19、在本说明书的上下文中,术语“可结晶片段(fc)区”以其在细胞生物学和免疫学领域中已知的含义使用;它是指包含由通过二硫键共价连接的ch2和ch3结构域组成的两个相同重链片段的抗体的级分。
20、本文中使用的术语的进一步定义在适当时在整个文本中给出。
技术实现思路
1、根据本发明的第一方面,提供了一种用于产生细胞系的方法,其包括以下步骤:
2、a.提供多个哺乳动物b细胞,其中所述多个b细胞中的每一个包含编码标志物蛋白的转基因基因组dna序列,其中所述转基因基因组dna序列插入到包含在所述b细胞中的内源性免疫球蛋白基因座、特别是igh基因座中,并且其中所述转基因基因组dna序列适合于被定点核酸酶、特别是crispr-相关核酸内切酶(cas9)切割;
3、b.用编码目标蛋白的第二转基因dna序列替换编码所述标志物蛋白的所述转基因基因组dna序列;
4、c.基于所述标志物蛋白的存在或不存在来分选所述b细胞;和
5、d.收集其中不存在所述标志物蛋白的b细胞。
6、在某些实施方式中,标志物蛋白是荧光蛋白。在某些实施方式中,标志物蛋白是赋予对抗生素药物抗性的蛋白。
7、在某些实施方式中,所述标志物蛋白是荧光蛋白,并且所述分选通过流式细胞术进行。
8、在本说明书的上下文中,"用编码目标蛋白的第二转基因dna序列替换编码所述标志物蛋白的所述转基因基因组dna序列"的表述涉及dna序列的实际替换和功能替换,其方式是不再表达标志物蛋白,而代以表达目标蛋白。
9、本领域技术人员知道,"[编码标志物蛋白的]所述转基因基因组dna序列适合于被定点核酸酶切割"的表述包括编码标志物蛋白的dna序列内的切割和紧邻3’和/或5’侧翼区内的切割。
10、在某些实施方式中,所述转基因基因组序列侧接5’侧翼序列区(flankingsequence tract)和3’侧翼序列区,其中所述5’侧翼序列区和/或所述3’侧翼序列区适合于被定点核酸酶切割。
11、在某些实施方式中,所述侧翼序列区包含0至1500个核苷酸,特别是0个核苷酸或1至700个核苷酸,更特别是0个核苷酸或1至100个核苷酸。
12、适合于被定点核酸酶、特别是cas9切割的位点通常在编码标志物蛋白的序列的500个核苷酸内或在编码标志物蛋白的序列内。
13、在某些实施方式中,目标蛋白是抗体、抗体样分子、人源化骆驼抗体或免疫球蛋白抗原结合片段。
14、在稍后插入的目标基因是抗体的那些情况下,内源性免疫球蛋白vh基因被编码标志物蛋白的转基因基因组dna序列替换或破坏。
15、在本说明书的上下文中,术语"vh基因"是指编码免疫球蛋白重链的可变区的dna序列。
16、在本说明书的上下文中,术语"vl基因"是指编码免疫球蛋白轻链的可变区的dna序列。
17、在某些实施方式中,所述多种b细胞选自包含原代b细胞、永生化b细胞、杂交瘤细胞、骨髓瘤细胞、浆细胞瘤细胞和淋巴瘤细胞的组。
18、在某些实施方式中,标志物蛋白和/或目标蛋白在内源性免疫球蛋白启动子、特别是vh启动子的控制下表达。
19、在本说明书的上下文中,术语"vh启动子"是指"vh基因"的启动子。
20、在某些实施方式中,在所述多个b细胞中的每一个中内源性vh基因和内源性vl基因被破坏。这意味着b细胞既不能表达免疫球蛋白重链也不能表达免疫球蛋白轻链。
21、在某些实施方式中,对多个b细胞进行遗传修饰以组成型表达所述crispr相关核酸内切酶。
22、在某些实施方式中,多个b细胞经遗传修饰而以可诱导和可滴定的方式表达活化诱导的胞苷脱氨酶(aid)。
23、在本说明书的上下文中,术语"活化诱导的胞苷脱氨酶"指能使基因组dna内的胞嘧啶碱基脱氨基从而将它们转化为尿嘧啶(ec 3.5.4.38)的酶。
24、在某些实施方式中,多个b细胞包含安全港基因座,并且将包含编码crispr相关核酸内切酶的dna序列的第一表达盒插入到所述安全港基因座中。
25、在本说明书的上下文中,术语"安全港基因座(safe harbour locus)"是指适合于整合转基因的染色体位置。整合在安全港基因座中的转基因稳定表达并且不干扰内源性基因的活性。安全港基因座的实例是鼠类rosa26基因座或aavs1基因座。
26、在某些实施方式中,插入到所述安全港基因座中的crispr相关核酸内切酶受组成型活性启动子、特别是cag启动子、cbh启动子或cmv启动子的控制。
27、cag启动子是由融合至鸡β-肌动蛋白启动子的巨细胞病毒增强子组成的杂交构建体(jun-ichi等,gene 79(2):269-277)。cbh启动子是cba(鸡β-肌动蛋白)启动子的杂交形式(gray等,hum gene ther.,2011,22(9):1143-1153)。术语"cmv启动子"是指诸如人疱疹病毒5菌株toledo(genbank gu937742.2)等人疱疹病毒的人巨细胞病毒立即早期增强子和启动子序列。示例性cmv序列在genbank中以参考号x03922.1、m64940.1、m64941.1、m64942.1、m64943.1、m64944.1和k03104.1保藏。
28、在某些实施方式中,所述多个b细胞包含安全港基因座,并且将包含编码所述活化诱导的胞苷脱氨酶(aid)的dna序列的第二表达盒插入所述安全港基因座中。
29、在某些实施方式中,第二表达盒包含适合于由激活子分子诱导型激活的调节序列。
30、在某些实施方式中,第二表达盒包含诱导型表达系统,特别是tet-one诱导型表达系统。tet-one诱导型表达系统包含反式激活蛋白(tet-on)和诱导型启动子(ptre3gs)。在抗生素强力霉素的存在下,tet-on与ptre3gs中的teto序列结合并激活启动子下游基因(即,编码活化诱导的胞苷脱氨酶(aid)的基因)的高水平转录。如果强力霉素浓度降低,则表达降低,从而产生aid表达和体细胞超突变的可滴定系统。
31、在本说明书的上下文中,术语"体细胞超突变(shm)"是指产生多种基因组突变的细胞机制。shm涉及通过酶活化诱导的胞嘧啶脱氨酶(aid)在dna中使胞嘧啶脱氨基为尿嘧啶。所得到的碱基对错配(尿嘧啶-鸟苷,u:g)可导致基因组突变,例如,通过易错dna聚合酶切除尿嘧啶碱基并填充空位,或通过期间尿嘧啶被当作为胸苷的dna复制。
32、在本说明书的上下文中,术语"诱导型合成体细胞超突变(isshm)"指可通过激活来自诱导型表达系统的aid表达在所述多个b细胞中诱导的shm。
33、在某些实施方式中,通过cas9介导的位点定向dna切割,和随后通过同源定向修复(hdr)或非同源末端连接(nhej)进行的所述第二转基因dna序列的整合,从而介导所述转基因基因组dna序列的所述替换。该方法包括提供引导rna和替换dna。
34、在本说明书的上下文中,引导rna或grna是cas9-结合所必需的序列和定义待修饰的基因组靶的约23个核苷酸的用户定义的"靶向序列"组成的短合成rna(参见表2)。
35、这种引导rna可以通过转染体外转录的rna或商业合成的寡核苷酸rna来提供。作为另选,可以通过将dna序列转染或病毒转导到细胞中来提供引导rna,其中所述dna序列编码(并在细胞中表达)引导rna。可以提供多个引导rna以同时切割igh基因座中的多个基因组位点(这提高了转基因插入的效率)。
36、替换dna包含编码目标蛋白的所述第二转基因dna序列。替换dna可以通过环形或线性双链dna(dsdna)或单链dna(ssdna)(例如寡核苷酸)的转染或病毒转导来提供。
37、在本发明这一方面的某些实施方式中,所述目标蛋白是全长抗体。全长抗体可以基于合成的抗原结合片段(sfab)构建体。为了重新引入新的全长抗体,同时避免免疫球蛋白重链基因座和免疫球蛋白轻链基因座的靶向,全长轻链和重链都可以从天然vh启动子表达为单一转录物(图2的b)。
38、在某些实施方式中,所述多种b细胞是小鼠杂交瘤细胞。
39、在某些实施方式中,所述多个b细胞是小鼠杂交瘤细胞,并且用不同物种的ch区、特别是用人ch区替换鼠类ch区。这允许通过小鼠杂交瘤细胞产生人抗体。
40、在本说明书的上下文中,术语"ch区"是指编码免疫球蛋白重链恒定区的dna序列。
41、在本发明该方面的某些实施方式中,所述第二转基因核酸序列包含多于一个的目标基因和另外的启动子。这样,可以通过本发明的方法产生稳定表达多个基因或整个合成遗传网络的细胞系。
42、用于从稳定的哺乳动物细胞表达重组蛋白的现有技术方法需要至少8-10周的时间来开发,商业实体收费10,000美元/蛋白以上。用于工业治疗目的的稳定细胞系的产生需要长达一年。
43、通常,由于不同的蛋白生产效率,需要分析多个克隆。影响克隆生产力的因素是整合的数量和整合位点,因为已知基因沉默在一些整合位点随时间发生。
44、根据本发明的第二方面,提供了产生蛋白变体文库的方法。该方法包括根据本发明的第一方面或其上述任何实施方式的方法,随后进行以下额外步骤:用随机化核酸序列(通过供体dsdna或ssdna上的随机化区域)修饰转基因dna的区域。因此,通过定点诱变在目标蛋白内产生基因组突变。
45、根据本发明的该方面的替代方案,用于产生蛋白变体文库的方法包括根据本发明的第一方面或其任何上述实施方式的方法,随后进行以下额外步骤:
46、a.诱导活化诱导的胞苷脱氨酶(aid)的表达,从而通过诱导型合成体细胞超突变(isshm)在目标蛋白内产生多个基因组突变,或
47、b.用随机化的核酸序列修饰所述转基因dna的区域,从而通过定点诱变在目标蛋白内产生基因组突变。
48、根据本发明的第三方面,提供了产生蛋白变体文库的方法。该方法包括根据本发明的第一方面的方法,随后进行诱导活化诱导的胞苷脱氨酶(aid)的表达的额外步骤,从而通过诱导型合成体细胞超突变(isshm)在目标蛋白内产生多个基因组突变。
49、aid在免疫球蛋白(igh或igk或igl)基因座内产生突变方面特别有效。因此,对于isshm有利的是,编码目标蛋白的dna序列被插入到免疫球蛋白基因座,例如igh基因座中。
50、在某些实施方式中,对转基因基因组dna序列的所述区域的所述修饰是通过cas9介导的位点定向dna切割所介导的,并且:
51、a.随后通过同源定向修复(hdr)或非同源末端连接(nhej)整合所述随机转基因dna序列,或
52、b.随后通过由nhej修复转基因dna序列来插入或缺失核苷酸。
53、该方法包括以与本发明的第一方面类似的方式提供引导rna和替换dna。引导rna和随机化核酸序列可以通过包含简并核苷酸或三核苷酸密码子的dsdna或ssdna的转染或病毒转导来提供。为了提高ssdna的hdr效率,在5’和3’末端以及整个ssdna寡核苷酸中引入硫代磷酸酯键。硫代磷酸酯键是磷酸酯主链的非桥氧更换为硫原子。磷酸酯骨架中的硫原子增加ssdna对核酸酶降解的抗性。
54、在本说明书的上下文中,术语"简并核苷酸"是指编码任何混合核苷酸组合物的dna序列的位置。
55、在本说明书的上下文中,术语"三核苷酸"或三聚体亚磷酰胺是指编码任何混合氨基酸组合物的dna序列的三个连续核苷酸。
56、本领域技术人员知道,根据本发明第二方面的蛋白变体文库的产生包括细胞系文库的产生。
57、在目标蛋白是抗体的那些情况下,就改进的或新的抗原结合而言筛选突变的抗体。将荧光标记的抗原加入到细胞中,并通过facs筛选细胞。作为另选,初始筛选步骤可通过使用缀合至抗原的磁珠的磁缔合细胞分选(macs)来进行。
58、可以进行几轮筛选和isshm或定点诱变以继续构建抗体或蛋白。
59、在某些实施方式中,标志物蛋白是荧光蛋白。
60、作为非限制性实例,这样的荧光蛋白可以选自来自维多利亚多管发光水母(aequorea victoria)的绿色荧光蛋白(gfp)及其衍生物,例如:
61、-增强型蓝色荧光蛋白(ebfp)、增强型蓝色荧光蛋白2(ebfp2)、azurite、
62、mkalama1、sirius
63、-增强型绿色荧光蛋白(egfp)、emerald、superfolder avgfp、t-sapphire
64、-黄色荧光蛋白(yfp)、增强型黄色荧光蛋白(eyfp)、citrine、venus、ypet、
65、topaz、syfp、mametine
66、-增强型青色荧光蛋白(ecfp)、mturquoise、mturquoise2、cerulean、cypet、
67、scfp。
68、用于实施本发明的荧光蛋白也可以选自由来自海葵(discosoma striata)的荧光蛋白及其衍生物组成的组:
69、-mtagbfp、
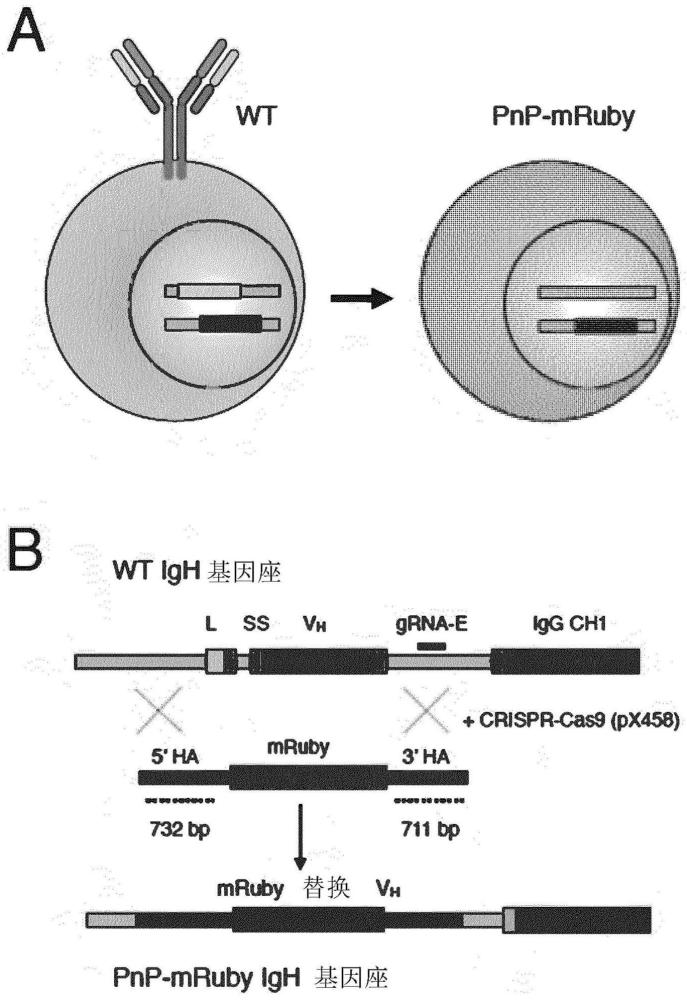
70、-tagcfp、amcyan、midoriishi cyan、mtfp1
71、-azami green、mwasabi、zsgreen、taggfp、taggfp2、turbogfp、copcfp、
72、acegfp
73、-tagyfp、turboyfp、zsyellow、phiyfp
74、-kusabira orange、kusabira orange2、morange、morange2、dtomato、
75、dtomato-tandem、dsred、dsred2、dsred-express(t1)、dsred-express2、dsred-max、dsred-monomer、turborfp、tagrfp、tagrfp-t
76、-mruby、mapple、mstrawberry、asred2、mrfp1、jred、mcherry、eqfp611、tdrfp611、hcred1、mraspberry
77、-tdrfp639、mkate、mkate2、katushka、tdkatushka、hcred-tandem、mplum、aq143。
78、荧光蛋白还包括衍生自来自蓝细菌红海束毛藻(trichodesmium erythraeum)的α-别藻蓝蛋白的蛋白,例如小的超红荧光蛋白(smurfp)。
79、本领域技术人员知道,根据本发明的第一方面的方法也可以采用未包括在上述列表中的其它荧光蛋白来进行。
80、本发明的另一方面提供了包含表达的转基因基因组dna序列的人b细胞系,所述表达的转基因基因组dna序列插入到包含在通过根据本发明的第一、第二或第三方面的方法获得的所述b细胞中的内源性免疫球蛋白基因座中。
81、根据本发明的又一方面,提供了通过根据本发明的第一、第二或第三方面的方法获得的蛋白。
82、根据本发明的又一方面,提供了通过根据本发明的第一、第二或第三方面的方法获得的蛋白变体文库。
83、根据本发明的又一方面,提供了哺乳动物b细胞,其中
84、a.将编码标志物蛋白的转基因基因组dna序列插入到包含在所述b细胞中的内源性免疫球蛋白基因座、特别是igh基因座中,其中所述标志物基因编码荧光蛋白,并且其中,
85、b.所述转基因基因组序列适合于被定点核酸酶、特别是crispr相关核酸内切酶(cas9)切割。
86、在某些实施方式中,哺乳动物b细胞是人细胞。
87、本发明的另一方面涉及多个哺乳动物b细胞,每个细胞编码转基因蛋白的变体。所述多个哺乳动物b细胞在其整体上构成这种变体的文库。包含在所述多个b细胞中的多个b细胞的每个成员包含编码目标蛋白的变体的转基因基因组dna序列。将转基因基因组dna序列插入到包含在所述b细胞中的内源性免疫球蛋白基因座、特别是igh基因座中,并且由所述多个b细胞的成员编码的每个变体不同于由所述多个b细胞的另一个成员编码的任何其它变体。
88、本领域技术人员理解,多个b细胞的每个成员可能由多于一个个体细胞表示,即,一个克隆的几个细胞可以构成一个成员。这里的重要方面在于,变体对于一个成员是相同的,并且大量(在某些实施例中,等于或大于≥100、≥1000、≥10000或甚至≥100000)的不同变体可以存在于所述多个b细胞中。
89、在本发明的该方面的某些实施方式中,多个b细胞中所编码的每个变体在其氨基酸序列的一个至五个位置上与另一变体不同。
90、在本发明的该方面的某些实施方式中,每个变体具有与由所述多个b细胞的成员编码的任何另一变体至少80%、85%、90%、95%、97%、98%或99%的同一性。换句话说,变体可以在个体成员之间共享其序列的重要部分,并且仍代表非常宽的变体谱。
91、在本发明这一方面的某些实施方式中,所述多种b细胞选自包含原代b细胞、永生化b细胞、杂交瘤细胞、骨髓瘤细胞、浆细胞瘤细胞和淋巴瘤细胞的组。
92、虽然用于单个可分离特征的替代方案在本文称之为"实施方式",应当理解这些替代方案可以被自由地组合以形成本文公开的本发明的分立实施方式。
93、实施例
94、通过以下实施例和附图进一步说明本发明,从这些实施例和附图可以得到进一步的实施方式和优点。这些实施例旨在说明本发明,但不限制其范围。
95、为了实现本发明,发明人已经产生了即插即示(plug-and-(dis)play(pnp))型哺乳动物细胞系。发明人使用小鼠b淋巴细胞(杂交瘤细胞),其用作抗体蛋白的生产工厂。pnp细胞系由以下组分组成:
96、1)igh基因座中的内源性vh基因被荧光蛋白(mruby,最初称为mruby2,源自addgene.org质粒#:40260(lam等,nat methods 2012,9:1005-1012))替代。这通过如下实现:用具有引导rna(grna)的crispr-cas9质粒(px458)(addgene.org质粒#:48138)(cong等,science 2013,339:819-823)转染wt杂交瘤细胞,所述引导rna靶向vh和igg基因之间的内含子。此外还共转染了由mruby基因和对应于wt杂交瘤细胞igh基因座的同源臂组成的供体dna构建体。crispr-cas9系统在wt细胞的dna中引入靶向双链断裂(dsb),其促进同源定向修复(hdr)或非同源末端连接(nhej)的dna修复机制,导致mruby基因代替vh基因的位点特异性整合。使用天然igh启动子表达mruby(图1的a-d)。
97、2)使igk基因座中的内源性vl基因缺失以产生轻链敲除细胞系。这通过用具有grna的px458转染杂交瘤细胞(如1中所述)来完成,所述grna靶向侧接在igk基因座中的vl基因的两个位点。这导致杂交瘤细胞中vl基因的缺失和内源性轻链表达的敲除(图1的e-g)。
98、所得到的细胞被称为pnp-mruby细胞。
99、3)pnp-mruby细胞被转化为表达新抗体的细胞,这些细胞被称为pnp-igg细胞。这通过用具有靶向mruby基因的grna(现在整合在igh基因座中)的px458转染pnp-mruby细胞来完成。此外还共转染了具有对应于igh基因座的同源臂的合成抗体片段(sfab)的供体dna构建体。类似于1),crispr-cas9促进dsb和hdr或nhej,这导致sfab靶向整合到igh基因座中。其结果是全长抗体(igk和igh)从igh基因座表达为单个rna转录物(图2)。
100、pnp-mruby细胞可以利用单一转染和选择步骤转化为稳定的表达重组蛋白的哺乳动物细胞系(例如pnp-igg)(图3,图4)。
101、4)pnp-mruby细胞被工程化以用于构成型表达cas9(pnp-mruby-cas9细胞)。这是通过在组成型活性启动子(例如,cag启动子或cmv启动子)(addgene.org质粒#48139)的控制下用具有靶向rosa26的安全港基因座中的位点的grna的px458和由cas9-2a-嘌呤霉素组成的供体dna构建体来转染pnp-mruby细胞来实现的(platt等,cell 2014,159:440-455;ran等,nat protoc 2013,8:2281-2308)。这些细胞的优点在于,它们消除了用crispr-cas9质粒(px458)转染及因此将pnp-mruby细胞转化为表达重组蛋白(例如pnp-igg)的细胞系的需要,仅需要转染grna(体外转录或商业合成)和供体构建体(替换dna,例如,sfab),这提高了效率(图5的a)。
102、通过使用由t7启动子、编码grna的定制间隔区和反式激活区组成的模板dna以依照px458设计的方式进行grna的体外转录。该构建体充当t7转录试剂盒(thermo,am1334)的模板,由此体外转录产生嵌合的单个grna。本规程改编自:https://www.protocols.io/view/in-vitro-transcription-of-guide-rnas-d4w8xd?step=3。
103、5)在vh基因(cdr-h3)的互补决定区3中进一步修饰表达hel的抗原特异性抗体的pnp-igg细胞(pnp-hel23),以通过定点诱变产生大的蛋白变体文库,然后可以就增加的抗原亲和力或新的抗原结合而言筛选其。这通过以下方式完成:
104、将pnp-hel23细胞的sfab基因进行修饰以敲除抗体表达。通过用含有靶向cdr-h3的引导rna的px458载体转染这些细胞,通过经由nhej修复而插入或缺失核苷酸来敲除抗体表达。核苷酸的插入或缺失引起移码突变,并随后改变残留在基因中的所有下游氨基酸。抗体表达阴性的单细胞克隆可通过流式细胞术分离并扩增。然后通过表型和基因型特征选择合适的克隆(pnp-hel23-igh-)。然后可以通过随机核酸的整合从所述细胞克隆衍生蛋白变体的文库。
105、抗体的亲和成熟可通过转染或病毒转导来提供靶向cdr-h3的引导rna和替换dna来完成,其中替换dna包含三个随机化核酸的区域,所述三个随机化核酸对应于在原始cdr-h3内发现的每个位置处的单个氨基酸(图11)。
106、用于发现新的抗原特异性抗体的蛋白文库也可以通过以与用于抗体亲和成熟所述的方法类似的方式完全替换cdr-h3而产生。靶向cdr-h3的引导rna和替换dna通过转染或病毒转导提供,其中替换dna含有包含对应于cdr-h3可变长度的3至69个随机化核酸的区域(图11)。
107、在这两种情况下,通过流式细胞术筛选并分选产生针对靶抗原的功能性抗体的细胞。
108、6)将该即插即示型(pnp)哺乳动物细胞系进一步工程化,使得它们能够通过诱导型合成体细胞超突变isshm产生大的蛋白变体库,其然后可以用于定向进化和高通量筛选(pnp-iaid细胞)。这以以下方式完成:
109、用含有靶向安全港基因座rosa26的sgrna和供体构建体(替换dna)的px458载体转染pnp-mruby2细胞。供体构建体包含tet-one系统(clontech)(heinz等,human genetherapy,2011,22:166-176),其由以下组分组成(图5的b):
110、i.在正向,人磷酸甘油酯激酶1(hpgk)启动子,其提供tet-on 3g蛋白的组成型表达;
111、ii.在正向,tet-on 3g反式激活蛋白的编码序列,该蛋白是与vp16激活结构域(rtta)连接的rtetr的融合蛋白;
112、iii.在反向,ptre3gs诱导型启动子,ptre3g的修饰版本,其由修饰的tet响应元件(tre)组成并且包含与最小cmv启动子连接的7个tet操纵基因的直接重复;
113、iv.目标基因(goi),其表达由ptre3gs启动子驱动,并且其包含编码以下的dna序列:
114、i.荧光报告蛋白(例如,gfp或蓝色荧光蛋白(bfp));
115、ii."自切割"2a肽;
116、iii.活化诱导的胞苷脱氨酶(aid);
117、v.对应于rosa 26基因座的同源臂(>500bp)。
118、作为另选,可以使用没有同源臂的供体构建体。在这些情况下,供体构建体可以通过nhej整合。
119、在另一种方法中,使用pnp-mruby-cas9细胞作为创建pnp-iaid细胞系的起始平台。在这种情况下,用靶向rosa26的安全港基因座中的正交位点的体外转录grna和供体构建体(替换dna)转染pnp-mruby-cas9细胞。供体包括在上文4)中描述的相同组分。
120、在另一种方法中,用靶向小鼠的天然aid基因组基因座的体外转录grna转染pnp-mruby-cas9细胞。在这种情况下,供体构建体由上文4)中描述的相同元件组成,但不同之处在于在iv)中仅存在编码活化诱导的胞苷脱氨酶(aid)的基因的第一内含子(图5的c)。
121、在抗生素强力霉素(dox)的存在下,tet-on与ptre3gs中的teto序列结合并激活高水平的转录。然而,在dox的量减少的情况下,表达减少,从而产生aid表达和shm的可滴定系统。pnp-iaid细胞可以用dox长期培养,以便在igh基因座中产生大的蛋白变体文库。然后,通过流式细胞术的高通量筛选可以完成蛋白的定向进化和工程化(图5的d)。
本文地址:https://www.jishuxx.com/zhuanli/20240619/936.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。