基于安全强化学习的列车节能运行控制方法及相关装置
- 国知局
- 2024-08-02 16:15:12
本发明实施例涉及列车运行控制,尤其涉及一种基于安全强化学习的列车节能运行控制方法及相关装置。
背景技术:
1、城市轨道交通作为一种高效、安全、舒适且快速的运输方式,在过去的数十年间取得了显著的发展。列车节能控制的核心问题是,在满足列车特性、轨道梯度、曲线和速度限制等约束条件的前提下,寻求具有最小化能源消耗并保持时间表的列车运行速度分布,这一过程也被称为列车轨迹优化(train trajectory optimization,tto)。tto问题是一个综合性且复杂的问题,pmp方法、非线性规划方法对于轨道梯度、限度等更复杂问题带来的硬约束时面临很大的困难,很难求得最优策略。而传统的rl算法通过软约束的方法对不满足约束的动作进行惩罚,采样效率较低,学习缓慢,甚至可能打破约束的限制,得到超出安全限界的列车运行轨迹。因此,现有的列车控制策略存在计算时间长,在考虑计划运行时间约束下的控制策略精度较低的技术问题。
技术实现思路
1、本发明实施例提供了一种基于安全强化学习的列车节能运行控制方法及相关装置,能够加快最优控制策略的训练速度,提高了控制策略对列车运行的控制精度。
2、第一方面,本发明实施例提供了一种基于安全强化学习的列车节能运行控制方法,包括:
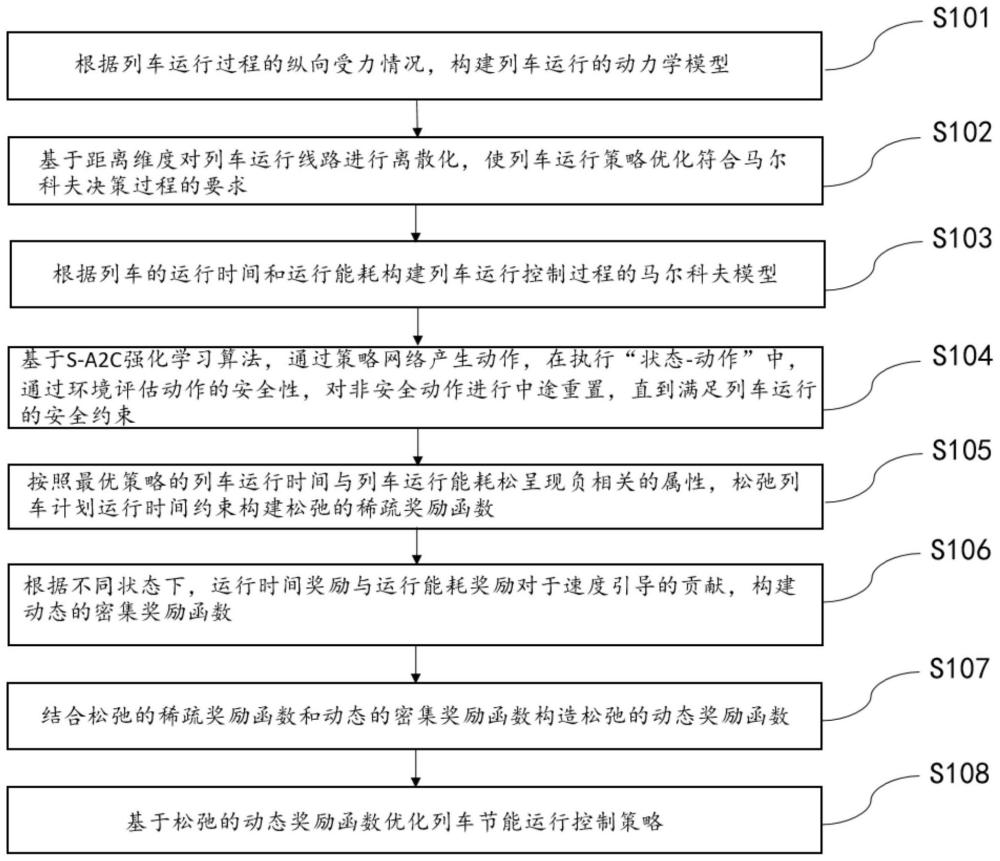
3、根据列车运行过程的纵向受力情况,构建列车运行的动力学模型;
4、基于距离维度对列车运行线路进行离散化,使列车运行策略优化符合马尔科夫决策过程的要求;
5、根据列车的运行时间和运行能耗构建列车运行控制过程的马尔科夫模型;
6、基于s-a2c强化学习算法,通过策略网络产生动作,在执行“状态-动作”中,通过环境评估动作的安全性,对非安全动作进行中途重置,直到满足列车运行的安全约束;
7、按照最优策略的列车运行时间与列车运行能耗松呈现负相关的属性,松弛列车计划运行时间约束构建松弛的稀疏奖励函数;
8、根据不同状态下,运行时间奖励与运行能耗奖励对于速度引导的贡献,构建动态的密集奖励函数;
9、结合松弛的稀疏奖励函数和动态的密集奖励函数构造松弛的动态奖励函数;
10、基于松弛的动态奖励函数优化列车节能运行控制策略。
11、在一些实施例中,所述列车运行的动力学模型表示为:
12、
13、其中,x∈[0,x]为列车运行距离,列车运行速度为v∈[0,v],t为列车运行时间,m为列车质量,f(v)、b(v)、w0(v)和wi(x)分别表示牵引力、制动力、列车基本阻力和列车所受的线路附加阻力,αf和αb分别是牵引力和制动力使用系数0≤αf,αb≤1。
14、在一些实施例中,所述基于距离维度对列车运行线路进行离散化,包括:
15、以列车轨道梯度和限速的拐点为依据,将线路离散为h个大区段,每个大区段长为lh,(h=1,2,l,h),设置最大离散间隔为δl,则每个大区段被离散为个小区段,则每个小区段限速和坡度均为常数,离散的空间维度为:
16、
17、在一些实施例中,所述马尔科夫决策过程被定义为其中表示状态空间,表示动作空间,表示状态传递函数,表示奖励函数,γ表示折扣因子;在第i步,agent的状态为通过采样动作和环境进行交互转移到新的状态si+1,并获得奖励ri;采用的当前动作不仅影响即时奖励,还通过未来奖励来影响之后的状态,其状态定义为其中,ti和ei表示运行时间和运行能耗:
18、
19、在区间[0,x]上,列车的里运行时间tn∈[tmin,tmax],列车的运行能耗en∈[emin,emax],动作空间能被定义为ma表示最大牵引运行,cr表示巡航运行,co表示惰行,mb表示最大制动,以列车的运行时间和运行能耗为基础构建目标函数为:
20、
21、其中,π是列车运行控制策略,je=en,jδt=|tn-tp|,tp表示列车在区间的计划运行时间。
22、在一些实施例中,所述通过策略网络产生动作,在执行“状态-动作”中,通过环境评估动作的安全性,对非安全动作进行中途重置,直到满足列车运行的安全约束,包括:
23、根据策略网络π(·|si;θnow)生成的概率分布pdista,在此基础上采样动作ai与环境交互,实现状态转移,通过安全判定系数ξsd判定是否需要进行操作工况重置;
24、
25、当v(x)>vmax(x),则ξsd=1时,则表示继续采用动作ai将使得列车超速,不符合列车安全操作需要,需要对动作进行重置;由环境输出中间状态si'和安全判定系数ξsd,为避免重置后的动作a′i=ai,需要构建动作集即即将动作ai的概率密度同时对动作空间中各元素的概率分布进行归一化得到新的概率分布根据重置后的概率分布重新采用得到动作a′i,以(s′i,a′i)和环境重新进行交互,直到其满足安全条件约束,使agent转移到新的状态si+1。
26、在一些实施例中,所述稀疏奖励函数的构建过程如下:
27、在列车运行中,列车在区间的运行时间与计划运行时间的偏差应小于允许时间偏差δt,即|tn(π)-tp|≤δt;
28、对于任一的最优列车控制策略π*,如果tn(π*)=tp,tp∈[tmin,tmax],则tp与最优策略的能耗en(π*)是负相关,那么对于则有因此一个列车运行时间的奖励函数定义为:
29、
30、通过能耗奖励函数re度量列车的运行能耗水平:
31、
32、结合列车的运行能耗,构建稀疏奖励函数:
33、
34、其中,和分别为运行时间和运行能耗权重系数。
35、在一些实施例中,所述动态奖励函数的构建过程如下:
36、根据列车在不同状态下的速度水平,设计动态的密集奖励函数如下:
37、
38、rt和re分别为密集的时间奖励和能耗奖励:
39、
40、
41、其中,计划平均运行速度为表示列车以mt加速至然后转换为cr,最后mb完成全部任务的能耗,λe和λt分别为能耗和运行时间的动态平衡系数,
42、
43、用一个线性平衡函数fbal(x)来平衡其权重值,
44、
45、因此,松弛的动态奖励函数能被定义为:
46、
47、第二方面,本发明实施例还提供了一种基于安全强化学习的列车节能运行控制装置,所述装置包括:
48、分析模块,用于根据列车运行过程的纵向受力情况,构建列车运行的动力学模型;
49、离散模块,用于基于距离维度对列车运行线路进行离散化,使列车运行策略优化符合马尔科夫决策过程的要求;
50、构建模块,用于根据列车的运行时间和运行能耗构建列车运行控制过程的马尔科夫模型;
51、动作模块,用于基于s-a2c强化学习算法,通过策略网络产生动作,在执行“状态-动作”中,通过环境评估动作的安全性,对非安全动作进行中途重置,直到满足列车运行的安全约束;
52、约束模块,用于按照最优策略的列车运行时间与列车运行能耗松呈现负相关的属性,松弛列车计划运行时间约束构建松弛的稀疏奖励函数;
53、引导模块,用于根据不同状态下,运行时间奖励与运行能耗奖励对于速度引导的贡献,构建动态的密集奖励函数;
54、构造模块,用于结合松弛的稀疏奖励函数和动态的密集奖励函数构造松弛的动态奖励函数;
55、优化模块,用于基于松弛的动态奖励函数优化列车节能运行控制策略。
56、第三方面,本发明实施例还提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如第一方面所述的基于安全强化学习的列车节能运行控制方法。
57、第四方面,本发明实施例还提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行如第一方面所述的基于安全强化学习的列车节能运行控制方法。
58、根据本发明实施例提供的基于安全强化学习的列车节能运行控制方法及相关装置,其中,基于安全强化学习的列车节能运行控制方法包括:根据列车运行过程的纵向受力情况,构建列车运行的动力学模型;基于距离维度对列车运行线路进行离散化,使列车运行策略优化符合马尔科夫决策过程的要求;根据列车的运行时间和运行能耗构建列车运行控制过程的马尔科夫模型;基于s-a2c强化学习算法,通过策略网络产生动作,在执行“状态-动作”中,通过环境评估动作的安全性,对非安全动作进行中途重置,直到满足列车运行的安全约束;按照最优策略的列车运行时间与列车运行能耗松呈现负相关的属性,松弛列车计划运行时间约束构建松弛的稀疏奖励函数;根据不同状态下,运行时间奖励与运行能耗奖励对于速度引导的贡献,构建动态的密集奖励函数;结合松弛的稀疏奖励函数和动态的密集奖励函数构造松弛的动态奖励函数;基于松弛的动态奖励函数优化列车节能运行控制策略。基于此,本发明通过建立距离离散化的列车节能运行仿真环境,为满足列车运行过程中速度限制的约束,在网络训练中,通过一种安全动作重置机制来对不安全动作进行重置,考虑计划运行时间的约束下,以能耗最小为目标,设计了一种松弛的动态奖励函数,引导网络的持续进化至收敛。在真实的列车数据和线路信息上,验证了方法输出的运行控制策略符合预期,能够满足列车计划运行时间的要求,同时达到能耗最优的目标。基于此,本发明实施例能够加快最优控制策略的训练速度,提高了控制策略对列车运行的控制精度。
本文地址:https://www.jishuxx.com/zhuanli/20240718/250032.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表