基于全局路径引导和深度强化学习的无人机运动规划方法
- 国知局
- 2024-07-31 23:32:12
本发明属于无人机运动规划,特别涉及一种基于全局路径引导和深度强化学习的无人机运动规划方法。
背景技术:
1、随着无人机技术的不断发展和广泛应用,固定翼无人机由于机动性高,生存能力强,逐渐成为了许多领域的重要工具,在民用和军用方面都具有巨大的潜力。运动规划作为无人机飞行控制中的关键问题之一,对于实现安全、高效、自主的飞行任务至关重要。固定翼无人机的动力学运动规划(kinodynamic motion planning)需要在考虑运动学方程、运动学约束(如避开障碍物)、动力学约束(如速度、加速度、转弯半径等约束以及运动学方程)等条件的前提下,从而成功到达目标位置。
2、目前应用于无人机的运动规划方法主要有群体优化算法、基于rrt的采样算法、人工势场法以及基于深度神经网络的人工智能方法。群体优化方法对于运动规划问题,将群体中的个体定义为不同的求解策略,通过适应度值在迭代过程中选择不同的规划路径点,但该方法线上计算量大,且容易陷入局部最优点;人工势场法和基于rrt的采样算法均应用于无人机的路径规划层面,其中人工势场法利用人工势场中同性电荷之间相互排斥、异性电荷之间相互吸引的原理,通过为无人机、障碍物和目标点分配适当的电荷属性,实现无人机避开障碍物,成功到达指定目标点;基于采样的路径规划(rrt,rrt*等)则通过在搜索空间中随机采样点并扩展树结构,快速探索无人机的路径规划,但该方法需要构造有效的搜索策略;深度强化学习等人工智能技术近年来被广泛用于车载导航等领域,其根据探测到的距离等信息,通过与环境进行交互,学习探索回报极大化的行为策略,从而实现自主避障。这种方法具有学习能力,能够适应不同环境和任务需求。
3、固定翼无人机的运动学方程为二阶模型,但目前针对固定翼无人机的运动规划技术大多对其进行了简化。如现有的群体优化算法、基于rrt的采样算法等传统算法为提高计算效率,大多将其运动学方程简化为基于一阶模型的运动基元,尽管降低了规划时间,但可能在实际飞行中产生安全隐患。而基于深度神经网路的学习方法展现出了在处理高维和复杂环境状态方面的巨大潜力,适用于处理基于二阶运动学方程的固定翼无人机运动规划问题。但考虑到该方法在探索过程中需要极大的数据量和训练回合才能搜索到最优策略,因此训练效率并不高。
4、综上所述,尽管已有研究在无人机路径规划方面取得了一些成果,但考虑固定翼无人机的二阶运动学方程与动力学特性,在多障碍(动态及静态障碍物)环境下实现安全快速运动规划,提高训练效率仍然是值得研究的问题。
技术实现思路
1、为了解决上述问题,本发明的目的在于提供一种基于全局路径引导和深度强化学习的无人机运动规划方法。
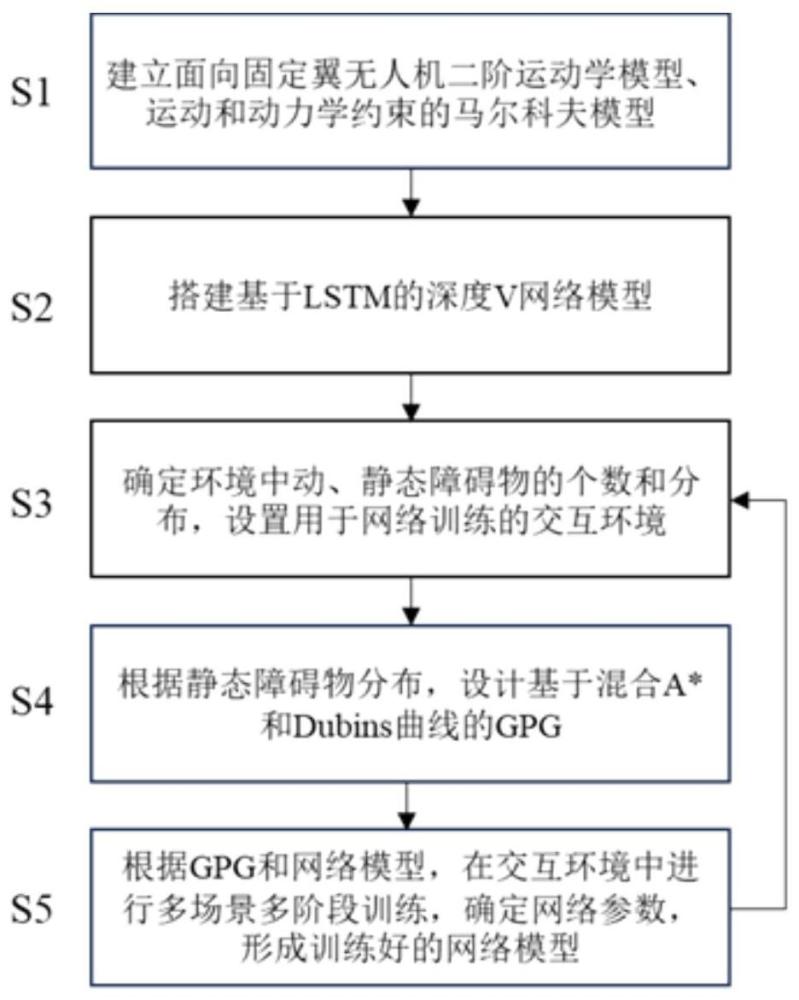
2、为了达到上述目的,本发明提供的基于全局路径引导和深度强化学习的无人机运动规划方法包括按顺序进行的下列步骤:
3、(1)考虑固定翼无人机二阶运动学模型、包括躲避障碍物的运动学约束、包括速度、加速度、转弯半径的动力学约束在内的条件约束,建立包括状态空间、动作空间、回报函数、状态转移概率、折扣因子在内的马尔可夫决策过程;
4、(2)根据步骤(1)中马尔科夫决策过程状态空间的某一状态量,利用lstm处理维数可能发生变化的状态量、深度v网络处理动作空间中的连续动作量,搭建包括lstm和深度v网络的网络模型;
5、(3)根据步骤(1)中马尔科夫决策过程的动力学约束(障碍物约束),随机设置交互环境中动态、静态障碍物的个数和分布,得到用于训练和测试的交互环境;
6、(4)根据步骤(3)中交互环境的静态障碍物分布,考虑固定翼无人机二阶运动学模型,基于混合a*得到安全路径点,并利用dubins曲线拟合出安全轨迹,通过时间点采样得到全局引导路径;
7、(5)根据步骤(4)中的全局引导路径和步骤(2)中的网络模型,在步骤(3)设置的交互环境中生成训练数据进行网络训练,通过多阶段多场景训练确定具备自主避障能力的网络参数,形成训练好的网络模型。
8、在步骤(1)中,所述考虑固定翼无人机二阶运动学模型、包括躲避障碍物的运动学约束、包括速度、加速度、转弯半径的动力学约束在内的条件约束,建立包括状态空间、动作空间、回报函数、状态转移概率、折扣因子在内的马尔可夫决策过程的方法是:
9、根据固定翼无人机平移加速度、偏航角速度等控制量与位置、速度、偏航角的关系,得到二阶运动学模型;在此基础上考虑对躲避传感范围内动静态障碍物的运动学约束,和速度、加速度、转弯半径等动力学约束,建立包括状态空间、动作空间、回报函数、状态转移函数和折扣因子的马尔可夫决策过程。
10、在步骤(2)中,所述根据步骤(1)中马尔科夫决策过程状态空间的某一状态量,利用lstm处理维数可能发生变化的状态量、深度v网络处理动作空间中的连续动作量,搭建包括lstm和深度v网络的的网络模型的方法是:根据步骤(1)中包括自身和传感范围内移动障碍物位置、速度、偏航角、在内的某一状态量,利用lstm处理由于传感范围内移动障碍物数量变化导致维数可能发生变化的状态量,并利用深度v网络处理包括平移加速度、偏航角速度、垂直速度在内的连续动作量,搭建包括lstm和深度v网络的网络模型。
11、在步骤(3)中,所述根据步骤(1)中马尔科夫决策过程的运动学约束(躲避障碍物),随机设置交互环境中动态、静态障碍物的个数和分布,得到用于训练和测试的交互环境的方法是:
12、根据步骤(1)mdp的运动学约束,随机设置交互环境中动态、静态障碍物的个数和分布,得到用于网络训练和测试的交互环境。
13、在步骤(4)中,所述根据步骤(3)中交互环境的静态障碍物分布,考虑固定翼无人机二阶运动学模型,基于混合a*得到安全路径点,并利用dubins曲线拟合出安全轨迹,通过时间点采样得到全局引导路径的方法是:
14、根据步骤(3)中交互环境设置的面向不同场景的静态障碍物分布,针对各场景,考虑固定翼无人机二阶运动学模型,基于混合a*得到安全路径点,并利用dubins曲线拟合出安全轨迹,通过时间点进行等间距采样,得到全局引导路径。
15、在步骤(5)中,所述根据步骤(4)中的全局引导路径和步骤(2)中的网络模型,在步骤(3)设置的交互环境中生成训练数据进行网络训练,通过多阶段多场景训练确定具备自主避障能力的网络参数,形成训练好的网络模型的方法是:
16、根据步骤(4)中的全局引导路径和步骤(2)中的网络模型,在步骤(3)设置的交互环境中生成训练数据进行网络训练,通过多阶段多场景训练确定具备自主避障能力的网络参数,形成训练好的网络模型,可在步骤(3)生成的新场景中进行测试以验证规划效果。
17、本发明提供的基于全局路径引导和深度强化学习的无人机运动规划方法具有如下有益效果:利用深度神经网络强大的计算能力,可以在满足固定翼无人机的二阶运动学模型、运动学约束、动力学约束的情况下,实现安全快速路径规划;另一方面,将混合a*方法与dubins曲线相结合,快速生成满足飞行特性的全局引导路径,解决由于二阶模型产生的搜索空间大的问题,提高训练效率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197870.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。