一种基于威胁度强化学习算法的多主体追逃最优策略方法与流程
- 国知局
- 2024-08-01 00:05:27
本发明涉及多智能体强化学习领域,尤其涉及一种基于威胁度强化学习算法的多主体追逃最优策略方法。
背景技术:
1、在传统的集群无人机对抗、追逃、围捕的场景中,无人机的追捕策略中通常采用传统的路径规划算法,如蚁群算法、粒子群优化算法和a*算法等,已被用于基于环境建模和性能评估获得最优路径。然而,如果目标移动或外部环境发生变化,这些方法需要重新建模环境,并相应地规划新的有效路径。这一过程会消耗大量计算资源,并会显著降低实时有效性。因此,无人机作为一种智能体,为无人机系统提供自主学习和自适应能力,并实时自主做出跟踪决策,具有重要意义。通过将深度学习的感知能力与强化学习的决策能力相结合,深度强化学习(drl)可用于通过智能体与环境之间的交互过程在线生成自适应策略,并在无人机运动规划领域表现良好。
2、深度神经网络(dnn)和深度强化学习(drl)技术逐渐成为研究热点,强化学习已经具备了自主学习和分布式计算的能力,集群无人机可视为多智能体系统,多智能体系统不仅可以完成单个智能体的目标,而且可以超过单个智能体的效率,这意味着多个智能体可以增加其强度。对于多智能体联合环境,预测和推断其他代理的意图对于在不同的合作和竞争任务中与其他代理进行交互至关重要,多智能体强化学习算法很是实现集群智能的最佳解决方案。算法在线下培训学习部署后,能够学习如何实现多智能体合作完成复杂任务,并且在线上以极高的效率完成任务,这些处理决策完全是分布式的,消除了集中式存在的不可控因素,从可靠性角度来讲每一个智能体都能并且相比传统的决策过程具有最小的响应时间,但由于多智能体随着仿真个体数量的增长,状态空间呈指数增长后会造成解空间的过大,致使这一类通过经验回放或遍历求解的算法难以获得收敛,无法在高维情况下展现出一定的智能性。
技术实现思路
1、本发明解决的技术问题是:克服现有技术的不足,提出一种基于威胁度强化学习算法的多主体追逃最优策略方法,解决由于集群无人机对抗数量上升导致状态空间呈指数上升带来的收敛困难问题。
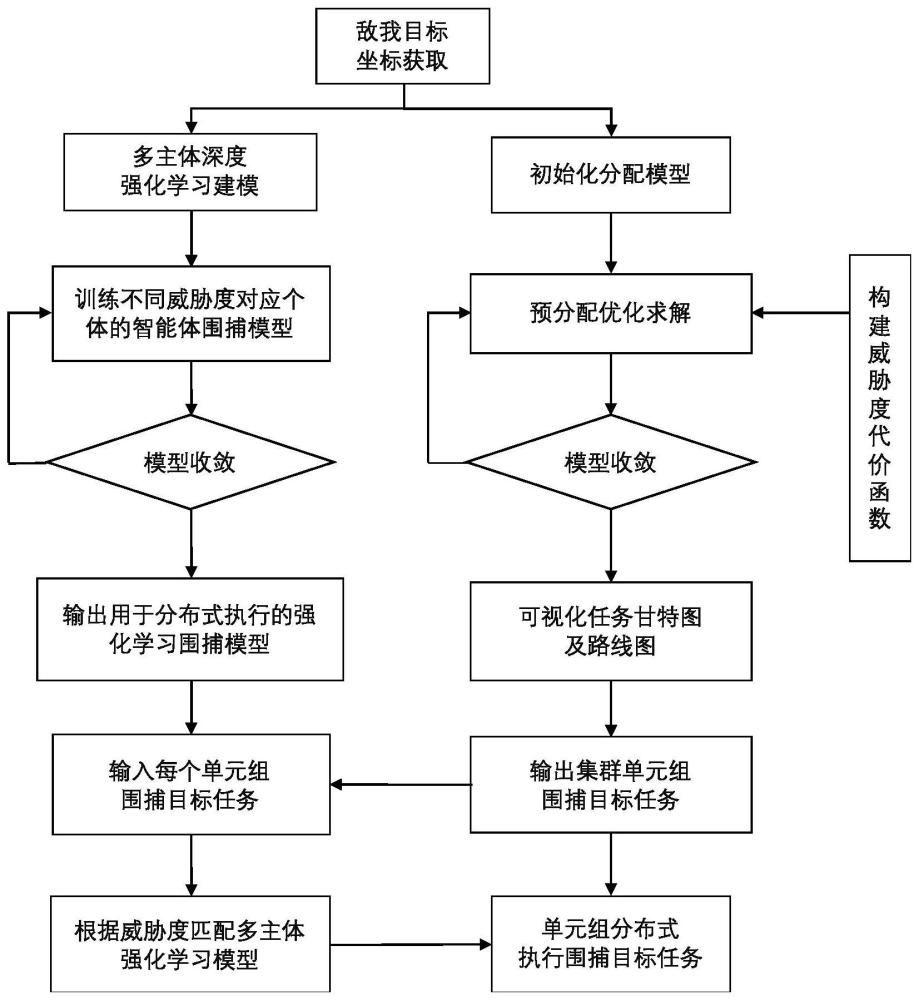
2、本发明解决技术的方案是:一种基于威胁度强化学习算法的多主体追逃最优策略方法,包括步骤:
3、步骤一:建立n个红方无人机组构成的红方集群,每个红方无人机组包括n个无人机,建立m个蓝方无人机组构成的蓝方集群;红方集群无人机根据感知信息获取蓝方集群无人机目标坐标;
4、步骤二:基于粒子群算法构建集群单元组的威胁度预分配模型,用于得到集群单元组任务及路线规划,初始化威胁度预分配模型参数,包括随机初始化粒子种群参数,初始化优化参数;
5、步骤三:根据任务要求构建威胁度目标函数,威胁度代价函数加入航迹代价、任务代价、威胁度代价因素;
6、步骤四:威胁度预分配模型算法训练求解,判断威胁度预分配模型是否收敛,若收敛执行步骤五,未收敛则继续根据代价计算更新粒子参数,重复步骤四;
7、步骤五:威胁度预分配模型收敛,得到集群单元组任务,包括以n个红方集群组成的多个单元组,对蓝方集群进行围捕分配的威胁度、路线轨迹以及任务时间序列,根据路线轨迹生成并可视化集群单元组任务路线图,根据任务时间序列生成并可视化任务甘特图,输出集群单元组任务;
8、步骤六:构建基于多主体深度强化学习的模型,用于执行每个集群单元组的围捕任务;
9、步骤七:集中式地训练不同威胁度对应个体的多主体深度强化学习模型,判断多主体深度强化学习模型是否收敛,检验围捕效果,若收敛,输出用于分布式执行的强化学习模型,执行步骤八,若不收敛,通过调整模型超参数及收敛条件继续训练直至收敛,进入步骤八,所述模型超参数包括收敛时长,迭代次数,经验回访次数;
10、步骤八:多主体深度强化学习模型以步骤五输出的集群单元组任务作为输入,根据单元组任务的威胁度值匹配多主体深度强化学习模型,每个无人机单元组中的每个无人机根据无人机单元组的目标任务威胁度值分布式运行匹配的多主体强化学习模型,进行无人机围捕任务。
11、进一步的,步骤一所述红方集群无人机根据感知信息获取蓝方集群无人机目标坐标包括:执行追踪围捕任务的红方集群无人机集gri,获取蓝方集群无人机目标坐标集gbi,以及对应的目标任务的威胁度集t(projecti),所述威胁度集为目标无人机的威胁度的集合,表示目标无人机的威胁程度,采用随机生成的方式赋予每个目标无人机的威胁度值,用于输入威胁度预分配模型,该过程包括的数据集合表示形式为:
12、<gri,gbi,t(projecti)>。
13、进一步的,步骤二所述随机初始化粒子种群参数,初始化优化参数,具体包括初始化粒子群中每个粒子的粒子适应度、粒子位置x及速度v、惯性因子ω参数。
14、进一步的,步骤三所述构建威胁度目标函数,具体包括:威胁度目标函数中威胁度代价根据集群组全部执行任务的威胁程度进行计算,航迹代价即无人机集群完成全部任务所需的总航程,任务代价根据无人机当前执行完成的任务数和未执行的任务数进行计算,取三者之和作为模型的目标函数j,并将min(j)作为优化目标来实现该综合指标的最小化,目标函数通过以下表达式表示:
15、
16、其中,μ1为目标代价函数中威胁度代价的权重比例,μ2为目标代价函数中航迹代价的权重比例,μ3为目标代价函数中任务代价的权重比例,t(projecti)为无人机组ai执行任务时对应任务的威胁度值,tmax(ai)表示无人机组ai的能够完成目标任务的最大威胁程度,l(projecti)为无人机组ai执行任务分配计划的飞行航程值,lmax(ai)表示无人机组ai的飞行航程上限,q为任务总数,nm(ai)表示无人机组ai完成任务的数量。
17、进一步的,步骤四所述根据代价计算更新粒子参数,更新规则通过以下表达式表示:
18、vid=ωvid+c1random(0,1)(pid-xid)+c2random(0,1)(pgd-xid)
19、xid=xid+vid
20、其中,vid表示粒子速度,i表示第i个粒子变量的个体;ω为惯性因子;c1和c2为加速常数,取c1=c2∈[0,4];pid表示第i个变量的个体极值的第d维;pgd为全局最优解的第d维,xid表示粒子的当前位置。
21、进一步的,步骤六所述构建多主体深度强化学习模型用于执行每个集群单元组的围捕任务,即用于每个集群单元组执行对应的任务集projecti,包括:将红方无人机组的每一个无人机称作一个智能体,对每个智能体构建两个神经网络,多智能体模型的训练涉及智能体动作及状态,该过程是马尔可夫博弈过程,涉及的数据集包括
22、<ai,e,{ui}i∈a,f,{ri}i∈a,γ>
23、其中,ai为每个无人机组智能体的集合,ai={a1,a2,...,an};e表示环境空间的观察信息集合,e=(o1,o2,...,on);{ui}i∈a表示无人机组智能体的全局动作集合空间(a1,a2,...,an);f:→[0,1]表示环境状态转移函数,训练阶段通过状态转移函数更新下一时刻整个空间的马尔可夫状态s;每个智能体的回报得分函数为ri:→[0,1],i∈a;γ表示累计奖励的折扣因子,用于后续计算每个智能体的总预期回报ri;
24、每一个智能体包含两个神经网络用于存储策略及评价信息,分别是策略网络和评价网络,策略网络和评价网络分别构建两个三层神经网络用于存储信息,神经网络隐含层节点个数均设为16;
25、评价网络用于训练过程中,评价网络输入环境及每个智能体全局信息,包括全局的观察信息集合(o1,o2,...,on)、全局动作信息集(a1,a2,...,an);策略网络用于存储多智能体训练过程策略,策略网络输入局部范围的观察信息集合,输出对应智能体的动作信息;智能体只根据评价网络给出的局部范围的观察信息来执行动作,在离线部署时根据经验回放执行动作。
26、策略网络和评价网络更新方式如下,神经网络中全连接层可以用以下公式来表示;
27、
28、其中,表示第l层的神经元j与第l+1层的神经元i的连接权重矩阵;表示第l层的第j个神经元;表示第l层的第j个神经元的偏置项;
29、使用限制后的线性单元relu作为非线性激活函数,相比于传统的双曲正切函数,使用relu可以显著的降低训练时间,激活函数如下计算,能够有效避免反向传播过程中,梯度消失的问题;
30、
31、其中,xi表示第i个特征图的输入,f(xi)表示第i个特征图的输出;
32、策略网络和评价网络的训练过程采用adam优化器进行训练,adam优化器可以针对不同的参数调整不同的学习速率,并以较小的步骤更新频繁变化的参数,优化调整模型权重;adam优化器通常对超参数的选择具有很强的鲁棒性,有助于神经网络参数的迭代更新。训练过程包括:
33、
34、st=β1st-1+(1-β1)gt
35、
36、
37、
38、其中,t表示时间步;gt表示t时刻的神经网络的梯度随机目标;表示优化器算法的初始化参数;β1,β2分别表示一阶,二阶矩估计的指数衰减速率;st,表示一阶矩向量及偏差;rt,表示二阶矩向量及偏差;
39、根据一阶和二阶矩向量的偏差修正量计算更新优化器算法的参数
40、
41、其中,δ是用于数值稳定的小常数,默认为10-8;η为算法步长,默认0.001。
42、进一步的,步骤七所述集中式地训练不同威胁度对应个体的多主体深度强化学习模型,包括:
43、多主体深度强化学习模型的求解是马尔可夫决策过程求解,通过基于值函数估计的直接策略梯度的方法计算状态和值;多智能体的联合策略集合,即所有智能体的动作行为为(a1,a2,...,an)表示多智能体的全局动作集合空间,x为环境因素,即观察信息集合x组成为x=(o1,o2,...,on),多智能体的联合策略值的集合定义为即πi=oi×ai;多智能体的随机变量的期望用下式表示:
44、
45、
46、其中,参数化θ用于来近似估计值,ri为所有智能体的回报得分,t为整个训练时间;
47、多智能体策略梯度可以用下式表达:
48、
49、其中,pμ为状态分布,s是整个空间的马尔科夫状态;智能体的确定性策略为μi;
50、多智能体策略梯度转换成可以计算的公式为:
51、
52、其中,μi为智能体的确定性策略,更新方法由下式所得:
53、
54、其中y由下式计算得出:
55、
56、目标网络用于存储多智能体的联合策略集,算法收敛后通过目标网络及环境信息,求解得出智能体动作信息ai。多主体深度强化学习模型在线下集中式培训,当模型收敛后保存网络部署在智能体上,在线上分布式地执行输出智能体的动作。
57、本发明与现有技术相比的有益效果是:
58、本发明通过构建威胁度预分配算法,提出根据敌方目标威胁程度、航迹距离、任务数量指标构建威胁度目标函数用于指导优化集群目标预分配,生成集群单元组的任务甘特图及任务路线图并输出集群单元组任务,用于后续匹配相应威胁度目标的围捕模型。预训练了基于多主体深度强化学习算法的不同数量多架次无人机围捕目标无人机的模型,多主体深度强化学习算法匹配威胁度值执行每个单元组的围捕任务,智能体分布式执行处理无人机集群单元组任务,执行速度实时高效,解决了模型训练效率低下、以及由于集群无人机对抗围捕任务中由于智能体数量上升导致状态空间呈指数上升带来的模型收敛困难问题。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199612.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表