一种基于强化学习的水陆两栖六足机器人运动控制方法
- 国知局
- 2024-08-01 00:06:34
本发明涉及机器人,具体为一种基于强化学习的水陆两栖六足机器人运动控制方法。
背景技术:
1、两栖机器人是一种用于水陆两栖作业的机器人,两栖六足机器人是腿式两栖机器人中的一种,其采用了六足推进系统的驱动结构,相对于其他仿生两栖机器人具有更好的实际环境适应能力。在现有技术中,两栖六足机器人在陆地上采用近端策略优化(proximalpolicy optimization,ppo)算法训练爬行步态,为机器人在不同崎岖地形下的运动提供控制策略;针对水下三维空间的运动控制问题,通过视线法与pid控制器结合,将其分解为水平面上的轨迹跟踪和垂直方向上的深度控制问题。上述方法存在以下缺陷:一是在陆地环境中训练较慢,且改变陆地地形时需重新开始训练,先前训练得到的策略没有很好地利用;二是ppo算法输出的是一个动作的概率分布,在六足机器人的运动过程中,动作合集是连续值,动作的空间维度极大,若使用随机策略,无法对所有动作的概率进行研究,并计算各个可能的动作的价值;三是水下环境中是将三维运动分解成平面与竖直两个方向的运动,没能很好发挥机器人的运动性能,与此同时控制方法采用的是视线法与pid控制器结合,与陆地上的控制方法没有很好的相关性,并且存在控制律设计复杂、参数配置难度大的问题。
技术实现思路
1、本发明的目的在于提供一种基于强化学习的水陆两栖六足机器人运动控制方法,以解决上述背景技术中提出的问题。
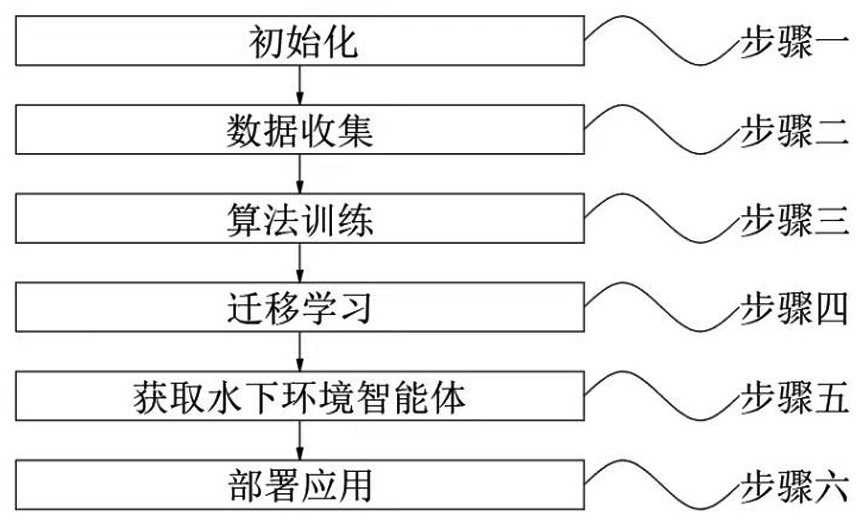
2、为实现上述目的,本发明提供如下技术方案:一种基于强化学习的水陆两栖六足机器人运动控制方法,包括以下步骤:步骤一,初始化;步骤二,数据收集;步骤三,算法训练;步骤四,迁移学习;步骤五,获取水下环境智能体;步骤六,部署应用;
3、其中在上述步骤一中,将两栖六足机器人三维模型转换成机器人统一的描述格式文件(unified robot description format,urdf)并导入平地仿真环境,设置机器人组件的外形参数和物理特性,搭建机器人与地面的碰撞与受力机制,初始化td3算法(twindelayed deep deterministic policy gradient,双延迟深度确定性策略梯度算法);
4、其中在上述步骤二中,使用actor网络与平地仿真环境进行交互,收集经验数据,并存储这些经验数据到经验回收池r中;
5、其中在上述步骤三中,从步骤二中的经验回收r中提取小批量经验数据组来训练actor网络和两个critic网络,计算两个评估器之间的梯度,并更新网络参数,重复训练直至算法奖励收敛,得到具备在平地环境中进行自主决策能力和行动能力的智能体;
6、其中在上述步骤四中,采用迁移学习,以步骤三中得到的具备在平地环境中进行自主决策能力和行动能力的智能体作为预训练模型,导入到深度强化学习框架tensorflow中,设置不同地形的仿真环境以代替平地仿真环境,重新执行步骤一至步骤三,得到具备在不同地形环境中进行自主决策能力和行动能力的智能体;
7、其中在上述步骤五中,将步骤一和步骤二中的平地仿真环境更改为水下仿真环境,重新执行步骤一至步骤三,得到具备在水下环境中进行自主决策能力和行动能力的智能体;
8、其中在上述步骤六中,将步骤三、步骤四和步骤五训练好的智能体部署到水陆两栖六足机器人上,进行陆地和水下环境中的运动控制。
9、优选的,所述步骤一中,外形参数和物理特性包括颜色形状、尺寸大小、相对坐标、质量参数和碰撞系数,以及机器人各个运动关节相关的运动学和动力学参数,具体包括关节运动的角度限制和速度限制。
10、优选的,所述步骤一中,td3算法包括一个动作策略网络actor和两个结构一致的目标动作评估网络critic1和critic2,actor网络和critic网络中均增设有gru层(gaterecurrent unit);actor网络两个全连接层的神经元个数分别是400与300,gru网络的神经元个数是128,陆地环境中机器人所需的关节控制信号为18个,因此actor网络输出层的神经元个数是18;critic网络第一个全连接层的神经元个数是400,剩余两个全连接层的神经元个数均为300,gru网络神经元个数是128,输出为q值;actor网络与critic网络中所有全连接层后都有relu激活函数。
11、优选的,所述步骤一中,所述步骤一中,初始化td3算法具体为:随机初始化actor网络参数以及critic网络参数和,运用和初始化actor和critic目标网络参数,初始化经验回收池r。
12、优选的,所述步骤二中,具体为:actor网络将机器人当前所处的环境状态作为输入,根据当前策略和探索率选择一个动作,执行动作并返回动作奖励和新状态,存储经验数据到经验回收池r。
13、优选的,所述环境状态为由每一采样时刻下机器人机身状态、各条关节速度与角速度和机器人足端与地面的接触信息组成,机身状态包括机身位置、速度与偏航角;动作为驱动各条运动肢动作的18个关节转矩;奖励函数中包含有相关运动性能参数,具体包括机器人直行速度与朝向、行走稳定性、关节能耗、机器人质心在水平与竖直方向的偏移。
14、优选的,所述奖励函数具体为:
15、
16、式中表示机器人直行速度;和分别是环境的采样时间和最终模拟时间;表示机器人行走稳定性;为机器人在方向的偏移量;是躯干重心与理想高度的误差;为机身偏航角;是上一个时间步长中关节i的动作值;为常系数项。
17、优选的,所述步骤三中,两个critic网络通过递归贝尔曼方程同时更新,具体的更新公式如下所示:
18、
19、为了逼近最优q函数,采用均方贝尔曼误差函数用于表示参数和满足贝尔曼方程的程度,具体如下所示:
20、
21、在td3中,使用两套网络(twin)表示不同的q值,通过选取最小的那个作为更新的目标(target q-value),此外,在目标网络估计expected return部分,对policy网络引入随机噪声,以避免在q值的窄峰上出现过度拟合,采用高斯噪声,并通过以下公式对critic网络进行更新:
22、。
23、优选的,所述步骤三中,actor网络将在critic网络更新d次以后才更新,以减少由时间差分学习引起的累积误差,actor网络采用下式所示的期望回报的梯度上升来更新:
24、
25、actor和critic目标网络采用下式更新:
26、
27、其中,为远小于1的超参数。
28、优选的,所述步骤五中,水下仿真环境中,需要在质心处施加水动力学部分的外力,具体包括惯性矩阵、科里奥利力以及阻尼矩阵;同时修改观测量、终止条件以及奖励函数,在奖励函数中加入机器人运动轨迹与期望轨迹的误差;动作为驱动各条运动肢动作的18个关节转矩,以及6个喷水电机在足端产生的推力大小;水下环境中机器人所需的关节控制信号为24个。
29、与现有技术相比,本发明的有益效果是:本发明对机器人陆地与水下的运动控制均采用td3算法,解决了现有ppo算法存在的缺陷,同时也解决了水下环境中采用常规方法造成的控制律设计复杂、参数配置难度大的问题,并且通过在td3算法中加入gru网络,加快了训练速度与奖励收敛,本发明将在平地环境中训练得到的良好行走策略作为预训练模型,采用迁移学习将该模型应用在不同地形环境进行相应的训练,以此获取能够用于不同地形环境的模型,有效提高了训练效率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199713.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表