一种基于轨迹自修正控制双足机器人运动的强化学习方法及程序产品
- 国知局
- 2024-08-01 00:18:24
本发明属于机器人运动控制领域,涉及一种基于轨迹自修正控制双足机器人运动的强化学习方法。
背景技术:
1、如何在更短的时间内学习最优策略去控制双足机器人的运动是具有挑战性的控制问题。该问题可以将双足机器人的运动建模为马尔可夫决策过程,然后采用强化学习的策略优化算法求解。
2、基于模型的强化学习是强化学习的一种方法,其中智能体试图学习环境模型,然后利用该模型进行决策和学习。智能体通常直接与环境交互,并通过试错的方式学习最优的策略。基于模型的强化学习则引入了一个环境模型,利用该引入的模型可以产生模拟的样本,减少算法对于样本的需求。基于模型的强化学习的优势在于可以更有效地利用环境信息来进行决策,从而提高学习效率。
3、尽管利用现有的基于模型的强化学习方法能对双足机器人的运动策略进行求解,但是该方法对于模型的精确性较为敏感,当模型不精确时,利用该模型产生的样本将包含极大误差,利用该有误差的模拟样本来学习策略会减缓策略的学习速度,严重时引起策略的发散。另一方面,在真实环境中,样本的获取往往具有较大的获取代价。因此,如何能在仅利用少量真实样本的情况下,就能学习到一个精确的模型,并利用该模型来促进策略的学习,是目前急需解决的问题。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,提供一种基于轨迹自修正控制双足机器人运动的强化学习方法,解决真实样本数量较少时,促进策略快速学习的问题。
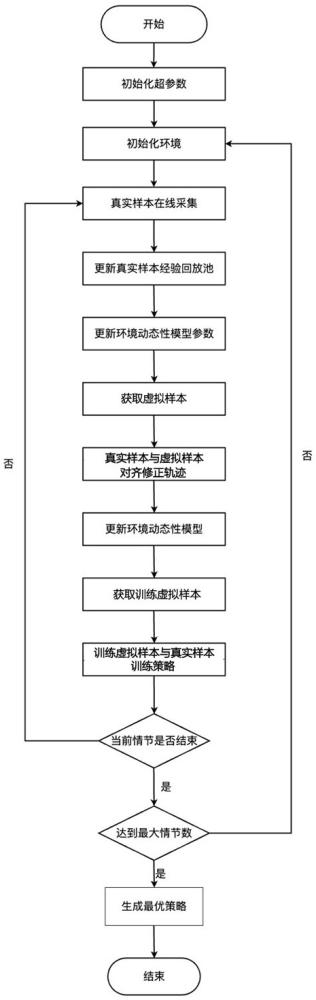
2、为实现上述目的,本发明技术方案如下:一种基于轨迹自修正控制双足机器人运动的强化学习方法,包括如下步骤:
3、步骤1:初始化机器人动作策略模型和环境动态性模型的参数,所述环境动态性模型的输入为机器人的状态维度和动作维度,所述环境动态性模型的输出为机器人的下一个状态的状态维度和奖励维度;
4、步骤2:设置当前时间步t=0,从初始状态分布p(s0)中采样初始状态s0;
5、步骤3:真实样本在线采样:在状态st处根据机器人动作策略模型输出动作at,机器人执行动作at后得到状态st+1和奖励rt+1,得到真实样本(st,at,st+1,rt+1);
6、步骤4:将真实样本(st,at,st+1,rt+1)插入真实样本经验回放池中更新真实样本经验回放池,更新当前状态st=st+1;
7、步骤5:采用真实样本经验回放池中的样本更新环境动态性模型的参数;
8、步骤6:从真实样本池中随机选取一个样本的状态和轨迹动作输入环境动态性模型得到虚拟状态和虚拟奖励,构建虚拟样本集合;
9、步骤7:将虚拟样本集合中的虚拟样本与对应的真实样本池中的真实样本对齐,构建对齐虚拟样本集合;
10、步骤8:采用真实样本池中的真实样本和对齐虚拟样本集合中的虚拟样本更新环境动态性模型的参数;
11、步骤9:从初始状态开始,根据机器人动作策略模型产生当前动作,并输入环境动态性模型得到下一状态和奖励,构建训练虚拟样本集合;
12、步骤10:取出真实样本池中的真实样本和训练虚拟样本集合中的训练虚拟样本更新机器人动作策略模型参数;
13、步骤11:重复步骤3至步骤10至当前时间步达到最大值后进入步骤12;
14、步骤12:重复步骤2至步骤11至最大迭代次数后进入步骤13;
15、步骤13:基于状态st由更新后的机器人动作策略模型输出动作at。
16、本发明方案在环境动态性模型学习阶段,首先利用其构造多步的虚拟样本轨迹。对齐虚拟样本集合和真实样本经验回放池中的真实样本用于进一步训练环境动态性模型,从而实现其高效的学习。在策略训练阶段,则直接利用真实样本经验回放池中的真实样本和环境动态性模型产生的训练虚拟样本集中的虚拟样本,共同实现对策略的训练,从而在仅需少量真实样本的情况下,实现策略的快速收敛。
17、进一步地,所述步骤6构建虚拟样本集合时,从真实样本池中随机选取一个样本sk作为初始状态和从sk对应的动作ak起始的h个动作{ak,ak+1,ak+2,…,ak+h-1},h为采样轨迹的长度,从初始状态st′=sk出发,根据当前动作a′t=ak,将状态st′和动作a′t输入环境动态性模型tω得到虚拟状态st′+1和和虚拟奖励rt′+1=tω(st′,a′t),令a′t+1=ak+1,将虚拟状态st′+1和动作a′t+1输入环境动态性模型tω得到下一个虚拟状态st′+2和虚拟奖励rt′+2=tω(st′+1,a′t+1),重复至得到虚拟状态st′+h和虚拟奖励rt′+h,虚拟样本集合为{(st′,a′t,rt′+1,st′+1),(st′+1,a′t+1,rt′+2,st′+2),…,(st′+h-1,a′t+h-1,rt′+h,st′+h)}。
18、进一步地,所述步骤7中将虚拟样本集合中的虚拟样本与对应的真实样本池中的真实样本对齐时,所述虚拟样本集合对应的真实样本合集为{(sk,ak,rk+1,sk+1),(sk+1,ak+1,rk+2,sk+2),…,(sk+h-1,ak+h-1,rk+h,sk+h)},对齐后的虚拟样本集合为{(s′k,a′k,rk+1,sk+1),(s′k+1,a′k+1,rk+2,sk+2),…,(s′k+h-1,a′k+h-1,rk+h,sk+h)},计算每个配对的真实样本和对齐的虚拟样本的状态之间的欧式距离d,当欧式距离大于某预设的阈值d0时,则抛弃该对齐的虚拟样本,否则,将该对齐的虚拟样本加入对齐虚拟样本集合中,d0的值为上一轮迭代中的所有配对的真实样本和对齐的虚拟样本的误差的均值。
19、为避免复合误差,将虚拟样本轨迹与真实样本轨迹对齐,采用欧式距离来对对齐后的样本的误差进行判断,当阈值小于预设值时,才将虚拟样本加入对齐虚拟样本集合中。
20、进一步地,所述步骤9中构建训练虚拟样本集合时,从初始状态s′t=s0出发,由机器人动作策略模型πθ产生当前动作a′t=πθ(s′t),将状态s′t和动作a′t输入环境动态性模型tω得到状态s′t+1和奖励r′t+1=tω(s′t,a′t),令a′t+1=πθ(s′t),将状态s′t+1和动作a′t+1输入环境动态性模型tω得到下一个状态s′t+2和奖励r′t+2=tω(s′t+1,a′t+1),重复至得到下一状态s′t+h和奖励r′t+h,训练虚拟样本集合为{(s′t,a′t,r′t+1,s′t+1),(s′t+1,a′t+1,r′t+2,s′t+2),…,(s′t+h-1,a′t+h-1,r′t+h,s′t+h)}。
21、进一步地,所述步骤5和步骤8中更新环境动态性模型的参数是以梯度下降算法更新,环境动态性模型的参数为环境动态性模型的损失函数l(ω)对参数ω的梯度,α2为学习率。
22、进一步地,所述环境动态性模型为三层全连接层所构成的概率神经网络,损失函数
23、
24、st为t时刻的状态,at为t时刻的动作,st+1为下一个时刻的状态,μω(st,at)为下一个时刻的状态的均值,为下一个时刻的状态的方差,环境动态性模型的输出为
25、进一步地,所述步骤10更新机器人动作策略模型参数是以梯度下降算法更新,机器人动作策略模型的参数为机器人动作策略模型的损失函数l(θ)对参数θ的梯度,α1为学习率。
26、进一步地,所述机器人动作策略模型的损失函数
27、
28、dkl表示kl散度计算,q表示动作值函数,v表示状态指函数。
29、进一步地,所述步骤4中将真实样本(st,at,st+1,rt+1)插入真实样本经验回放池中更新真实样本经验回放池时,当真实样本经验回放池中的样本数量小于允许的最大数量m时直接添加,否则将真实样本(st,at,st+1,rt+1)替代最早加入真实样本经验回放池中的样本。
30、本发明还提供一种计算机程序产品,包括计算机程序或计算机可执行指令,所述计算机程序或计算机可执行指令被处理器执行时,实现前述的基于轨迹自修正控制双足机器人运动的强化学习方法。
31、本发明与现有技术相比的优点在于:(1)仅利用少量真实样本和环境动态性模型产生的模拟样本进行对齐,即可学习到一个更加精确的环境动态性模型,对真实样本的需求量小,降低了双足机器人的环境动态性模型的学习成本;(2)采用轨迹自纠正的方法可以将模型产生的带有误差的模拟轨迹用真实轨迹样本进行对齐纠正,利用纠正的样本再对环境动态性模型进行修正,从而提高环境动态性模型的精确度,可以让策略学习的模拟样本更加接近于真实样本,缓解由于环境动态性模型带来的累积误差,避免由于不准确的模拟样本误导策略的学习,加速策略的学习提高了双足机器人策略学习的样本效率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200529.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表