基于忆阻器的非易失SRAM存内计算电路、阵列和方法
- 国知局
- 2024-07-31 19:18:25
本发明实例涉及电路设计领域,尤其涉及一种基于忆阻器的非易失性sram存内计算电路、阵列和方法。
背景技术:
1、目前,神经网络等数据密集型应用正在逐渐兴起,并被广泛地应用在人们日常生活中的诸多领域。然而,在传统冯诺依曼架构下,计算单元和存储单元的分离会导致在执行此类数据密集型和计算密集型任务时,在数据搬移上产生海量的能耗和延时开销,因此造成的问题被称为内存墙问题。
2、近来,多种非易失性静态随机存储器(non-volatile sram,nvsram)单元结构被提出,这种电路结构能够将数据存储在阻变存储器(resistive random access memory,reram)等非易失存储单元中,在需要使用的时候再将其恢复至sram单元中。
3、同时,基于静态随机存储器(sram)的存内运算(compute-in-memory,cim)架构的神经网络加速器被提出用来解决传统计算架构中面临的内存墙问题。这类新型神经网络加速器能够高能效、低延时地完成数据密集型的应用,因此被广泛地部署到资源受限的边缘端。然而在sram cim中,由于sram单元面积较大,在有限的片上资源下能够存储的神经网络权值十分有限,无法将大规模神经网络权值完整地存储在片上,导致在执行神经网络时仍然需要在数据存储单元和加速器之间进行大量的数据传输,使神经网络计算能耗大大增加。另外,多种基于reram交叉阵列的神经网络加速器也被提出。这类新型神经网络加速器能够高密度地存储数据,大大减少数据搬移。此类加速器在进行计算时,通过基尔霍夫电流定律实现乘累加,这种存算机制在进行计算时存在直流通路,导致电路整体功耗较高;同时,reram器件会受到权值扰动的影响,使得reram器件实际阻值偏离理想值,使计算结果出现误差,降低神经网络精度。
4、因此,如何实现对大规模神经网络权值的高密度存储和高能效高精度的神经网络加速是当前神经网络加速器面临的一个重要挑战。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于忆阻器的非易失性sram单元电路、阵列、映射和加速方法。
2、根据本发明的一个方面,提供一种利用reram器件进行数据存储的nvsram-cim单元电路,包括:
3、sram存储单元,所述sram存储单元包括6管sram存储单元和一个控制管;
4、reram数据存储电路,所述reram数据存储电路与所述sram存储单元的q节点连接;
5、所述sram存储单元中的权值存储至所述reram数据存储电路中;
6、所述reram数据存储电路中存储的权值恢复至所述sram存储单元中;
7、利用所述sram存储单元中的权值进行存内计算。
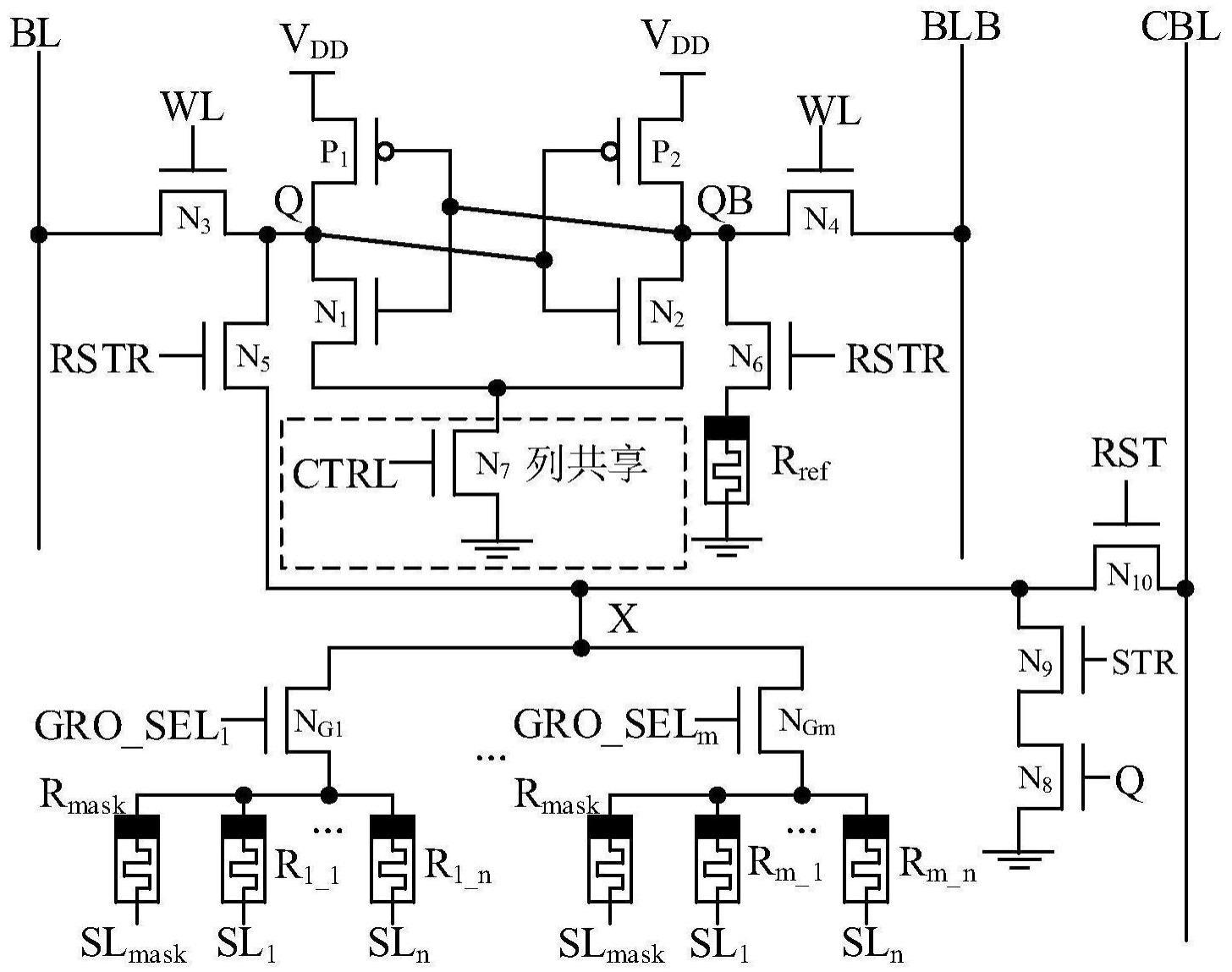
8、优选地,所述sram存储单元共包含7个晶体管,其中5个nmos管记为n1~n4、n7,2个pmos管记为p1~p2;
9、所述p1和n1组成一个反相器,所述p2和n2构成另一个反相器,所述两个反相器交叉耦合形成反相器环,作为数据存储模块;
10、所述n3和n4管为传输管,将所述sram存储单元的数据存储节点q和qb,分别与位线bl、反位线blb连接,由字线wl控制,完成数据的读写;
11、所述n7管为在6管sram单元底部添加一个列共享的控制管。
12、优选地,所述reram数据存储电路包括若干个被分成多个组的reram器件,第i组reram中的第j个reram器件记为ri_j,同一组的reram器件由同一个nmos管ngi控制;
13、在选定特定的reram器件ri_j时,通过ngi管对reram所在的第i组进行选择;
14、再通过slj对第i组中的第j个reram器件进行选择。
15、根据本发明的第二个方面,提供一种基于nvsram-cim单元的存内运算子阵列,包括由所述的nvsram-cim存算电路构成的阵列,所述阵列尺寸与神经网络尺寸适配;还包括预充电结构、输入信号译码器、阵列信号控制器、adc和s&a电路;
16、所述神经网络权值存储在所述阵列nvsram-cim存算电路的每个sram单元连接的reram器件中。
17、输入信号根据输入信号译码器结果按行输入到所述阵列中;
18、计算结果按列输出到对应的所述adc中;
19、通过移位加法器得到最后的乘累加结果。
20、根据本发明的第三个方面,提供一种神经网络权值的映射方法,将神经网络权值映射到所述的一种基于nvsram-cim单元的存内运算子阵列上。
21、优选地,包括:
22、将一层神经网络转化为一个r行c列的矩阵,r=cx×k×k,c=mx×q,其中cx为输入通道数,k为卷积核尺寸,mx为输出通道数,q为权值量化位数;
23、将权值划分为多个块,每个权值块的尺寸为单个nvsram-cim存算子阵列中同时能够开启并进行存内运算的尺寸,并将各个块尽平均地分配到各个存算子阵列;
24、在各个存算子阵列中上一层网络权值写入的末尾,将各个权值块写入。
25、优选地,同一权值的不同比特被存储在同一行中的不同的nvsram-cim单元中;同一权值被存储在各个nvsram-cim单元中相同的位置。
26、根据本发明的第四个方面,提供一种神经网络加速方法,通过对神经网络权值进行复制并写入到不同的所述的一种基于nvsram-cim单元的存内运算子阵列上。
27、优选地,所述神经网络中的矩阵乘法计算被分配到各个存内运算子阵列中,利用所有存算子阵列的计算资源,实现神经网络运行提速。
28、与现有技术相比,本发明具有如下的有益效果:
29、本发明实施例中的一种利用reram器件进行数据存储的nvsram-cim单元电路以及根据神经网络的应用需求构建的nvsram-cim阵列,利用nvsram存内运算机制,实现高能效的神经网络运行;将神经网络的权值存储在阵列内的reram器件中,可以实现对大规模神经网络权值的高密度存储和阵列级并行的神经网络权值载入,避免了从片外对权值进行读取,降低数据搬运的功耗,进而提高神经网络加速器的能效;同时,提出了神经网络权值映射方法对网络权值进行映射,提高硬件的资源利用率。
技术特征:1.一种利用reram器件进行数据存储的nvsram-cim单元电路,其特征在于,包括:
2.根据权利要求1所述的一种利用reram器件进行数据存储的nvsram-cim单元电路,其特征在于,所述sram存储单元共包含7个晶体管,其中5个nmos管记为n1~n4、n7,2个pmos管记为p1~p2;
3.根据权利要求1所述的一种利用reram器件进行数据存储的nvsram-cim单元电路,其特征在于,所述reram数据存储电路包括若干个被分成多个组的reram器件,第i组reram中的第j个reram器件记为ri_j,同一组的reram器件由同一个nmos管ngi控制,每一组中的第j个reram器件对应一个信号slj;
4.一种基于nvsram-cim单元的存内运算子阵列,其特征在于,包括由权利要求1-3任一项所述的nvsram-cim单元电路构成的阵列,所述阵列尺寸与需进行权值存储的神经网络尺寸适配;还包括预充电结构、输入信号译码器、阵列信号控制器、adc和s&a;
5.一种神经网络权值的映射方法,其特征在于,将神经网络权值映射到权利要求4所述的一种基于nvsram-cim单元的存内运算子阵列上。
6.根据权利要求5所述的一种神经网络权值的映射方法,其特征在于,权值映射从所述神经网络的第一层开始,逐层进行。
7.根据权利要求5所述一种神经网络权值的映射方法,其特征在于,包括:
8.根据权利要求5所述的一种神经网络权值的映射方法,其特征在于,
9.一种神经网络加速方法,其特征在于,通过对神经网络权值进行复制并写入到不同的如权利要求4所述的一种基于nvsram-cim单元的存内运算子阵列上。
10.根据权利要求5-8所述的神经网络映射方法或权利要求9所述的神经网络加速方法,其特征在于,所述神经网络中的矩阵乘法计算被分配到各个存内运算子阵列中,利用所有存算子阵列的计算资源,提速神经网络运行。
技术总结本发明提供一种利用ReRAM器件进行数据存储的nvSRAM‑CIM单元电路,包括:SRAM存储单元,SRAM存储单元包括6管SRAM存储单元和一个控制管;ReRAM数据存储电路,ReRAM数据存储电路与SRAM存储单元的Q节点连接;SRAM存储单元中的权值存储至ReRAM数据存储电路中;ReRAM数据存储电路中存储的权值恢复至SRAM存储单元中;利用SRAM存储单元中的权值进行存内计算。本发明实现高能效的神经网络运行;将神经网络的权值存储在阵列内的ReRAM器件中,可以实现对大规模神经网络权值的高密度存储和阵列级并行的神经网络权值载入,避免了从片外对权值进行读取,降低数据搬运的功耗,进而提高神经网络加速器的能效;同时,提出了神经网络权值映射方法对网络权值进行映射,提高硬件的资源利用率。技术研发人员:孙亚男,李学清,何卫锋,徐浏凯,刘松原,李智,汪登峰,毛志刚受保护的技术使用者:上海交通大学技术研发日:技术公布日:2024/1/16本文地址:https://www.jishuxx.com/zhuanli/20240731/182286.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表