一种基于文本增强与双通道三元组抽取的电力知识图谱构建方法与流程
- 国知局
- 2024-08-22 14:50:34
本发明涉及数据处理,具体为一种基于文本增强与双通道三元组抽取的电力知识图谱构建方法。
背景技术:
1、随着电力领域的发展不断加快,电力企业也产生了越来越多的数据,包括工业运营、系统维护、项目管理等。对于电力企业的管理人员来说,如何有效的利用海量的业务数据更好地决策已成为一项具有挑战性的任务。与项目管理相关的业务数据包括存储在关系数据库中的结构化关系数据,以及归档在报告、会议通知、计划文件、项目进度文件等中的非结构化数据。随着项目管理数据的增多,如何处理这些多源且可能异构的数据已成为一个具有挑战性的问题。
2、近年来,知识图谱(kg)在电力行业的知识分类、共享和决策制定方面发挥了至关重要的作用。知识图谱受到了广泛的关注,并在金融、法律、军事等领域也得到了广泛的应用。在电力工业领域,生成的电力数据主要是复杂的非结构化数据,给电力数据的管理带来一定的困难。因此,知识图谱提供了一种很好地处理非结构化数据的可行方法。一般来说,自然语言处理中的命名实体识别、关系提取等知识图谱相关技术可以从非结构化电力项目管理数据中提取实体及其之间的关系,并且也可以基于这些技术构建用于电力项目管理的知识图谱。
3、然而,虽然构建知识图谱最关键就是实体关系抽取,但目前对其的研究大多集中在实体和关系的联合抽取上。由于实体和关系各自的上下文信息差异很大,现有的联合提取方法往往会受到两者造成的信息噪声的影响,这可能会显著影响整个模型的性能,导致提取关系的效率较低。
技术实现思路
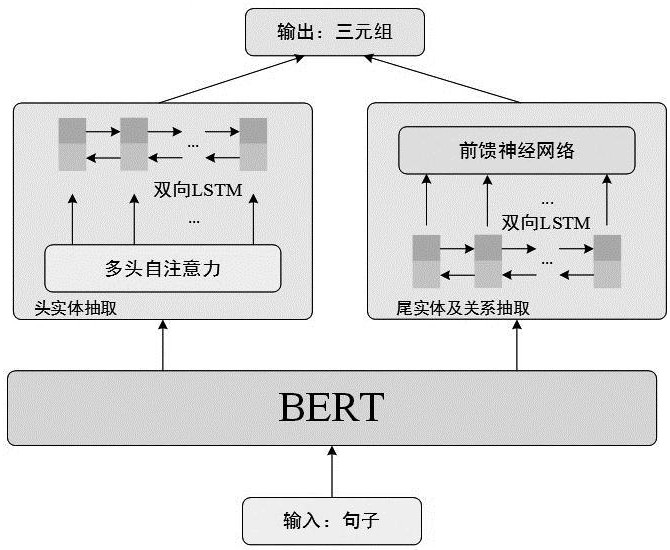
1、针对上述存在的技术不足,本发明的目的是提供一种基于文本增强与双通道三元组抽取的电力知识图谱构建方法,其对于输入句子中的每一个词,都先对其在外部知识图谱上进行搜索,并将相关三元组嵌入词嵌入中,随后通过两个不同的通道分别进行头实体的抽取与尾实体和关系的抽取。
2、为解决上述技术问题,本发明采用如下技术方案:
3、本发明提供一种基于文本增强与双通道三元组抽取的电力知识图谱构建方法,包括以下内容:
4、1.数据预处理;
5、首先,对电力项目管理非结构化文档的原始数据进行了去重处理,消除由于系统重复记录引起的冗余信息,进行缺失值的处理,采用适当的填充或删除策略,确保数据集的完整性;其次,对文本信息的字段进行预处理,利用bert工具识别关键实体,为模型提供了明确的实体边界,进而对文本中存在的关系进行人工标注,构建模型训练数据集用于后续的细粒度的实体和关系抽取。
6、2.文本表示增强的预训练模型;
7、对于一个句子长度为l的句子x,首先在谷歌知识图谱中对每个token进行查询,如果能够查询到,则将其相关三元组嵌入为向量;对于一个三元组(h,r,t),表示实体嵌入,表示关系嵌入;对于某个特定的关系r,所有的实体对(h,t)通过聚类的方式分成多组,并且每一组中的实体对都应该表现出类似的关系r;为了进行聚类,被用来表示所有的实体对(h,t);mr是某个关系所学习到的映射矩阵,是某个聚类学习到的一个单独的关系向量;实体的映射向量为:
8、
9、得分函数为:
10、
11、其中的目的是保持特定簇的关系向量与原始关系向量的距离保持一定距离,α的作用则是控制这种约束效果;
12、在得到某个token的相关三元组嵌入成的向量后,将其拼接(concat)到tokenembedding后:
13、ete=concat(eote,et) (3)
14、其中ete表示拼接后所得到token embedding,eote表示原本的token embedding,et表示相关三元组;
15、再通过pca算法对ete进行降维操作,使其降为768维,接着将降维后的tokenembedding与segmentation embeddings和position embeddings加和作为bert的输入并将其送入bert中进行下一步操作;
16、3.基于多通道的三元组抽取模型;
17、3.1基于多头注意力机制的头实体抽取;
18、考虑到表示文本序列的特征集合s=[s1,s2,...sn],其中每个si表示bert编码器对应于句子中的特定位置的隐藏表示,且这里n是句子长度,d是嵌入维数;bert编码器的输出经过多头自注意力层的处理;多头自注意力层的计算公式如下(4)(5)所示:
19、headl=attention(qwlq,kwlk,vwlv) (4)
20、multihead=concat(head1,head2,...,headl)w0 (5)
21、其中矩阵k、q和v的来源是特征矩阵s,而wlq、wlk、wlv和w0则是可训练的权重,其中l代表多头自注意力的头数;将输出表示为m=[m1,m2,…,mn],这里n是句子中的词数;接下来,将m输入到双向长短期记忆网络(bi-directional long short-term memory,bi-lstm)中进行编码;bi-lstm根据之前的隐藏状态hi-1、记忆单元ci-1和当前的词向量mi,计算出当前正向lstm的输出和反向lstm的输出bilstm的详细计算公式见(6)和(7);
22、
23、将正向lstm的输出和反向lstm的输出连接起来,形成mi的序列级表示;这一表示用公式(8)表示:
24、
25、bi-lstm的最终输出是其中每个表示计算句子中每个词的隐藏状态;接着从bi-lstm的输出中选择相应的词向量,并对其进行最大池化操作,随后通过线性层进行分类;最大池化和线性分类的计算公式如下(9)(10)所示:
26、
27、enti=weei+be (10)
28、其和代表边界标记的上下文表示,和是可训练的权重,d是词向量的维数,ne是标签集的大小;
29、3.2基于前馈神经网络的尾实体和关系抽取;
30、由于两个通道之间的信息可能相互影响,所以将它们划分为两个独立的通道,均使用bert编码器的特征表示;通过将bert编码器的特征输入到bi-lstm中,有助于学习句子中更多的上下文特征表示;对于向量化的标记ri,通过连接正向lstm输出和反向lstm输出的特征,得到最终的隐藏状态其计算公式如式(11)所示:
31、
32、因此,bi-lstm的最终输出被表示为其是第i个词项的隐藏状态,n是句子的长度;接着,在bi-lstm之后引入前馈神经网络(feedforward neuralnetwork,fnn),并采用relu作为激活函数;fnn的计算公式见式(12);
33、re=relu(whr+b) (12)
34、其中,和表示可训练的权重。接着获取fnn特征表示并进行最大池化操作;最终,通过线性层对候选关系类型进行预测;具体的数学公式见式(13)和式(14)。
35、
36、reluti=wrti+br (14)
37、其中和分别代表边界词的上下文表示,而和则表示可训练的权重;其中,d是词向量的维数,nr是关系类型的数量;
38、为了使两个通道能够学习bert编码器的特征,为它们设置了不同的学习率;采用交叉熵损失作为两个通道的损失函数,损失函数为公式(15)(16)(17):
39、
40、l=lent+lrel (17)
41、其中k是实体类型的数量,lreal是候选实体的真实值,n是关系类型的数量,treal是候选关系的真标签。
42、本发明的有益效果在于:本发明方法预训练模型采用bert模型,并将bert输入中的词嵌入拼接上外部知识;随后,实体关系抽取模型主要在实体解码阶段抽取实体集,然后在关系集预测网络阶段融合较优者的解码结果,抽取数据中的关系三元组。通过联合解码,实体类型能为关系抽取提供重要信息从而得到实体和关系的准确预测,避免了错误传播并解决冗余和泛化性差等问题。本方法相比于当前最新的主流方法具备较高的精确率与f1值,整体性能优秀。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280084.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表