一种以对称理论为基础的联邦学习参与方选择方法
- 国知局
- 2024-09-05 14:54:52
本发明涉及数据处理,特别涉及一种以对称理论为基础的联邦学习参与方选择方法。
背景技术:
1、作为人工智能的重要分支领域,机器学习被应用于智能交通、金融分析、推荐系统、智慧医疗等领域并取得了一定的成果。然而,在主流机器学习模型训练与使用中,数据一直面临着泄露的风险,对个人隐私及数据安全带来了极大的挑战。例如,facebook数据泄露、yahoo数据泄露等事件引起工业界和学术界的极大关注。隐私保护与数据安全也成为机器学习应用的重要课题。随着人工智能飞速发展,数据的有效共享和融合需求愈发强烈,为了解决数据隐私和解决数据孤岛带来的挑战,联邦学习应运而生,并在健康医疗、金融分析等领域得到广泛应用。联邦学习是一种面向多用户场景的分布式机器学习框架,其被用来解决人工智能遇到的数据孤岛和隐私保护问题。该技术能够在不需要参与方上传原始数据的情况下,通过服务器协调多个参与方共同完成一个全局模型的训练,实现“数据可用不可见”。联邦学习中的训练数据分布在数据拥有者的设备上,数据拥有者本地训练并只与服务提供者共享模型参数,服务提供者通过某种算法(如fedavg、fedprox等)聚合数据拥有者的更新来训练全局模型。典型联邦学习通常包括以下几个步骤:(1)所有参与方从服务器下载最新模型;(2)每个参与方利用本地数据计算梯度,然后将梯度加密上传到服务器,服务器再聚合这些梯度更新模型参数;(3)服务器将更新后的模型分发给各参与方;(4)所有参与方更新本地模型。依次迭代(1)(2)(3)(4)步骤,直到模型收敛或达到指定的终止条件为止。典型联邦学习的参与方选择主要使用随机选择的方式,此种方案无法保证训练的可靠性和参与方数据的真实性。
2、联邦学习带来了许多益处,由于其参与训练的多方之间不需要直接进行数据交换,所以在一定程度上保护了用户的隐私和数据安全。但是随着互联网技术的发展,用户对隐私保护的需求提高,联邦学习模型在数据隐私与安全保护面临着新的挑战。联邦学习隐私保护目前依然存在如下问题:
3、(1)隐私保护机制开销大
4、近年来,基于差分隐私、秘密共享、同态加密、安全多方计算等技术,研究者提出了大量的隐私保护方法。然而,这些方法往往计算量和通信开销较大,会对应用的可用性和实时性造成影响。因此,如何针对互联网服务的具体需求设计能效平衡的隐私保护,尤其是能够满足数据实时性查询需求的隐私保护机制,成为隐私保护方案设计所面临的挑战。
5、(2)隐私保护机制鲁棒性较差
6、差分隐私、同态加密和安全多方计算等可以提高联邦学习的安全性,但是这些隐私保护机制也会影响模型的性能和准确性,从而降低联邦学习的鲁棒性,在一定程度上影响其适用性。联邦学习的真实应用场景下的数据往往不满足独立同分布,但是现有联邦学习隐私保护机制都在一定程度上假设数据的独立同分布性质。数据非独立同分布下的数据安全和隐私保护机制设计也成为联邦学习的一大挑战。
7、(3)缺乏有效的激励机制
8、如何保证服务器和本地参与方为诚实的、没有恶意的,保证训练数据的干净也是隐私保护中的一大挑战。
9、因此,为保证越来越多的联邦学习应用安全落地,设计一种能效平衡的联邦学习参与方选择机制势在必行。
技术实现思路
1、针对现有技术中的上述不足,本发明结合模型对称性、数据对称性和通信资源对称性理论提出一种联邦学习参与方选择方法,以求降低联邦学习参与方攻击、提高参与方的积极性、改进现有的联邦学习隐私保护机制,为联邦学习的应用提供更好的隐私保护。
2、一种以对称理论为基础的联邦学习参与方选择方法,包括以下步骤:
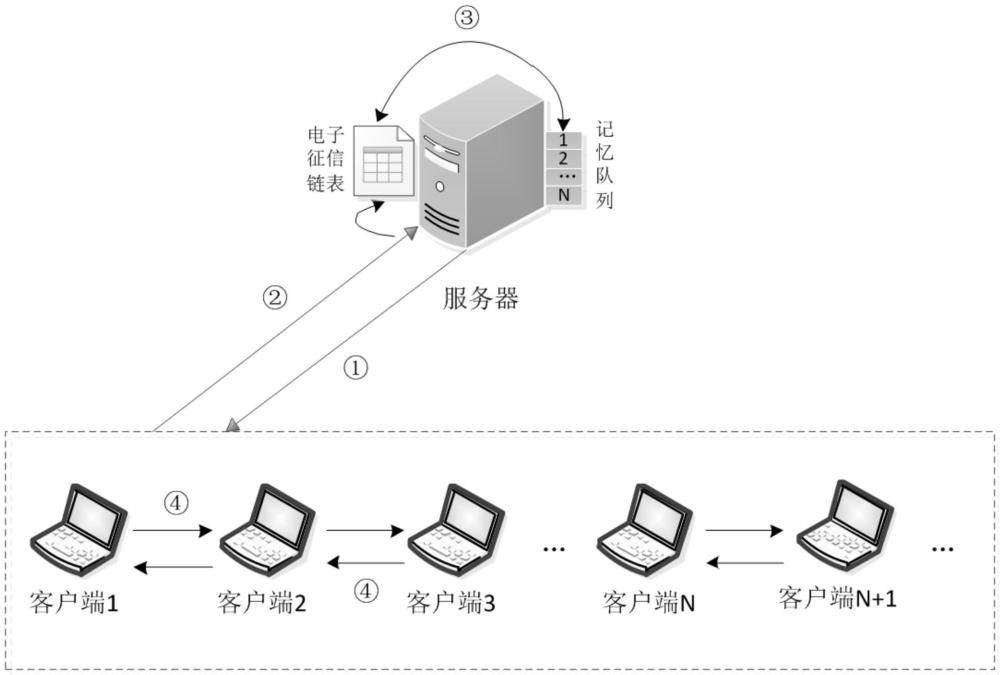
3、s1、服务器周期性向客户端发出试探性信息;所述试探性信息主要包含网络情况探索包、网络连接探索包、服务延时探索包、连断探索包、数据对称性探测包和客户端参与训练意愿包;
4、s2、客户端向服务器返回确认信息;
5、s3、服务器通过返回信息评价客户端;服务器评价客户端好坏的指标为参训意愿、数据真实性、返回时延、服务时延、网络拓扑和网络拥塞;服务器依次给这些指标赋予一个权值,然后根据一定的算法算出本周期内的最佳参与方;
6、s4、按照参与方返回信息计算客户端参训系数;
7、①分别为m个客户端的参数参训意愿、数据真实性、返回时延、服务时延、网络健壮性、网络拥塞赋予权值n1、n2、n3、n4、n5、n6,权值从大到小依次排序;
8、②计算客户端参训系数=∑(参数×权值)=参数意愿×n1+数据真实性×n2+1/返回时延×n3+1/服务时延×n4+网络健壮性×n5+1/网络拥塞×n6;
9、s5、服务器按照队列中出现的客户端信息,顺序与各客户端签订参训协议,该协议为电子标识,签订协议之后将其存放到服务器电子征信链中,用于记录参训客户端的电子征信,作为后续选择参与方的重要凭证;
10、s6、服务器结合参训系数和前期征信情况选择表现较好的n个客户端作为参与方参与模型训练。
11、作为优选的,步骤s1中网络情况探索包包括拥塞情况和流量情况;
12、网络连接探索包为客户端所在网络的拓扑情况,包括客户端的网络健壮性和容错性;
13、连断探索包为一个记忆队列,记录本次发送返回数据的时延信息,由小到大排列优先级,将延时较长的客户端信息在队列中移除;
14、数据对称性探测包用于提供给客户端测评数据的可靠性和真实性,数据的可靠性和真实性由服务器端评价,服务器端通过同类数据训练模型的对称性评价客户端数据的可靠性和真实性;
15、客户端参与训练意愿包为希望客户端返回是否有意愿参与训练的反馈信息,该信息包含周期性信息探索时限、是否反馈信息,如果该周期内客户端不想参加训练,则不需要给服务器返回信息。
16、作为优选的,步骤s3中参训意愿、数据真实性、返回时延、服务时延、网络拓扑、网络拥塞的优先级依次降低。
17、作为优选的,步骤s4和步骤s6中m>n。
18、本发明的有益效果为:
19、本发明提供一种以对称理论为基础的联邦学习参与方选择方法,可以解决典型联邦学习中随机选择参与方给联邦学习带来的困难;典型联邦学习通常使用随机选择的方式选择客户端作为联邦学习模型训练的参与方,这种选择方式无法保证参与方的数据可靠性、数据真实性和稳定性。本发明提出的方案可以有效解决此类问题,为联邦学习在隐私保护方面提供更好的保证,为数字治理提供更好的隐私保护方案。
技术特征:1.一种以对称理论为基础的联邦学习参与方选择方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种以对称理论为基础的联邦学习参与方选择方法,其特征在于:步骤s1中网络情况探索包包括拥塞情况和流量情况;
3.根据权利要求1所述的一种以对称理论为基础的联邦学习参与方选择方法,其特征在于:步骤s3中参训意愿、数据真实性、返回时延、服务时延、网络拓扑、网络拥塞的优先级依次降低。
4.根据权利要求1所述的一种以对称理论为基础的联邦学习参与方选择方法,其特征在于:步骤s4和步骤s6中m>n。
技术总结本发明涉及数据处理技术领域,特别涉及一种以对称理论为基础的联邦学习参与方选择方法,可以解决典型联邦学习中随机选择参与方给联邦学习带来的困难;典型联邦学习通常使用随机选择的方式选择客户端作为联邦学习模型训练的参与方,这种选择方式无法保证参与方的数据可靠性、数据真实性和稳定性。本发明提出的方案可以有效解决此类问题,为联邦学习在隐私保护方面提供更好的保证,为数字治理提供更好的隐私保护方案。技术研发人员:张泽飞,惠蓉,王云惠,丁帆,冯阳平受保护的技术使用者:滇西应用技术大学技术研发日:技术公布日:2024/9/2本文地址:https://www.jishuxx.com/zhuanli/20240905/288829.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表