一种基于用户通俗口语表达的端到端歌曲生成方法和系统与流程
- 国知局
- 2024-09-11 15:06:01
本发明属于人工智能音乐生成,具体涉及一种基于用户通俗口语表达的端到端歌曲生成方法和系统。
背景技术:
1、文本到歌曲生成旨在根据描述性文本创建歌曲。先前研究通常侧重于歌曲创作的特定方面,例如文本到音乐、歌词到旋律和乐谱到歌曲,但并未涵盖整个歌曲创作过程。在文本到音乐生成方面,诸如musiclm和musicgen等模型利用基于采用单阶段transformer语言模型通过基于量化的音频编解码器,进行文本到音乐的生成,并采用高效的码本交织模式,并采用大语言模型和扩散模型来生成高质量的音频。对于歌词到旋律生成,songmass,telemelody,和songglm以歌词为输入并输出旋律,确保歌词与旋律关联。对于乐谱到歌曲生成,melodist采用了两阶段方法,包括从给定乐谱生成歌声以及基于歌声和自然语言提示生成伴奏。文本到歌曲生成平台,如suno,skymusic,和songr,其能力受到广泛关注。然而,这些平台通常不提供其数据集和方法的访问权限,这可能会限制可重复性并给未来的研究带来挑战,同时它可能遇到诸如对输入文本描述的理解不佳以及生成的歌曲缺乏结构等问题。
2、在音乐生成领域,尽管迄今为止已经提出了许多数据集,包括使用音乐信息检索(mir)算法或大型语言模型(llm)的自动注释以及手动注释得出的数据集,自动标注数据集采用现有的音乐信息检索算法,从符号音乐或音频音乐中提取音乐属性。然后,将提取的属性合并到完整的描述性文本中,或者视为描述性标签。msd收集了大量的音乐数据,包括通过echo nest analyze api(mir工具包)获取的音频、midi和标签。pop909提供了一个包含音频、主旋律谱和其他音乐属性(如调和节拍)的数据集。musecoco和mustango从原始音频中提取特征,然后利用chatgpt将这些特征整合成描述文本。noise2music中的mulamcap利用大型语言模型生成一组音乐描述文本,然后采用mulan(一种文本-音乐嵌入模型)将这些文本与数据集中的音乐音频进行匹配。尽管如此,通过自动标注获得的数据集与复杂的人类描述之间仍存在显著的语义差距,这会降低数据集的准确性并限制模型的性能。
3、手动标注数据集收集来自音乐网站的描述或标签,或者包括专业音乐人标注的数据。hooktheory是一个音乐网站,用户在上面上传带有诸如旋律、和弦和节拍等标注的音频。mtg和mousai使用音乐网站上的相应标签作为描述标签,而erniemusic则使用音乐评论作为音乐描述,并据此建立数据集。musiclm提供了一个由专业音乐人标注的音乐描述数据集musiccaps。然而,目前的手动标注数据集受限于专家的标注和有限的描述范围,这与普通大众提供的描述显著不同。此外,现有的手动标注数据集通常每条记录仅由一个人标注,这也可能导致由于人为错误或偏见而产生的不准确性。
技术实现思路
1、鉴于上述,本发明的目的是提供一种基于用户通俗口语表达的端到端歌曲生成方法和系统,在充分理解的口语化表达的基础上创建歌曲,并将用户的通俗口语表达与创建的歌曲进行匹配。
2、为实现上述发明目的,实施例提供的一种基于用户通俗口语表达的端到端歌曲生成系统,包括:
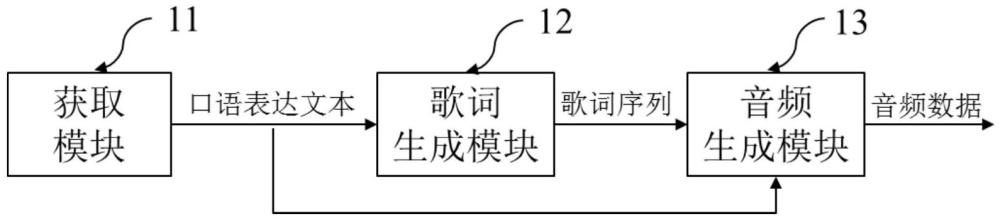
3、获取模块,其用于获取用户输入的通俗口语表达文本并将其作为描述文本提示词;
4、歌词生成模块,其用于采用大语言模型根据描述文本提示词生成具有乐段结构的歌词序列;
5、音频生成模块,其用于采用生成模型基于具有乐段结构的歌词序列进行去噪处理来生成表示音乐的潜在概率分布,并基于潜在概率分布在vae模型的音频数据空间中进行搜索得到歌词序列对应的音频分布,音频分布中的每个点表示一段音频,将音频分布转换成频谱图后,将频谱图转换为歌曲的音频数据。
6、优选地,所述具有乐段结构的歌词序列包括由歌词组成的序列,在序列中歌词带有标签,其中标签包括音色、乐器、音效、风格、以及乐段结构标签,乐段结构标签包括前奏、主歌、预副歌、副歌、桥段或间奏、以及结语;
7、在忽略歌词情况下,将乐段结构标签通过分隔标签分隔排列,形成乐段结构。
8、优选地,所述采用生成模型基于具有乐段结构的歌词序列进行去噪处理来生成表示音乐的潜在概率分布,包括:
9、初始化连续的多个时间窗口,针对每个时间窗口,从具有乐段结构的歌词序列中提取与时间窗口长度匹配的至少部分歌词序列作为当前输入歌词序列,基于当前输入歌词序列和前一时间窗口对应的生成音频数据通过生成模型进行连续去噪,生成当前时间窗口对应的表示音乐的潜在概率分布。
10、优选地,所述对基于当前输入歌词序列和前一时间窗口对应的生成音频数据通过生成模型进行连续去噪,生成当前时间窗口对应的表示音乐的潜在概率分布,包括:
11、针对当前时间窗口,将前一时间窗口对应的生成音频数据、描述文本提示词通过clap处理形成嵌入向量后与当前噪声拼接形成拼接向量并输入至生成模型,同时将当前输入歌词序列也输入到生成模型,在生成模型中进行时间步t的去噪处理得到时间步t对应的去噪结果,该去噪结果作为时间步t-1的当前噪声;
12、其中,t取值为[0,t],当t取t时,时间步t对应的当前噪声为初始随机噪声,时间步t对应的前一时间窗口对应的生成音频数据为空向量;当t取0时,时间步0对应的去噪结果认为是无噪声结果,作为表示音乐的潜在概率分布。
13、优选地,所述生成模型包括用于基于拼接向量和歌词序列进行噪声生成的dit子模型、和基于生成噪声进行去噪计算的ddpm子模型;
14、在dit模型中,输入的拼接向量作为噪声潜在向量经过块划分和第一层归一化处理后,通过多头自注意力处理来关注第一重要特征,并将第一重要特征和多头自注意力处理的输入向量通过第一残差连接拼接后再经过第二层归一化处理得到输入的拼接向量对应处理后第一向量;
15、当前输入歌词序列经过嵌入处理得到嵌入向量后与第一向量进行多头交叉注意力处理来关注第二重要特征,并将第二重要特征与第一残差连接拼接结果通过第二残差连接拼接后得到第二向量;
16、第二向量经过第三层归一化和逐点前馈处理后与第二向量再拼接,拼接后结果通过第四层归一化、线性映射和形状调整后得到噪声分布。
17、优选地,所述dit子模型替换为sit子模型,sit子模型中,在形状调整过程中,通过采样器的选择进行随机性采样,基于随机采样结果来生成噪声分布;
18、dit子模型的插值框架中通过选择的插值参数在生成模型输出的潜在概率分布和vae的高维正态分布空间找到一个映射关系,基于映射关系来搜索确定歌词序列对应的音频分布。
19、优选地,所述vae模型包括vae编码器和vae解码器,基于自监督训练得到,其中vae编码器用于将输入的音频数据压缩编码到音频数据空间的音频分布,vae解码器用于将音频数据空间的音频分布解码生成频谱图;
20、训练后的vae编码器对应的音频数据空间的音频分布被采样作为训练生成模型的样本数据;
21、训练后的vae解码器用于在应用时将音频分布转换成频谱图。
22、优选地,所述生成模型在被应用之前需要经过参数优化,参数优化时,对vae模型的音频数据空间的音频分布进行采样得到样本数据,并以音频数据作为标签,对生成模型进行基于样本数据在标签下的监督训练,以优化生成模型参数。
23、优选地,所述大语言模型在被应用之前经过微调,微调时采用的文本数据包括:采用专业人士和业务爱好者对音乐进行标注的音乐注释,其中音乐注释采用专业化描述和通俗口语化描述,并且专业化描述与通俗口语化描述形成数据对,利用数据对对大语言模型进行微调,使其能够基于通俗口语化描述文本转换为具有乐段结构的歌词序列。
24、为实现上述发明目的,本发明实施例还提供了一种基于用户通俗口语表达的端到端歌曲生成方法,采用上述端到端歌曲生成系统,所述方法包括以下步骤:
25、利用获取模块获取用户输入的通俗口语表达文本并将其作为描述文本提示词;
26、利用歌词生成模块采用大语言模型根据描述文本提示词生成具有乐段结构的歌词序列;
27、利用音乐生成模块基于歌词序列生成音频数据,具体包括:在每个时间窗口内,采用生成模型基于具有乐段结构的歌词序列进行去噪处理来生成表示音乐的潜在概率分布,并基于潜在概率分布在vae模型的音频数据空间中进行搜索得到歌词序列对应的高维音频分布,音频分布中的每个点表示一段音频,将高维音频分布转换成频谱图后,将频谱图转换为歌曲的音频数据,多个时间窗口按序生成的音频数据组成最终音频数据。
28、为实现上述发明目的,本发明实施例还提供了一种计算设备,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述基于用户通俗口语表达的端到端歌曲生成方法。
29、与现有技术相比,本发明具有的有益效果至少包括:
30、本发明采用大语言模型将通俗口语表达文本转换为具有乐段结构的歌词序列,这样能够充分理解口语表达,歌曲创作的普适性更强,且能够充分捕捉歌曲的音乐结构,包括乐句结构和押韵格式。在此基础上,通过生成模型生成音乐的潜在概率分布,通过vae模型来搜索聚类高维音频分布,通过将高维音频分布转换成频谱图再转换为歌曲的音频数据,这样自动生成歌曲更丰富,且创作的歌曲能够高度与通俗口语表达匹配和对齐。
本文地址:https://www.jishuxx.com/zhuanli/20240911/293190.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表