基于DSAW离线强化学习算法的冗余驱动机械臂路径规划方法
- 国知局
- 2024-10-09 15:19:46
本发明属于机械臂三维空间路径规划领域,具体是一种基于dsaw离线强化学习算法的冗余驱动机械臂路径规划方法。
背景技术:
1、路径规划是机械臂开展自主作业的一项核心任务,其目标是为机器臂末端在环境中从起点到终点找到最优或可行的路径,同时冗余驱动机械臂逆解有无穷多个。在冗余驱动机械臂路径规划过程中需要考虑多种因素,如避免障碍、逆解、最小化路径长度或耗费、遵循特定的路径规则等。路径规划对于提高机器人和自动化系统的效率和安全性至关重要。
2、随着技术的发展,传统的路径规划方法虽然在特定场景下效果显著,但在复杂、动态或未知环境中面临挑战。这些环境要求系统具备更高的适应性和学习能力,能够根据环境变化和历史经验做出决策。而强化学习由于其高度的自主学习性能够很好地适应这些问题。因此将路径规划与强化学习的结合为解决复杂环境下的导航问题提供了新的视角和方法。
3、然而在更加复杂和不确定的高维环境下,强化学习由于自身的低探索性能,经验池大小限制很难适用于高纬度多目标任务,不仅耗时探索而且收敛速度慢,容易导致维数灾难导致规划能力降低,而离线强化学习,又称作批量强化学习,是强化学习的一种变体,它的主要思路是智能体从固定的一个数据集中进行学习,而不进行探索。
4、而机械臂路径规划与无人机与小车不同,因此在路径规划部分还需要考虑到如何计算出准确的关节角度使得机械臂末端能够正确的到达指定位置。
技术实现思路
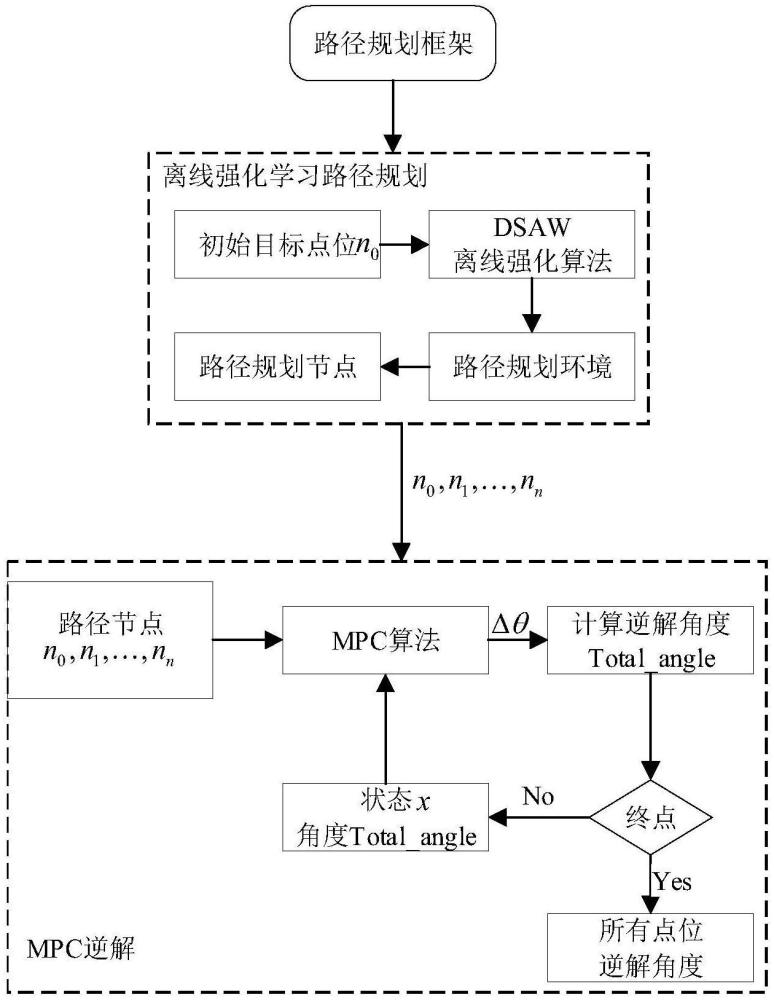
1、发明目的:针对上述现有技术,提出一种基于dsaw(dense state advantageweighting)离线强化学习算法的路径规划方法,在大规模地图下,提高节点遍历速度,减少迭代次数减少输出路径长度,保证最优关节求解角度。
2、技术方案:为实现上述技术目的,本发明公开一种基于dsaw离线强化学习算法的冗余驱动机械臂路径规划方法,包括如下步骤:
3、步骤1:全局地图初始化;其方法为:进行环境建模并建立三维坐标系,对环境中的所有障碍物采用包围法进行长方体和球体简化,设障碍物数量为k,组成障碍物集合为{obji},即
4、步骤2:设计强化学习状态空间;状态空间是强化学习中环境的基础组成部分,它定义了在路径规划过程中,智能体可以感知的所有信息。因此依据路径规划的实际需求将状态空间设计为state={start,goal,current,distobstacle,distgoal,step},其中start=(xinit,yinit,zinit)表示为起点位置,goal=(xend,yend,zend)表示终点位置,current=(xcurrent,ycurrent,zcurrent)表示当前节点位置,distobstacle表示当前节点与障碍物之间的距离,distgoal表示当前节点与终点之间的距离,step表示运行步数;
5、步骤3:设计强化学习动作空间;强化学习的路径规划应用中,动作空间定义了智能体可以执行的所有可能动作。对于智能体来说,最关键的动作涉及到寻找点位过程中的方向和步长。因此将动作空间设计为action={x,y,z,length},其中(x,y,z)表示方向向量,范围设计为(-1,1),length表示单次运行的步长;
6、步骤4:设计强化学习的奖励函数;奖励函数在强化学习的路径规划应用中扮演着至关重要的角色,它不仅指导智能体如何完成任务,还帮助形成高效和安全的行为模式。一个有效的奖励函数应该包括对正确行为的奖励、对不理想行为的惩罚,以及引导智能体逐步学习和优化的机制。
7、步骤5:在步骤2至步骤4构成的强化学习路径规划环境中进行离线强化学习数据集的搭建,这其中包括了历史交互记录、模拟器生成的数据以及专家演示获得的数据。对数据集进行必要的归一化预处理,以提高其可用性;
8、步骤6:使用离线强化学习算法dsaw在处理过的数据集中进行学习迭代,输出路径;
9、步骤1中,使用包围法对障碍物进行简化的具体过程为:将智能体视为一个半径为r的小球,对于球体障碍物,二者之间的碰撞距离为:
10、
11、式中,表示球体障碍物的球心坐标,由此可知碰撞检测的公式如下所示:
12、
13、式中,表示球体障碍物半径如果tcollision为1则表示智能体与第i个障碍物发生了碰撞,如果tcollision为0则表示智能体与第i个障碍物没有发生碰撞。
14、对于长方体障碍物,检测二者之间是否发生碰撞的判断公式如下所示:
15、通过aabb包围法对不规则障碍物进行简化,确保简化后的长方体的各个面与方向轴平行,设长方体上最小的坐标位置为(xmin,ymin,zmin),最大坐标为(xmax,ymax,zmax),智能体的球心坐标为(xcurrent,ycurrent,zcurrent),半径为r,最近点坐标为(x,y,z)。首先计算球心与aabb长方体的最近点,如果满足如下公式:
16、
17、则最近点(x,y,z)是智能体的球心(xcurrent,ycurrent,zcurrent),此时发生碰撞。对于最近点不在长方体范围内的,则判断球心(xcurrent,ycurrent,zcurrent)到长方体(xmin,xmax),(ymin,ymax),(zmin,zmax)的距离,如果存在球心xcurrent<xmin则最近点的坐标为xmin,xcurrent>xmax则是xmax,同理可得最近坐标y,z。
18、当最近点不在长方体范围内,使用欧几里得距离公式,计算最近点到球心的距离:
19、
20、如果存在则发生碰撞。
21、步骤4中,强化学习奖励函数的设计遵循以下原则:
22、(1)惩罚奖励函数:为了安全的规划处一条无碰撞的路径,需要在发生碰撞时添加惩罚参数rcollision=-λcollision,rcollision其中表示碰撞惩罚奖励,λcollision表示惩罚参数是一个常数,如果发生碰撞则给一个负的奖励,该惩罚项能够帮助智能体学习如何避开碰撞问题。
23、(2)引导奖励函数:通过定义不同的距离阈值,可以将路径规划的任务分解为从远离目标到接近目标的多个阶段。每个阶段都可以有其特定的学习目标和奖励机制,具体公式如下:
24、
25、式中,d表示末端位置和目标位置的欧氏距离,di表示指定的距离范围,λi表示在不同距离下不同的奖励参数,r1表示阶段性奖励函数。
26、(3)基础奖励函数:提供正向反馈,引导智能体朝着完成任务的方向前进。为接近目标状态(如逐渐接近目标位置)的行为提供小额的正奖励。帮助机械臂在学习初期,即使还未能完成整个任务,也能获得正向的学习信号,公式如下所示:
27、
28、式中,表示当前时刻智能体与目标位置之间的欧氏距离,表示调整参数是个常数,表示基础奖励函数。
29、将上述三个奖励相加,得到了完整的路径规划奖励函数rsum=rcollision+r1+r2;
30、步骤5中,离线强化学习数据集的具体收集步骤为:离线数据集的采样主要是是通过在线强化算法与搭建好的路径规划环境进行交互取得的,这其中对于算法的选择非常的重要。主要选取的采样算法包括了以下几种算法,分别是td3,ddpg算法,以及设计好的专家数据集。
31、td3算法适用于处理连续动作空间的问题,其改进的策略更新机制和价值估计方法使其在复杂环境中表现出色。
32、ddpg算法在进行数据收集时表现出较强的稳健性和数据效率,特别适合于那些对数据质量和数量有限制的应用场景。
33、专家数据集通常由经验丰富的操作者或经过精心设计的策略生成,因此数据质量高,能提供有效的学习信号。使用专家数据集可以显著加速学习过程,尤其是在任务的初始阶段,因为它提供了正确行为的示例。
34、同时对数据进行必要的预处理能够有效的提高其可用性,对状态函数s进行归一化处理,公式如下所示:
35、
36、式中,α表示调整参数,q(si,s′i)表示状态值函数,s′表示下一时刻状态,n表示q(si,s′i)的数目。
37、步骤6中,dsaw算法的具体更新过程为:依据路径规划环境,提出了密集状态优势函数:
38、w(s,s')=[a(s,s')≥0]=[(qθ(s,s')-vψ(s)≥0]=1[qθ(s,s')≥vψ(s)]
39、式中,w(s,s′)表示依赖于当前时刻状态和下一时刻状态的加权函数,qθ(s,s')和vψ(s)分别表示状态批评家函数和对当前状态的评估函数。1[qθ(s,s')≥vψ(s)]表示在q(s,s′)大于v(s)时w(s,s′)值为1,在q(s,s′)小于v(s)时w(s,s′)值为0。该加权函数能够给理想的策略分配更大的权重,而给较差的策略更小的权重。
40、依据上文提出的密集状态优势函数,离线强化学习算法dsaw的更新过程,首先是对状态评估函数vδ(s)进行更新:
41、
42、式中,表示指示器函数,k表示调整参数。该函数的作用通常为强调qθ'(s,s')大于vδ(s)值的时刻,用于提高优质状态的权重,降低劣质状态的权重,而qθ'(s,s')是由网络θ的目标网络θ生成,而状态评估网络vδ(s)由网络参数δ生成。然后对状态值函数qθ(s,s')进行更新:
43、
44、值得注意的是,在进行qθ(s,s')和vδ(s)的更新时,只使用来确保数据在离线数据集中,从而避免了外推误差的干扰。
45、下一步进行前向网络的更新,如果直接训练一个正向的模型通过状态s去预测下一时刻状态s′是不准确的,而如果训练一个前向网络并通过状态s和动作a去预测下一时刻状态,则可以提高准确性和可靠性,因此使用前向网络f(s,a)来进行预测,而fφ(s,a)由网络参数φ生成,通过最小化来进行训练:
46、
47、qss框架是对s状态和s′的学习方式,需要一个由网络参数ω生成的逆动力学模型iω(s,s')去反推出动作a,逆动力学模型采用定理1提出的优势加权函数w(s,s′)进行训练:
48、
49、式中,iω表示逆动力学网络,s和s′表示当前时刻状态和下一时刻状态。最后,在qss学习框架下,需要去评估下一时刻状态s′,因此需要一个额外的预测网络s′=τ(s),为了保持接近数据集中的分布,通过以下方式进行训练迭代:
50、
51、以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
52、有益效果:(1)本发明公开一种在三维空间中进行冗余驱动机械臂的路径规划任务,能够避免碰撞问题发生的方法,在saw算法的基础上结合路径规划环境提出了密集状态优势加权函数,确保策略偏向于数据集中的高质量数据,以减少低质量数据的负面影响,提高了规划路径的效率。
53、(2)针对强化学习路径规划环境的状态空间,动作空间,奖励函数这三个设计问题,从位置,碰撞约束,步长限制等多个方面设计了基础奖励函数,碰撞惩罚奖励函数,目标奖励函数来引导智能体学习达到目标点的行为策略,提高了冗余驱动机械臂在有障碍物的三维空间中进行规划路径的成功率
54、(3)通过对冗余驱动机械臂的冗余驱动关节角度的求解,通过模型预测控制算法对冗余驱动机械臂关节移动路径节点的求解,从而获得了在避开障碍物的情况下求解出冗余驱动机械臂的最优关节角度。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308357.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。