用于虚拟筛选的蛋白配体亲和力预测方法、系统、电子设备及存储介质
- 国知局
- 2024-10-21 14:32:52
本发明属于生物信息结合深度学习的,更具体地,涉及一种用于虚拟筛选的蛋白配体亲和力预测方法、系统、电子设备及存储介质。
背景技术:
1、蛋白-配体亲和力是指蛋白质与其配体之间的相互作用的强度,蛋白质功能的发挥通常依赖于与其他分子结合从而产生的相互作用,其亲和力的强弱决定了蛋白质-配体结合的稳定性与特异性。因此,蛋白-配体亲和力的预测对药物开发、蛋白分子设计等都具有重要的指导意义,运用深度学习的方法预测蛋白配体亲和力预测有助于实现高通量筛选,解释生物体复杂的生命过程以及指导酶的分子水平改造。
2、蛋白与配体的相互作用是蛋白发挥作用的基础和核心,蛋白和配体的亲和力又是蛋白发挥作用强弱的重要指标,化学或生物领域中定量研究蛋白质配体的方法是结合亲和力来评估蛋白质配体分子的结合紧密程度,相对应的亲和力指标包括解离平衡常数kd(dissociation binding constant)、抑制常数ki(inhibition constant)、以及半抑制浓度ic50(half maximal inhibitory concentration),这些指标的测得除了需要设置复杂限制条件下的实验环境,还需要大量的正实验和重复实验,这对成本和实验人员的精力投入与技术水平要求很高,无法大规模投入使用。
3、分子动力学模拟使用计算的方法,基于物理学利用三维结构来完成蛋白质配体分子间亲和力的估测,通过模拟计算不同能量项,基于物理学的方法被认为是较为准确的方法,但是分子动力学模拟需要耗费大量的计算资源,代价过于昂贵。
4、近年来,随着人工智能技术的发展,尤其是机器学习已经被应用到酶工程,与传统基于物理和理论的方法相比,基于机器学习的方法以数据为中心,通过搭建模型来拟合数据,从数据中学习经验从而实现预测。目前流行的深度学习方法中分别应用原子三维结构信息和一维氨基酸序列信息来进行预测,单独使用一种信息无法完全利用蛋白和配体复合物所包含的全部信息,将原子三维结构信息和一维氨基酸序列信息结合来搭建模型进行预测能有效提升预测精度。
5、例如,中国专利文献cn115148279a公开一种蛋白质与配体分子的亲和力预测方法、装置、设备和计算机可读存储介质。其方法基于从蛋白质与配体分子结合的三维结构图中提取的节点特征、边特征和几何特征,通过预先训练的预测模型获得蛋白质与配体分子的亲和力,并获得用于指示蛋白质与配体分子的原子之间相互作用的相互作用图,在提升亲和力预测性能的基础上,能够判断所预测的蛋白质与配体分子的原子相互作用是否正确,使得预测结果具有可解释性。其中,该预测模型是通过对亲和力预测和相互作用图预测的误差校正获得的,因此通过本公开的实施例的方法能够在误差校正的基础上学习到更准确的亲和力预测和相互作用图预测。
6、中国专利文献cn116312758a公开一种基于图神经网络解耦的蛋白质与配体的亲和力预测方法,方法包括:s1、获取蛋白质-配体的复合物的训练数据集;其中所述训练数据集中包括蛋白质-配体的复合物的原子信息、键信息、空间结构信息;s2、对获取的蛋白质-配体的复合物的训练数据集进行预处理;s3、构建用于药物与蛋白质亲和力预测的解耦的图神经网络模型;s4、利用预处理后的训练数据集对构建的解耦的图神经网络模型进行训练,得到训练好的图神经网络模型;s5、利用训练好的解耦的图神经网络模型对待预测的蛋白质-配体的复合物进行亲和力预测,得到亲和力预测结果。
7、上述引用模型进行预测具有很强的技术性,需要一定的计算机编程背景才能熟练应用。为了打破技术壁垒,使得模型能够具有易用性,为此本发明提出了一种用于虚拟筛选的蛋白配体亲和力预测方法及系统,以web系统的形式对该项技术进行封装来解决上述问题。
技术实现思路
1、本发明旨在克服上述现有技术的至少一种缺陷,提供一种用于虚拟筛选的蛋白配体亲和力预测方法,以提高蛋白-配体亲和力预测的精度和效率。
2、本发明还公开一种用于虚拟筛选的蛋白配体亲和力预测系统。
3、本发明详细的技术方案如下:
4、一种用于虚拟筛选的蛋白配体亲和力预测方法,所述方法包括:
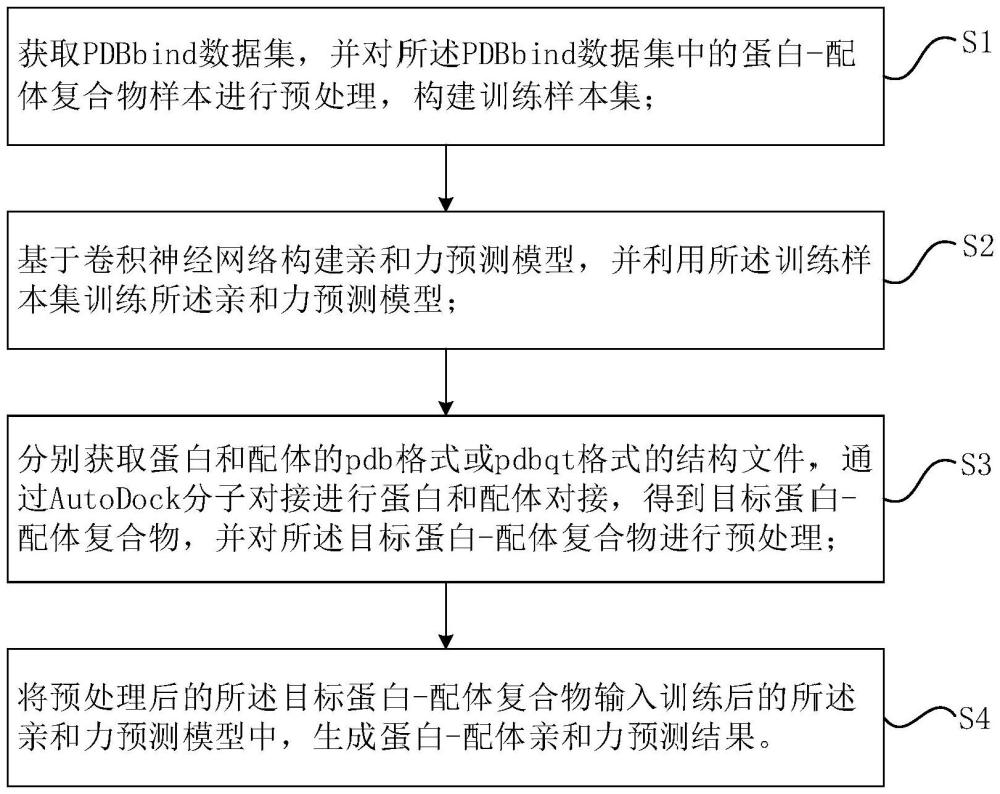
5、s1、获取pdbbind数据集,并对所述pdbbind数据集中的蛋白-配体复合物样本进行预处理,构建训练样本集;
6、s2、构建亲和力预测模型,并利用所述训练样本集训练所述亲和力预测模型;
7、s3、分别获取蛋白质和配体的pdb格式或pdbqt格式的结构文件,通过autodock分子对接进行蛋白质和配体对接,得到目标蛋白-配体复合物,并对所述目标蛋白-配体复合物进行预处理;
8、s4、将预处理后的所述目标蛋白-配体复合物输入训练后的所述亲和力预测模型中,生成蛋白-配体亲和力预测结果。
9、根据本发明优选的,对所述pdbbind数据集中的蛋白-配体复合物样本或对所述目标蛋白-配体复合物进行预处理,其中,组成蛋白质和配体的原子主要包括c、h、o、n、p、s、f、cl、br、i、k、na、fe、mg、cu等,不同原子之间通过化学键连接;
10、预处理操作包括:使用59维向量编码所述蛋白-配体复合物样本或目标蛋白-配体复合物中蛋白质的单个蛋白原子,即使用sspro工具预测蛋白质每个序列的二级结构,并使用8维one-hot向量对其进行编码,其中,所述蛋白质每个序列的二级结构包括α螺旋、孤立β桥残基、参与β阶梯、氢键转弯、310螺旋、π螺旋、弯曲和线圈;
11、使用11维one-hot向量对蛋白质的理化性质进行编码,所述蛋白质的理化性质包括极性、非极性、酸性、碱性和7种基团,并使用21维one-hot向量对蛋白质的20种标准氨基酸残基和1类非标准残基进行编码;
12、使用9维one-hot向量对蛋白质中所包含的9类原子进行编码,9类原子包括硼原子、碳原子、氮原子、氧原子、磷原子、硫原子、硒原子、卤素原子和金属原子;
13、使用1维one-hot向量分别对蛋白质的原子杂化类型、原子与除氢原子之外的其他重原子的键数、以及原子与除碳原子和氢原子之外的其他杂原子的键数进行编码;
14、使用5维one-hot向量对蛋白质的原子属性进行编码,所述蛋白质的原子属性包括疏水、芳香族、受体、供体和环;
15、使用1维one-hot向量分别对蛋白质的原子带电荷量以及原子归属进行编码,所述原子归属为蛋白质。
16、根据本发明优选的,对所述pdbbind数据集中的蛋白-配体复合物样本或对所述目标蛋白-配体复合物进行预处理,还包括:使用19维向量编码所述蛋白-配体复合物样本或目标蛋白-配体复合物中配体的单个配体原子,即使用9维one-hot向量对配体中所包含的9类原子进行编码,9类原子包括硼原子、碳原子、氮原子、氧原子、磷原子、硫原子、硒原子、卤素原子和金属原子;
17、使用1维one-hot向量分别对配体的原子杂化类型、原子与除氢原子之外的其他重原子的键数、以及原子与除碳原子和氢原子之外的其他杂原子的键数进行编码;
18、使用5维one-hot向量对配体的原子属性进行编码,所述配体的原子属性包括疏水、芳香族、受体、供体和环;
19、使用1维one-hot向量分别对配体的原子带电荷量以及原子归属进行编码,所述原子归属为配体。
20、根据本发明优选的,对所述pdbbind数据集中的蛋白-配体复合物样本或对所述目标蛋白-配体复合物进行预处理,还包括:根据所述亲和力预测模型的输入网格大小对编码后的所述蛋白-配体复合物样本或目标蛋白-配体复合物中的单个蛋白原子和单个配体原子进行裁剪,保留位于相应网格内单个蛋白原子和单个配体原子;所述裁剪过程为:
21、使用tf.bio库分别获取单个蛋白原子和单个配体原子的位置坐标,将其映射为在所述亲和力预测模型中的位置;
22、计算配体分别在空间坐标系的x轴、y轴以及z轴上的平均值,以该平均值作为蛋白-配体复合物样本或目标蛋白-配体复合物的中心,并重新调整蛋白-配体复合物样本或目标蛋白-配体复合物的坐标位置;
23、根据调整后的蛋白-配体复合物样本或目标蛋白-配体复合物的坐标位置对其单个蛋白原子和单个配体原子进行裁剪。
24、根据本发明优选的,所述步骤s2中,基于卷积神经网络构建亲和力预测模型,所述亲和力预测模型包括用于提取蛋白质特征的两层block模块、用于提取配体特征的两层block模块、以及三层res block模块和一层全连接层,且每一层res block模块的输出经平均池化后输入下一层结构。
25、根据本发明优选的,所述block模块包含逐深度卷积和逐点卷积,且使用滤波器大小为3×3×3的3d卷积进行特征提取;所述res block模块由两个block模块和三个res残差块组成。
26、根据本发明优选的,所述步骤s3中还包括:将pdb格式的蛋白质或配体的结构文件转换成pdbqt格式,即首先对蛋白质或配体进行去除溶剂分子、金属离子和加氢操作,然后使用autodock tools调整蛋白质或配体的电荷、判定配体的根节点root并选择配体的可扭转的键,最后保存为pdbqt格式文件。
27、在本发明的另一个方面当中,提供了一种用于虚拟筛选的蛋白配体亲和力预测系统,所述系统包括:
28、训练样本获取模块,用于获取pdbbind数据集,并对所述pdbbind数据集中的蛋白-配体复合物样本进行预处理,构建训练样本集;
29、模型构建模块,用于构建亲和力预测模型,并利用所述训练样本集训练所述亲和力预测模型;
30、目标数据获取模块,用于获取蛋白质和配体的pdb格式或pdbqt格式的结构文件,通过autodock分子对接进行蛋白质和配体对接,得到目标蛋白-配体复合物,并对所述目标蛋白-配体复合物进行预处理;
31、亲和力预测模块,用于将预处理后的所述目标蛋白-配体复合物输入训练后的所述亲和力预测模型中,生成蛋白-配体亲和力预测结果。
32、在本发明的另一个方面当中,还提供了一种电子设备,包括:
33、至少一个处理器;以及
34、存储器,所述存储器存储指令,当所述指令被所述至少一个处理器执行时,使得所述至少一个处理器执行如上所述的用于虚拟筛选的蛋白配体亲和力预测方法。
35、在本发明的另一个方面当中,还提供了一种机器可读存储介质,其存储有可执行指令,所述指令当被执行时使得所述机器执行如上所述的用于虚拟筛选的蛋白配体亲和力预测方法。
36、与现有技术相比,本发明的有益效果为:
37、(1)本发明提供的一种用于虚拟筛选的蛋白配体亲和力预测方法,通过设计基于神经网络的亲和力预测模型,并将已完成分子对接且经过预处理后的目标蛋白-配体复合物输入该亲和力预测模型中进行亲和力预测,最终输出一维的亲和力数值;本发明提高了蛋白-配体亲和力预测的精度和效率,为实验人员进行虚拟筛选蛋白-配体复合物提供参考。
38、(2)本发明根据系统需求功能,设计一种web系统用于虚拟筛选的蛋白配体亲和力的预测,该系统所包含的各功能模块分别对应用于实现本发明方法的各个步骤,通过在web服务器上运行各功能模块,为实验人员提供可视化的蛋白-配体亲和力预测结果,同时便于实验人员进行交互操作。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318536.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。