车联网环境下基于聚类的高效联邦分割学习方法及装置
- 国知局
- 2024-10-21 14:52:31
本技术涉及联邦学习,涉及车联网环境下基于聚类的高效联邦分割学习方法及装置。
背景技术:
1、目前,近年来,随着大模型的巨大成功和进步,人们的日常生活已经发生了极大的变化。大模型能在文本生成、机器翻译、疾病诊断和智能交通等场景实现智能决策。数据是模型训练的基础和驱动力,大模型的强大功能源于对海量数据中隐藏的模式和规律的挖掘。海量数据从何而来?随着物联网技术的迅速普及,汽车上的传感器中保存了大量的数据。这些天然分布式的数据如何利用?一种方法是将它们发送到集中的节点进行训练。然而,这种方式有隐私泄露的风险而且通信代价高昂。
2、联邦学习(federatedlearning,fl)作为一种分布式的机器学习方法,为解决上述难题提供了新的思路。其在不交换数据样本的情况下,训练算法跨越多个分散的汽车或服务器,基于分布式的数据训练出全局模型。不同于传统的集中式机器学习技术,不需要把分布式汽车的本地数据上传到一个集中的节点上,可以有效地保护用户隐私。车联网场景下典型的联邦学习的框架由一个服务器和多个汽车端组成。每轮训练中,由服务器将当前全局模型下发到各汽车端,汽车端在本地利用自身的数据进行模型训练,然后仅将模型更新的部分上传到服务器信息交换区域,并由服务器聚合所有汽车端的模型,形成新的全局模型,该过程迭代多轮直到模型达到预设的精度或训练轮数。聚合的方法通常采用fedavg(federatedaveraging),fedavg将权重定义为数据量比例,即数据量越大的汽车端权重越大,对全局模型的贡献越高。然而,fl的主要缺点是每个汽车端都需要运行完整的机器学习模型,而资源受限的汽车端通常难以运行完整的模型。特别是,当采用深度机器学习模型时,汽车端更是无法运行。
3、分割学习(splitlearning,sl)为上述问题提供了一种有效的解决方法。在车联网场景下的分割学习中,完整的机器学习模型被分割成多个较小的网络部分,资源受限的汽车端上仅进行一部分较小网络的训练,这样很大程度上降低了汽车端资源消耗。在一个两参与方(汽车端和服务器)的分割学习中,完整的机器学习模型被分割成两部分和,并分别在汽车端和服务器完成初始化,其中是汽车端侧模型,包括从输入层到被分割层之间的连续的网络层;是服务器侧模型,包括从分割层之后的网络层到输出层之间的连续的网络层。汽车端使用本地数据在局部模型上进行前向传播得到中间结果,并将中间结果与数据标签发送给服务器。服务器用中间结果在局部模型上进行前向传播得到整个模型的输出。服务器根据输出和数据标签计算损失,在上反向传播计算对的梯度和对中间结果的梯度。服务器将对中间结果的梯度发送给汽车端,汽车端在上反向传播计算对的梯度。在上述情景中,的输出结果与的输出结果是相同的,因而损失是相同的,根据求微分的链式法则可知,与也是相同的,因而这样的训练流程与通常的训练方式会得到相同的结果。然而,由于跨多个汽车端进行基于接力的训练,分割学习的训练效率远比联邦学习低。
4、联邦分割学习结合了联邦学习和分割学习,缓解了它们固有的缺点。在车联网场景下的联邦分割学习中,完整的机器学习模型被分成两部分:汽车端侧模型和服务器侧模型。在神经网络中,汽车端侧模型为从输入层到分割层的若干连续的层组成的模型,服务器侧模型为从分割层到输出层的若干连续的层组成的模型。在开始训练前,多个分布式汽车端持有本地数据以及汽车端侧模型,服务器对于每一个汽车端都持有一份服务器侧模型。开始训练后,所有汽车端都在其汽车端侧模型上并行执行前向传播,并将中间结果传递到服务器。然后,服务器在其服务器侧模型上并行地处理每个汽车端的前向传播、反向传播并更新服务器侧模型。然后服务器将损失函数对中间结果的梯度回传到各自的汽车端并在汽车端侧模型上进行反向传播并更新模型。在经过一定周期的训练之后,汽车端将本地的汽车端侧模型发送给服务器,由服务器帮助完成汽车端侧模型的聚合,而服务器侧的模型由于是集中在服务器上的,直接由服务器完成聚合。这样训练、聚合的过程迭代多次直到模型训练达到预设的精度或预设的训练时间。
5、在车联网物体识别中,参与联邦分割学习的节点为多个车联网汽车端和云服务器,这些节点都具备算力和通信能力。其中,云服务器节点具备高算力和高通信能力,因此云服务器作为联邦分割学习的服务器。多个车联网汽车端即为多个分布式的节点。汽车端通过2g/3g/4g/5g、nb-iot、wifi与云服务器进行通信,完成信息的发送和接收。在这样的场景下,一个重要的问题是不同汽车端的本地数据往往是非独立同分布(non-iid,non-independentandidenticallydistributed)的,(例如,有些车辆是进行长途运输的,那么这些车辆收集到的数据可能以山川树木为主。另外有些车辆经常游走于闹市之中,那么这些车辆收集到的数据可能以行人、建筑等为主)这会使得传统使用fedavg聚合模型的联邦分割学习收敛速度下降。另外,在服务器端对于每个汽车端均维护一个服务器侧模型,这对于服务器的算力、存储资源也是巨大的挑战。因此,如何在车辆网物体识别的联邦分割学习场景下,解决由数据non-iid带来的收敛速度和收敛精度下降以及由汽车端数量过多带来的服务器资源不足问题,进一步提高用户体验,成为一个亟待解决的问题。
6、需要说明的是,在上述背景技术部分公开的信息仅用于加强对本技术的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、为了对披露的实施例的一些方面有基本的理解,下面给出了简单的概括。所述概括不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围,而是作为后面的详细说明的序言。
2、本公开实施例提供了车联网环境下基于聚类的高效联邦分割学习方法及装置,解决在车联网场景下联邦分割学习中由于数据非独立同分布带来的收敛速度和收敛精度下降问题以及由于汽车端数量过多带来的服务器资源不足问题。
3、在一些实施例中,所述方法包括:
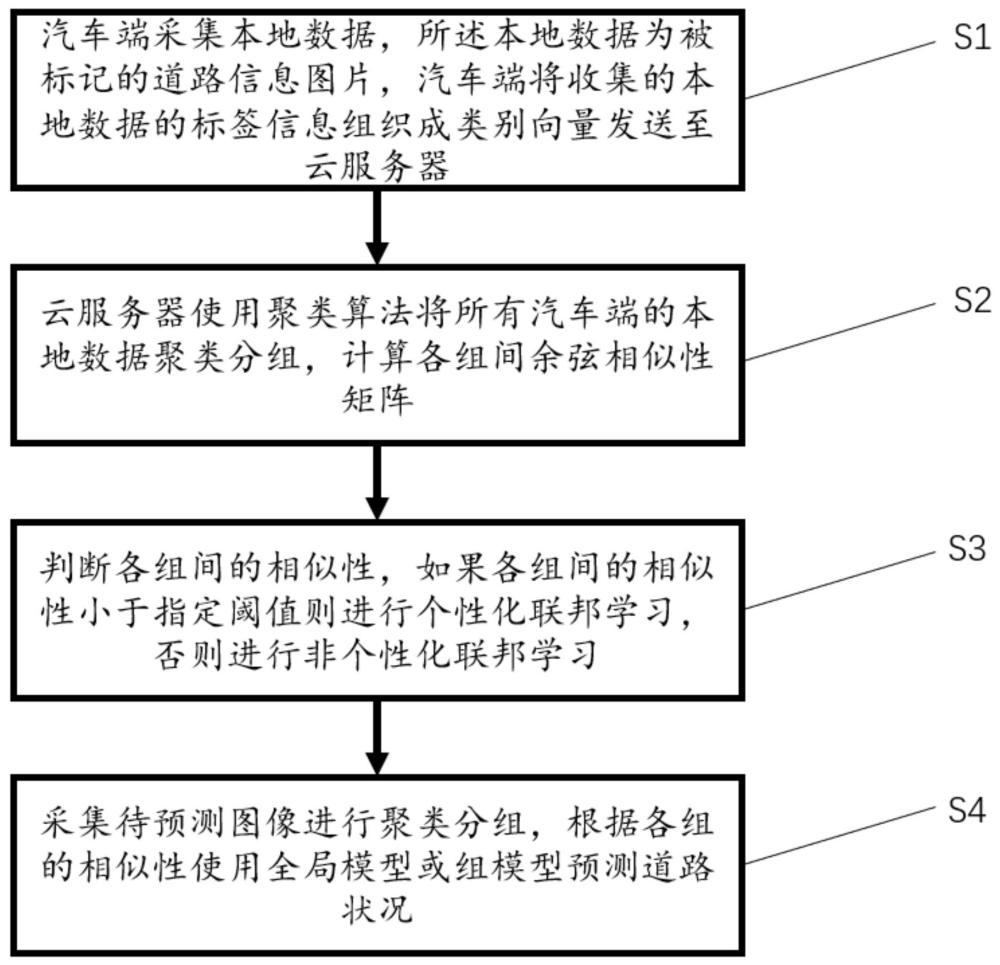
4、汽车端采集本地数据,所述本地数据为被标记的道路信息图片,汽车端将收集的本地数据的标签信息组织成类别向量发送至云服务器;
5、云服务器使用聚类算法将所有汽车端的本地数据聚类分组,计算各组间余弦相似性矩阵;
6、判断各组间的相似性,如果各组间的相似性小于指定阈值则进行个性化联邦学习,否则进行非个性化联邦学习;
7、所述非个性化联邦学习根据分组结果训练一个全局模型,所述全局模型包括汽车端侧全局模型和服务器侧全局模型;将各组将训练后的汽车端侧模型在组内聚合,将组内聚合的模型再进行组间聚合为汽车端侧全局模型,服务器将训练后的服务器侧模型聚合为服务器侧全局模型;所述个性化联邦学习根据分组结果为每个组训练一个组模型,每个组模型包括该组数据训练的汽车端侧组模型和服务器侧组模型,所述组模型训练的目标函数加入需要训练的参数和基准模型的参数之差的二范式;
8、采集待预测图像进行聚类分组,根据各组的相似性使用全局模型或组模型预测道路状况。
9、优选的,所述聚类算法为kmeans聚类,使用余弦相似度作为相似性度量。
10、优选的,所述非个性化联邦学习流程如下:
11、s3011:服务器初始化服务器侧组模型,并将汽车端侧全局模型发送给所有汽车端节点,汽车端节点收到模型初始化本地汽车端侧模型;
12、s3012:汽车端节点采样部分本地数据在本地模型进行前向传播,计算中间结果,这里中间结果是本地模型的输出,并将中间结果和数据的标签发送给服务器;
13、s3013:服务器接收到来自汽车端节点的中间结果,在该汽车端节点对应组的服务器侧模型上进行前向传播计算模型预测的数据标签,计算全部损失,并进行反向传播更新服务器侧模型的参数;服务器计算中间结果的梯度,并发送回汽车端节点;
14、s3014:汽车端节点接收到中间结果梯度后,进行反向传播,更新汽车端侧模型的参数;如果汽车端节点还有未训练的数据,则继续采样部分数据在更新后的汽车端侧模型上进行前向传播,并将中间结果发送给服务器,迭代s3013-s3014至汽车端节点无剩余数据未被训练;
15、s3015:汽车端节点将更新后的汽车端侧模型发送到服务器,服务器在组内对汽车端侧模型进行聚合,形成组内模型,将组内模型跨组聚合为汽车端侧全局模型;服务器对服务器侧模型的分类器层和其他层分别进行聚合,生成服务器侧全局模型。
16、优选的,服务器对汽车端侧的模型在组内使用fedavg聚合为组内模型,将组内模型跨组使用fedavg聚合为汽车端侧全局模型;
17、服务器侧模型对模型的分类器层使用基于能量比率的聚合方法聚合,对模型的其他层使用fedavg聚合。
18、优选的,服务器侧模型对模型的分类器层使用基于能量比率的聚合方法的聚合后,分类器参数矩阵第列的参数计算公式如下:
19、,
20、,
21、其中,表示本地数据聚类的组数,表示第组的模型分类器层参数矩阵的第列的能量比率,表示第组的模型分类器层参数矩阵的第列的能量比率,表示第组的模型分类器层参数矩阵的第列,表示第组的模型分类器层参数矩阵的第行第列的参数,表示第组的模型分类器层参数矩阵的第行第列的参数,和表示分类器的模型参数矩阵的维数,是绝对值函数;
22、聚合后分类器参数向量第维的参数计算公式如下:
23、,
24、,
25、其中,表示第组的模型分类器层参数向量的第维的能量比率,表示第组的模型分类器层参数向量的第维的能量比率,表示第组的模型分类器层参数向量的第维,表示第组的模型分类器层参数向量的第维,和表示分类器的模型参数矩阵的维数,是绝对值函数。
26、优选的,所述个性化联邦学习流程如下:
27、s3021:服务器为每个组生成基准模型,服务器将汽车端侧模型和对应的汽车端侧基准模型发送给所有属于该组的汽车端节点;
28、s3022:汽车端节点初始化本地汽车端侧模型,并从本地数据中采样部分数据进行前向传播,记录中间结果,并将中间结果和数据的标签发送给服务器;
29、s3023:服务器接收到来自汽车端节点的中间结果,在该汽车端节点对应组的服务器侧模型上进行前向传播计算模型预测的数据标签,计算全部损失,并进行反向传播更新服务器侧模型的参数;服务器计算中间结果的梯度,并发送回汽车端节点;
30、s3024:汽车端节点接收到中间结果梯度后,进行反向传播,更新汽车端侧模型的参数;如果汽车端节点还有未训练的数据,则继续采样部分数据在更新后的汽车端侧模型上进行前向传播,并将中间结果发送给服务器,迭代s3023-s3024至汽车端节点无剩余数据未被训练;
31、s3025:汽车端节点将汽车端侧模型发送到服务器,服务器在组内对汽车端侧模型进行聚合得到汽车端侧组模型,并将聚合结果赋值给组内的每个汽车节点,服务器侧组模型取s3023中训练所得。
32、优选的,基准模型生成公式如下:
33、,
34、,
35、其中,表示组的汽车端侧组基准模型,表示组的服务器侧组基准模型,表示本地数据聚类的组数,表示组和组类别向量之间的余弦相似度,表示组的汽车端侧组模型,表示组的服务器侧组模型。
36、优选的,每个组的目标函数如下所示:
37、,
38、其中,表示组的组模型,表示第组的目标函数,表示组的基准模型,表示预测误差,表示模型的预测结果,表示真实标签,表示组的数据,是一个超参,表示正则项损失对于整体损失的比重。
39、优选的,所述个性化联邦学习中的中间结果包括本地汽车端侧模型的输出、本地数据的标签和需要训练的汽车端侧模型参数和基准模型的汽车端侧模型参数之差的二范式;
40、需要训练的汽车端侧模型参数和基准模型的汽车端侧模型参数之差的二范式,计算公式如下:
41、,
42、其中,表示本地汽车端侧模型,表示汽车端侧基准模型;
43、个性化联邦学习全部损失公式如下:
44、,
45、其中,表示模型预测的数据标签,表示真实数据标签,为训练的服务器侧模型参数和基准模型的服务器侧模型参数之差的二范式,计算公式如下:
46、,
47、其中,为超参。
48、在一些实施例中,所述装置包括:处理器和存储有程序指令的存储器,所述处理器被配置为在运行所述程序指令时,执行所述的车联网环境下基于聚类的高效联邦分割学习方法。
49、本公开实施例提供的车联网环境下基于聚类的高效联邦分割学习方法及装置,可以实现以下技术效果:
50、在车联网物体识别场景中,每个汽车端在训练前将本地数据的类别信息加密发送给服务器。服务器根据这些类别信息使用聚类算法将所有的汽车端聚成若干个类,也即分成了若干个组。服务器对于每一个组维护一个服务器侧模型。这样对于每一个组维护一个服务器侧模型,在降低了服务器的算力、存储压力的同时,也可以有效处理数据非独立同分布所带来的问题。由于同组内的汽车端共享一个服务器侧模型,因而其对服务器侧模型的使用是互斥的,即同一时间同一个组内只能有一个汽车端可以使用到该组的服务器侧模型。而不同组之间的汽车端因为不共享服务器侧模型,可以同时使用到各自组的服务器侧模型。这种组内串行,组间并行的方式虽然一定程度上降低了并行度,但由于组内的数据分布接近,因而对提高模型训练的收敛速度是有益的。
51、在此基础上,通过聚类的结果估计整个系统的数据异构性程度,系统自适应地选择非个性化聚类联邦分割学习或个性化聚类联邦分割学习。
52、非个性化聚类联邦分割学习在整个系统的数据异构性较低时运行,它生成一个所有汽车端共享的全局模型;个性化聚类联邦分割学习在整个系统的数据异构性较高时运行。当聚类结果显示各个组之间的相似性较低时,一个全局模型难以高效地处理如此异构的数据,因而为每个组生成一个适合于该组的模型是更好的选择。
53、以上的总体描述和下文中的描述仅是示例性和解释性的,不用于限制本技术。
本文地址:https://www.jishuxx.com/zhuanli/20241021/319631.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。