一种多模态大模型驱动的视频理解与检索方法
- 国知局
- 2024-10-21 14:52:41
本发明涉及视频检索,具体涉及一种多模态大模型驱动的视频理解与检索方法。
背景技术:
1、随着视频数据的增长,以及视频在社交媒体、娱乐、监控和教育等领域的广泛应用,研究如何高效地理解和检索视频内容,能使得系统从海量数据中提取有价值信息。视频理解和检索技术在近年来取得了长足的进步,特别是深度学习和大模型技术的引入,使得这些技术在处理复杂视频内容时表现出更高的准确性和鲁棒性。例如gpt-4v等大模型通过大规模的预训练,能够从图片帧中学习到更丰富和抽象的表示,提升了视频理解和检索的性能。
2、语音识别系统(asr)的发展将语音转化为文本,使得系统能够处理和理解用户的语音输入,与文本数据进行有效结合。例如百度开发的deepspeech、openai发布的whisper等。语音识别系统能够抽取每个视频中的语音,并将语音转化成文字,对文字进行切分。
3、大规模预训练模型,如transformer模型和bert(bidirectional encoderrepresentations from transformers)模型,在自然语言处理中的成功,促使其在多模态理解的应用中也取得了进步。sbert(sentence-bert)模型是bert模型的变体,通过对双塔架构(siamese network)和三元组损失函数(triplet loss)的优化,使得其在计算句子对之间的相似度时更加高效。将sbert模型应用于视频理解的一个常见方法是将视频切片转化为文本描述,然后利用sbert模型计算每个文本描述的嵌入向量。
4、同时,结合了图像和文本的多模态模型目前也正取得长足的发展,例如openai发布的clip模型,其通过学习如何对文本和图像进行对比,从而实现跨模态的理解。在视频理解领域,通过视频帧取样和视觉-文本模型(如gpt-4v)生成图像描述,可以实现对视频内容的自动理解和描述。
5、在视频检索领域,可将视频内容转换为特征向量,并使用高效的索引结构(如倒排索引、kd树、lsh等)来加速检索过程。同时,对于视频的特征匹配与相似度计算,可以使用相似度度量(如欧氏距离、余弦相似度)计算查询特征与视频库中特征的相似度,从而找到与查询最相似的视频。
6、现有技术中存在一些视频检索方法,例如,现有技术一通过构建深度神经网络模型,将提取的视频特征映射到语义空间中,生成语义向量;现有技术二通过大语言模型对旁白音频进行处理得到操作步骤文本,对操作步骤文本进行逐帧相似度计算,在每个视频片段中确定出目标视频片段;现有技术三基于注意力与知识蒸馏进行视频检索;现有技术四基于双分支动态蒸馏学习进行跨模态视频检索,从一个新的角度来处理跨模态视频检索。但上面这些现有技术也面临以下问题:1)现有的方法依赖于对大规模人工标注的视频数据的训练,难以扩展到海量的视频数据。2)现有的视频检索系统在语义理解和场景识别方面仍存在不足,特别是在复杂场景和抽象概念的理解上。常规的特征提取方法往往无法捕捉高层次的语义信息。3)视频数据本质上是多模态的,包含视觉与听觉等信息。如何有效地融合这些多模态信息进行检索是一个重大挑战。4)多种检索方法在不同的侧重点上对视频特征进行检索,如何有效地融合这些不同的检索方法并进行统一检索同样是一个重大挑战。
技术实现思路
1、为解决上述技术问题,本发明提供了一种多模态大模型驱动的视频理解与检索方法。本发明进行视频理解时基于以下两个方面:一方面抽取视频中的语音并将其转化为文字,然后对文字进行切分并记录标签,使得系统能融合多模态的信息进行理解;另一方面对视频进行帧采样,并利用多模态大模型将帧组转换为文字描述,增强了系统对于复杂语义理解和场景理解的能力。本发明进行视频检索时基于以下两个方面:一是对于每个视频片段,使用sbert模型计算其向量并进行向量检索;二是对视频片段中的文字进行全文检索,本发明结合这几种检索方法进行混合检索,融合不同方法的优点并向返回最优结果。
2、为解决上述技术问题,本发明采用如下技术方案:
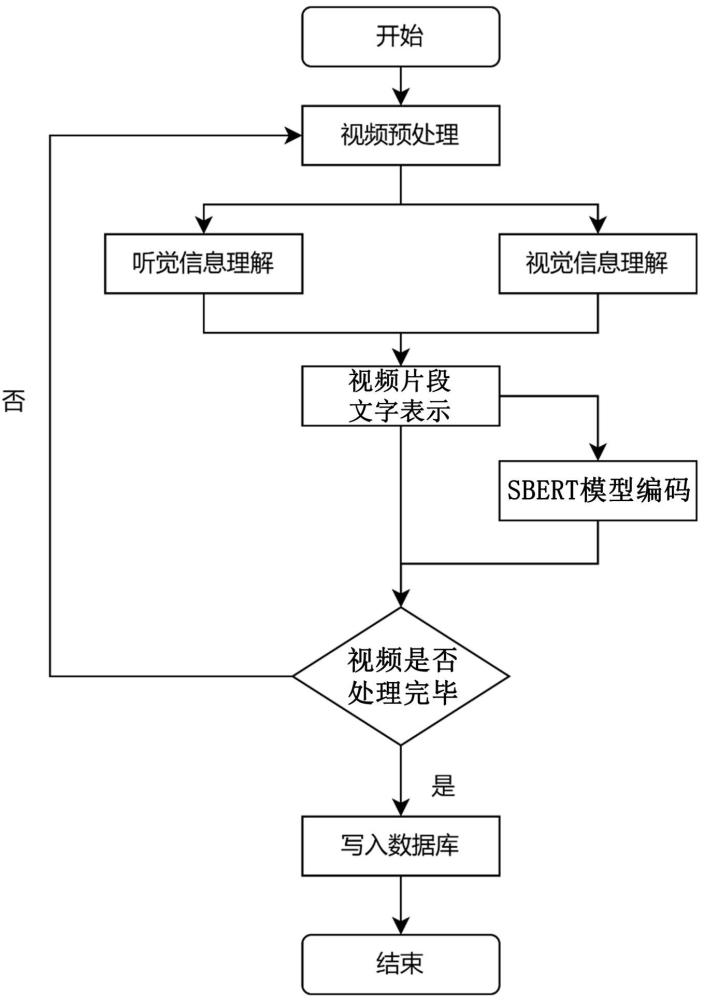
3、一种多模态大模型驱动的视频理解与检索方法,包括以下步骤:
4、步骤一,对待检索的视频文件,进行预处理:
5、对视频文件进行分割,得到视频片段;将每个视频片段按照设定频率进行帧采样,形成视频片段对应的帧组;对无音频的视频片段添加无声音的音轨;
6、步骤二,对每个视频片段抽取音频文件,使用预训练的语音识别模型将音频文件中的语音转化成文字,作为视频片段的听觉元素文字表示;
7、步骤三,通过预训练的多模态大模型,将视频片段对应的帧组中各帧图像的图像信息转为文字,作为视频片段的视觉元素文字表示;
8、步骤四,将视频片段的听觉元素文字表示和视频片段的视觉元素文字表示进行合并,得到视频片段的文字表示,通过sbert模型计算每个视频片段的文字表示的向量,得到视频片段编码向量;将视频片段编码向量和视频片段的文字表示存入数据库中,完成视频的理解过程;
9、步骤五,通过自然语言形式的查询语句对数据库中的视频片段进行查询:通过sbert模型计算查询语句的向量,通过查询语句向量与数据库中的视频片段编码向量进行向量检索;将查询语句输入到大语言模型,解析查询语句中的关键词,通过关键词以及数据库中的视频片段的文字表示进行全文检索;使用倒数排序融合将向量检索的结果与全文检索的结果进行综合排序,给出最终的检索结果,完成视频的检索过程。
10、进一步地,图像的图像信息包括:
11、语义信息,包括通过物体检测识别出的图像中的物体、通过场景分类识别出的图像中的场景类型,以及通过行为识别分析出的图像中的人物行为;
12、颜色信息,是指图像中每个元素的颜色;
13、纹理信息,是指图像中每个元素的表面特征的统计描述;
14、形状信息,是指图像中每个元素的轮廓和结构;
15、空间信息,包括位置信息和构图信息;所述位置信息是指各元素在图像中的具体位置;所述构图信息是指图像中各元素的排列和布局;
16、所述元素包括物体、人物和场景。
17、进一步地,步骤五中,所述通过关键词以及数据库中的视频片段的文字表示进行全文检索,具体包括:
18、对数据库中的视频片段的文字表示构建倒排索引表;进行全文检索时,对关键词进行分词后,在所述倒排索引表中进行查询。
19、与现有技术相比,本发明的有益技术效果是:
20、1.相比现有的视频检索方法需要大规模人工标注的视频数据,本发明使用多模态大模型理解视频内容,不需要大规模人工标注的视频数据,泛化性更高,更容易扩展到真实世界海量的视频数据。
21、2.本发明使用预训练的语音识别模型将视频的音频转为文字形式,从听觉角度理解视频。
22、3.本发明对视频进行帧采样并利用多模态大模型转为文字描述,从视觉角度理解视频,增强了对视频复杂语义的理解,以及对场景的理解,检索效果更好,并且具有一定的可解释能力。
23、4.本发明综合利用视频的视觉元素与听觉元素进行多模态理解,并有效融合不同的检索方法进行混合检索,提高检索的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20241021/319641.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表