一种揭示喀斯特地区生态服务的非线性影响的方法与流程
- 国知局
- 2024-11-06 15:05:20
本发明涉及电数据处理,尤其涉及一种揭示喀斯特地区生态服务的非线性影响的方法。
背景技术:
1、喀斯特地区是一个复杂的地域系统,有限的自然资源、脆弱的生态环境、落后的社会经济以及紧张的人地关系一直制约着区域发展。现有技术中,地区的人类活动、气候变化、自然地形等驱动因素数据对主要生态系统服务(碳固定、生境质量、净初级生产力、土壤保持和产水量)存在较强的非线性关系,而且数据种类多、数据冗余量大,导致生态系统服务的非线性影响分析的精度低、适应性差。只有得到准确的生态系统服务的非线性影响关系才能够为类似地理环境的区域提供了可借鉴的研究框架和方法。
2、因此,如何提高生态系统服务的非线性影响分析的精度和适应性,是目前有待解决的技术问题。
技术实现思路
1、本发明的目的是为了解决现有技术中生态系统服务的非线性影响分析的精度低和适应性差问题,而提出的一种揭示喀斯特地区生态服务的非线性影响的方法。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种揭示喀斯特地区生态服务的非线性影响的方法,包括:
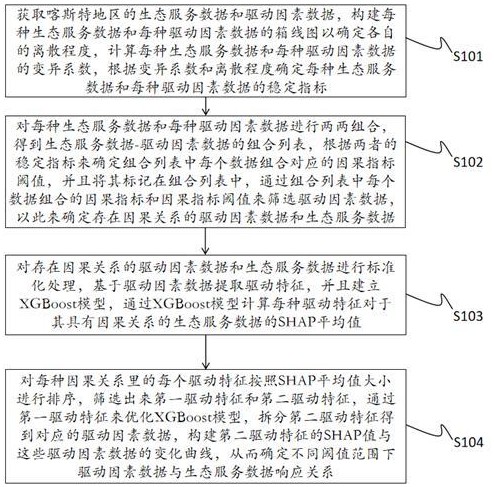
4、获取喀斯特地区的生态系统服务数据和驱动因素数据,构建每种生态系统服务数据和每种驱动因素数据的箱线图以确定各自的离散程度,计算每种生态系统服务数据和每种驱动因素数据的变异系数,根据变异系数和离散程度确定每种生态系统服务数据和每种驱动因素数据的稳定指标;
5、对每种生态系统服务数据和每种驱动因素数据进行两两组合,得到生态系统服务数据-驱动因素数据的组合列表,根据两者的稳定指标来确定组合列表中每个数据组合对应的因果指标阈值,并且将其标记在组合列表中,通过组合列表中每个数据组合的因果指标和因果指标阈值来筛选驱动因素数据,以此来确定存在因果关系的驱动因素数据和生态系统服务数据;
6、对存在因果关系的驱动因素数据和生态系统服务数据进行标准化处理,基于驱动因素数据提取驱动特征,并且建立xgboost模型,通过xgboost模型计算每种驱动特征对于其具有因果关系的生态系统服务数据的shap平均值;
7、对每种因果关系里的每个驱动特征按照shap平均值大小进行排序,筛选出来第一驱动特征和第二驱动特征,通过第一驱动特征来优化xgboost模型,拆分第二驱动特征得到对应的驱动因素数据,构建第二驱动特征的shap值与这些驱动因素数据的变化曲线,从而确定不同阈值范围下驱动因素数据与生态系统服务数据响应关系。
8、本技术一些实施例中,根据变异系数和离散程度确定每种生态系统服务数据和每种驱动因素数据的稳定指标,包括:
9、;
10、其中,为生态系统服务数据或驱动因素数据的稳定指标,、分别为变异系数和离散程度的稳定转换系数,为变异系数,为箱线图中的离散程度,iqr为箱线图中的四分位距,为箱线图中的上下四分位范围之差,为中的较大者,为预设常数。
11、本技术一些实施例中,根据两者的稳定指标来确定组合列表中每个数据组合对应的因果指标阈值,包括:
12、每种生态系统服务数据和每种驱动因素数据均各自对应有一个稳定指标,分别记作生态系统服务数据和驱动因素数据对应的稳定指标为第一稳定指标和第二稳定指标;
13、配置组合列表中每个数据组合的原始因果指标阈值,计算第一稳定指标和第二稳定指标的加权平均值,并且分别计算第一稳定指标到加权平均值的距离、第二稳定指标到加权平均值的距离,将两种距离中的较小距离的稳定指标作为接近指标,计算接近指标与加权平均值两者的平均值,再通过该平均值来调整原始因果指标阈值,经过调整后的原始因果指标阈值作为每个数据组合对应的因果指标阈值。
14、本技术一些实施例中,通过组合列表中每个数据组合的因果指标和因果指标阈值来筛选驱动因素数据,以此来确定存在因果关系的驱动因素数据和生态系统服务数据,包括:
15、将每个数据组合中的驱动因素数据和生态系统服务数据分别映射到因状态空间和果状态空间;
16、根据因状态空间和果状态空间的数据样本点来确定每个数据组合的因果指标,因为驱动因素数据,果为生态系统服务数据;
17、若某个数据组合的因果指标大于因果指标阈值,则将该数据组合保留下来;
18、否则,剔除掉该数据组合;
19、以此来完成对驱动因素数据的筛选,保留下来的数据组合为存在因果关系的驱动因素数据和生态系统服务数据。
20、本技术一些实施例中,通过xgboost模型计算每种驱动特征对于其具有因果关系的生态系统服务数据的shap平均值,包括:
21、将验证集的生态系统服务数据和驱动因素数据划分成多个样本,计算每个样本中的每个驱动特征的shap值;
22、通过xgboost模型计算在某个样本中生态系统服务数据的第一预测值,遮蔽某一个特征,再通过xgboost模型计算在该样本中缺失了一个特征的生态系统服务数据的第二预测值,根据第一预测值与第二预测值之差来确定该特征在此样本中的预测贡献值,预测贡献值为该样本中该特征的shap值;
23、计算所有样本中的驱动特征的shap值,以此来得到每个驱动特征的shap平均值。
24、本技术一些实施例中,对每种因果关系里的每个驱动特征按照shap平均值大小进行排序,筛选出来第一驱动特征和第二驱动特征,包括:
25、根据每种因果关系里的生态系统服务数据的种类来设置一个排名次序,根据排名次序将按照shap平均值大小进行排序的驱动特征中前若干个驱动特征作为第二驱动特征,将其他排在排名次序后面的多个驱动特征作为第一驱动特征。
26、本技术一些实施例中,通过第一驱动特征来优化xgboost模型,包括:
27、;
28、其中,为第i次优化后的损失函数,为第i-1次优化后的损失函数,n为第i次优化的第一驱动特征的数量,为第i次优化的第j个驱动特征的优化权重,为第i次优化的第j个驱动特征的shap值,为第i次优化的补偿常数。
29、本技术一些实施例中,构建第二驱动特征的shap值与这些驱动因素数据的变化曲线,从而确定不同阈值范围下驱动因素数据与生态系统服务数据响应关系,包括:
30、通过优化后的xgboost模型来构建第二驱动特征的shap值与其驱动因素数据的变化曲线,在变化曲线中确定出多个拐点,根据拐点处的斜率的绝对值来确定两侧距离,在两侧距离内,选择多个标记点,通过多个标记点中相邻两个标记点的斜率变化来筛选出斜率变化较高的标记点,并且根据筛选后的标记点来确定驱动因素数据不同阈值范围,截取这些阈值范围对应的变化曲线,从而确定不同阈值范围下驱动因素数据与生态系统服务数据响应关系。
31、通过应用以上方案,获取喀斯特地区的生态系统服务数据和驱动因素数据,构建每种生态系统服务数据和每种驱动因素数据的箱线图以确定各自的离散程度,计算每种生态系统服务数据和每种驱动因素数据的变异系数,根据变异系数和离散程度确定每种生态系统服务数据和每种驱动因素数据的稳定指标;对每种生态系统服务数据和每种驱动因素数据进行两两组合,得到生态系统服务数据-驱动因素数据的组合列表,根据两者的稳定指标来确定组合列表中每个数据组合对应的因果指标阈值,并且将其标记在组合列表中,通过组合列表中每个数据组合的因果指标和因果指标阈值来筛选驱动因素数据,以此来确定存在因果关系的驱动因素数据和生态系统服务数据;对存在因果关系的驱动因素数据和生态系统服务数据进行标准化处理,基于驱动因素数据提取驱动特征,并且建立xgboost模型,通过xgboost模型计算每种驱动特征对于其具有因果关系的生态系统服务数据的shap平均值;对每种因果关系里的每个驱动特征按照shap平均值大小进行排序,筛选出来第一驱动特征和第二驱动特征,通过第一驱动特征来优化xgboost模型,拆分第二驱动特征得到对应的驱动因素数据,构建第二驱动特征的shap值与这些驱动因素数据的变化曲线,从而确定不同阈值范围下驱动因素数据与生态系统服务数据响应关系。本技术根据两者的稳定指标来确定组合列表中每个数据组合对应的因果指标阈值,根据两类数据的稳定性情况来设置一个合理的因果指标阈值,从而准确合理的筛选具有较强因果关系的驱动因素数据。确定了不同驱动特征的shap值,并且根据shap值来优化xgboost模型以及构建驱动因素数据与生态系统服务数据响应关系,提高了生态系统服务数据的非线性影响关系分析的准确性和适应性。
本文地址:https://www.jishuxx.com/zhuanli/20241106/325229.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表