一种可验证纵向联邦学习隐私保护方法
- 国知局
- 2024-11-21 11:30:27
本发明涉及一种可验证纵向联邦学习隐私保护方法,属于联邦学习。
背景技术:
1、近年来,随着对数据隐私保护的重视,数据以孤岛的形式存在于个体之间,严重影响了优质数据的使用价值。联邦学习的提出,旨在实现数据流通中的隐私保护。联邦学习允许多个参与方共同训练一个全局模型,并将数据保留在本地,任何一个参与方的训练数据与训练过程都是不可见的。在纵向联邦学习中,通常是由一个主动方发起,多个被动方协助,协同训练一个全局模型。
2、纵向联邦学习为解决数据孤岛提供了技术思路。然而,当前纵向联邦学习仍然面临参与方本地中间结果无法验证的挑战,例如聚合服务器不诚实的聚合本地模型或者伪造全局模型和参与方提交不正确的中间结果来污染全局模型,进而造成模型训练性能较低。
3、因此,如何验证被动方的本地模型对全局模型的贡献值以此来提高模型准确率已经成为亟需解决的问题。
技术实现思路
1、本发明的目的是为了解决传统纵向联邦学习的被动方不可验证而导致的模型性能低的问题,提出了一种可验证纵向联邦学习隐私保护方法。
2、本发明的目的是通过以下技术方案实现的:
3、本发明的一种可验证纵向联邦学习隐私保护方法,应用于包括成员节点的参与方z、可信第三方的纵向联邦模型训练中,包括以下步骤:
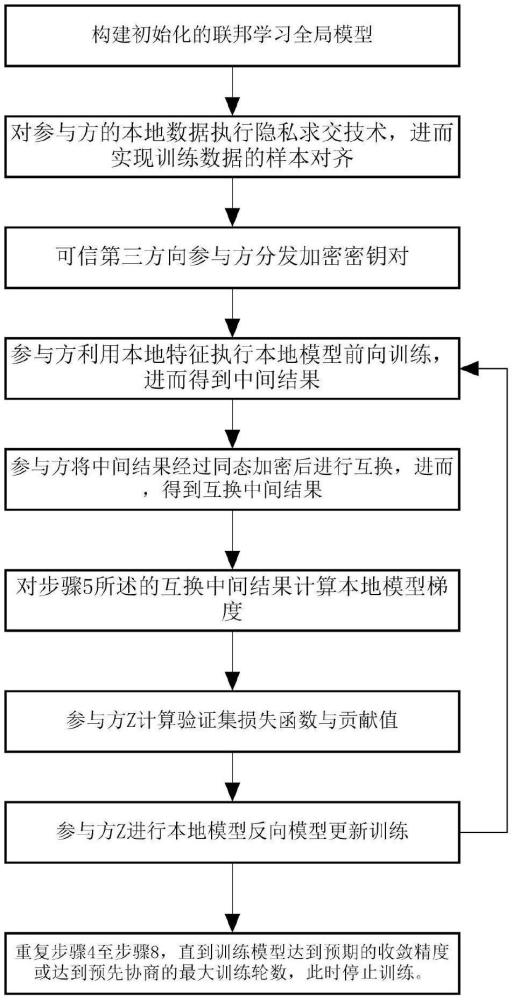
4、步骤1:构建初始化的联邦学习全局模型,对成员节点的参与方z、可信第三方的节点参数进行初始化。其中参与方z包括主动方a和被动方b;可信第三方用于生成密钥对并进行密钥分发和加解密。
5、步骤2:对参与方z的本地数据执行隐私求交,进而实现训练数据的样本对齐。
6、步骤3:可信第三方向参与方z分发加密密钥对,用于步骤5.1加密参与方z获得的中间结果;
7、步骤4:参与方z利用本地特征执行本地模型前向训练,进而得到中间结果。
8、步骤4.1:参与方z对本地模型训练参数θz进行初始化。
9、步骤4.2:参与方z对参与方z本地训练的数据集进行本地模型前向训练。如式(1)所示。
10、yz=xzθz (1)
11、其中,xz表示参与方z拥有的本地数据;θz表示参与z拥有的本地模型参数,其中参与方z∈{主动方a,被动方b}。
12、步骤5:参与方z将中间结果经过同态加密后进行互换,进而,得到互换中间结果。
13、步骤5.1:参与方z对步骤4所述的中间结果进行同态加密,计算得到加密的中间结果||θzxz||,其中主动方a获得加密后的中间结果||θaxa||;被动方b获得加密后的中间结果||θbxb||。
14、步骤5.2:主动方a与被动方b对加密后的中间结果进行交换,即主动方a发送‖θaxa-y‖给被动方b,被动方b发送‖θbxb‖给主动方a;其中y表示样本的标签值。
15、步骤6:对步骤5所述的互换中间结果计算本地模型梯度。
16、步骤6.1:利用交叉熵损失函数计算方法分别计算主动方a和被动方b损失函数为loss(θa)和loss(θb)。
17、步骤6.2:主动方a和被动方b根据损失函数计算梯度
18、步骤6.3:参与方z为互换中间结果添加掩码mz,发送至可信第三方;其中参与方z∈{主动方a,被动方b}。
19、步骤6.4:可信第三方进行解密得到并发送给参与方z,其中参与方z∈{主动方a,被动方b}。
20、步骤7:参与方z计算验证集损失函数与贡献值。
21、步骤7.1:参与方z计算在验证集v上的损失函数lossv(θz)与梯度其中参与方z∈{主动方a,被动方b}。
22、步骤7.2:参与方z依据夏普利值近似公式计算本轮次贡献值φt,z,如式(2)所示,并发送至主动方a。
23、
24、其中gt表示全局梯度,diag()表示创建对角矩阵,表示所有验证集的集合,e表示单位矩阵。其中参与方z∈{主动方a,被动方b}。
25、步骤8:参与方z进行本地模型反向模型更新训练。
26、步骤8.1:主动方a依据贡献值,加权计算参与方z本地模型聚合所占权重ωz,如式(3)所示。
27、
28、并将发送ωb至被动方b;其中,参与方z∈{主动方a,被动方b}。
29、步骤8.2:被动方b为自身中间结果附加权重,得到加权后的梯度值,如式(4)所示。
30、
31、步骤8.3:主动方a计算得到加权后的梯度值,如式(5)所示。
32、
33、步骤8.4:参与方z使用梯度下降算法更新本地模型参数,如式(6)所示。
34、
35、其中lr表示学习率,表示参与方z在第t轮的本地模型参数,表示参与方z在第t-1轮的本地模型参数。gt表示参与方z的全局梯度值,参与方z∈{主动方a,被动方b}。
36、步骤9:重复步骤4至步骤8,直到训练模型达到预期的收敛精度或达到预先协商的最大训练轮数,此时停止训练。从而,实现利用夏普利值的可验证纵向联邦学习。
37、有益效果:
38、1本发明评估被动方的贡献值,验证被动方提交的信息对全局模型的重要程度,并采用贡献值实现全局模型的加权聚合,降低恶意客户端对全局模型的负面影响,提高模型训练性能。
39、2本发明在各参与方协同训练的过程中,无需被动方在一个全局轮次中额外执行训练过程,极大的节省了训练的计算开销。
40、3本发明公开的纵向联邦学习隐私保护方法,针对现有纵向联邦学习中被动方的本地模型不可验证而导致模型性能低的问题,提出一种可验证纵向联邦学习隐私保护方法用于提升模型的性能。通过在训练的过程中,使用夏普利值来计算被动方的贡献值,进而验证被动方本地模型的性能,提升全局模型的准确率。
技术特征:1.一种可验证纵向联邦学习隐私保护方法,应用于包括成员节点的参与方z、可信第三方的纵向联邦模型训练中,其特征在于:包括以下步骤,
2.如权利要求1所述的一种可验证纵向联邦学习隐私保护方法,其特征在于:步骤4实现方法为,
3.如权利要求1所述的一种可验证纵向联邦学习隐私保护方法,其特征在于:步骤5实现方法为,
4.如权利要求1所述的一种可验证纵向联邦学习隐私保护方法,其特征在于:步骤6实现方法为,
5.如权利要求1所述的一种可验证纵向联邦学习隐私保护方法,其特征在于:步骤7实现方法为,
6.如权利要求1所述的一种可验证纵向联邦学习隐私保护方法,其特征在于:步骤8实现方法为,
技术总结本发明涉及一种可验证纵向联邦学习隐私保护方法,属于联邦学习技术领域。本发明包括步骤:1、构建初始化模型;2、对参与方Z实现训练数据的样本对齐;3、可信第三方向参与方Z分发加密密钥对;4、参与方Z执行本地模型前向训练得到中间结果;5、参与方Z将中间结果经过同态加密后进行互换,进而,得到互换中间结果;6、计算本地模型梯度;7、计算验证集损失函数与贡献值;8、本地模型反向模型更新训练;9、重复步骤4至步骤8,直到训练停止。本发明提出一种可验证纵向联邦学习隐私保护方法用于提升模型的性能。通过在训练的过程中,使用夏普利值来计算被动方的贡献值,进而验证被动方本地模型的性能,提升全局模型的准确率。技术研发人员:盖珂珂,王烁,韩凌乙,祝烈煌受保护的技术使用者:北京理工大学技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/331523.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表