一种智能反射面辅助的无人机应急通信方法、系统、设备和介质
- 国知局
- 2024-12-06 12:19:40
本发明属于无人机通信,特别涉及一种智能反射面辅助的无人机应急通信方法、系统、设备和介质。
背景技术:
1、自然灾害发生频率和强度的增加,给极端和动态环境下的有效通信带来了重大挑战。从地面设备(gds)到中央处理单元及时可靠的数据传输对于有效的灾害检测和响应至关重要。基于无人机的飞行灵活性,无人机通信系统在广阔地形下一般能提供视距信道,因此无人机可以被用作空中通信平台来提高地面通信系统的性能。无人机(uav)技术的创新在灾害救援中得到了有效利用。无人机(uav)可以协助地面设备进行灾害感知,具有灵活性、覆盖范围广和视距通信等优势。
2、可重构智能表面(ris)与无人机(uav)相结合最近引起了广泛关注。当可重构智能表面(ris)安装在无人机(uav)上时,它可以作为移动中继。这种创新组合允许精确操控电磁波传播,并为提升通信系统性能提供了新维度。例如已经有工作同时调整了无人机搭载智能反射面系统中的无人机的位置和智能反射面的反射系数,最终实现了最大的下行传输容量。此外,在无人机通信中,无人飞行器的推进能耗对于维持可持续的紧急通信系统至关重要。现有工作大多采用传统优化方法来优化无人机的轨迹,然而,传统优化方法在实时决策无人机飞行轨迹和可重构智能表面(ris)相位面临巨大的挑战。深度强化学习(drl)为上述挑战提供了可行的解决方案。现有采用强化学习进行优化的工作作大多采用离散drl算法来优化无人机的轨迹和可重构智能表面(ris)的相位偏移。但是用于处理轨迹和相位的离散动作算法限制了设计空间,会对其潜在性能的充分利用产生了负面影响。
3、此外,在现有的研究中,目前还没有研究无人机搭载智能反射面同时解决在需要长时间决策序列的场景中优化能效和确保单个用户服务质量的问题。解决用户之间对可重构智能表面(ris)资源的竞争问题对于保证针对单个用户的卓越服务至关重要,这是很多研究忽视的问题。针对无人机搭载智能反射面系统辅助多个用户实现应急通信的场景,如何满足快速决策的需求。考虑到地面设备的移动性,如何设计无人机的轨迹使得系统的能源效率最高。考虑到所有地面设备对可重构智能表面(ris)资源的竞争问题,如何设计智能反射面的相位,保证所有地面用户的服务质量(qos)。
4、综上分析,现有技术存在的不足在于:
5、(1)现有技术只考虑无人机搭载智能反射面网络的通信问题,而实际上无人机的推进能耗对于无人机都非常重要,仅考虑通信性能的无人机系统很难适应极端环境下的应急通信。
6、(2)现有技术没有考虑到所有地面设备对可重构智能表面(ris)资源的竞争问题,无法保证每一个地面用户的个体服务质量。
7、(3)现有的优化方法难以适应复杂的场景,无法解决所提出的联合轨迹与相位设计优化问题。
8、公开号为cn113873575b的专利申请文件公开了智能反射面辅助的非正交多址无人机空地通信网络节能优化方法,通过一种智能反射面辅助的非正交多址无人机空地通信网络节能优化方法有效降低无人机的发射功率,提高无人机的续航能力,节省能量。但其可重构智能表面(ris)放置在noma远用户旁边,使得可重构智能表面(ris)这一中继移动性很差,不能满足移动场景的需求。
9、公开号为cn117596616a的专利申请文件公开了一种智能反射面辅助的上行noma无人机网络能效优化的方法,通过一种智能反射面辅助的上行noma无人机网络能效优化的方法,实现智能反射面辅助的上行noma无人机网络的最大能效。但其优化方法为传统优化,采用交替优化来优化两个子问题。但由于优化问题的复杂度高和场景的动态性,无法用数学方法推理出低复杂度的最优解方案,实现多用户动态快速服务决策。
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种智能反射面辅助的无人机应急通信方法,通过无人机携带智能反射面系统(uav-ris)辅助应急场景上行通信,并提出了一种分层近端策略优化(h-ppo)算法来同时优化无人机的飞行轨迹以及智能反射面的相位,解决了无人机轨迹和智能反射面的相移的复杂联合优化问题,达到了提高系统的能源效率的目标,同时有效地保证所有地面设备的服务质量(qos)的需求;本发明还提供了实现上述方法的系统、设备和介质。
2、为了实现上述目的,本发明采取的技术方案是:
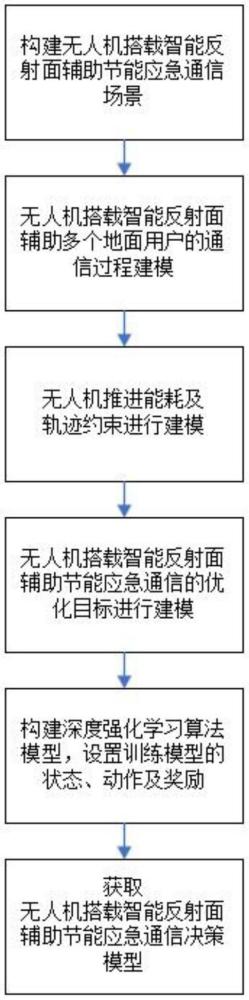
3、一种智能反射面辅助的无人机应急通信方法,包括以下步骤:
4、步骤1,构建无人机搭载智能反射面辅助节能应急通信场景;
5、步骤2,对步骤1构建的无人机搭载智能反射面辅助节能应急通信场景中的无人机携带智能反射面系统(uav-ris)辅助多个地面设备的通信过程进行建模;
6、步骤3,对无人机推进能耗进行建模;
7、步骤4,结合步骤2的无人机搭载智能反射面辅助节能应急通信场景中的无人机携带智能反射面系统(uav-ris)辅助多个地面设备的通信过程以及步骤3的无人机推进能耗模型,对最终能耗比的优化目标进行建模,构建模型求解时的目标函数;
8、步骤5,根据步骤4提出的优化目标构建深度强化学习算法模型;
9、步骤6,根据步骤5的深度强化学习算法模型构建深度强化学习训练模型,结合步骤1的无人机搭载智能反射面辅助节能应急通信场景和步骤4的目标函数,设置深度强化学习训练模型的状态空间、动作空间和奖励函数;
10、步骤7,对步骤6所得的深度强化学习训练模型进行训练,得到无人机搭载智能反射面辅助节能应急通信决策模型,得到优化问题的最优解。
11、所述步骤1的过程如下:
12、无人机搭载智能反射面辅助节能应急通信场景,包括无人机,无人机安装一个有源可重构智能表面(ris),即无人机携带智能反射面系统(uav-ris),以及用于处理从地面设备传输的信息的空中基站(abs),空中基站(abs)作为控制中心,负责与无人机携带智能反射面系统(uav-ris)交互并发出命令,无人机携带智能反射面系统(uav-ris)辅助多个地面设备与空中基站(abs)的上行传输,将地面设备集合记为g={gm,m=1,2,…,m},其中,m为地面设备的个数,假设地面设备和空中基站(abs)之间不存在直连通信链路,并且空中基站(abs)位于较高的位置。
13、所述步骤2的过程如下:
14、步骤2.1,构建信道模型;
15、在信道模型中,每个地面设备都有一个全向天线,而空中基站(abs)配备了q个天线阵列,有源可重构智能表面(ris)由n个反射元件组成,假设ris的第n个元素的反射系数为其中,φn∈[0,2π),β表示大于1的放大因子,定义有源可重构智能表面(ris)反射系数矩阵为θ=diag([θ1,θ2,…,θn]);
16、hm,r表示第m个地面设备与无人机携带智能反射面系统(uav-ris)之间的链路的信道,hr,b表示无人机携带智能反射面系统(uav-ris)与空中基站(abs)之间的信道,假设无人机携带智能反射面系统(uav-ris)到空中基站(abs)的信道增益服从莱斯分布,则信道表示为:
17、
18、其中,κr,b为莱斯系数,l为参考距离d=1m处的路径损耗,dr,b为无人机携带智能反射面系统(uav-ris)与空中基站(abs)之间的距离,αr,b为uav-ris-abs链路的路径损耗指数;视距分量为第一级,表示为:
19、
20、其中,为无人机携带智能反射面系统(uav-ris)到空中基站(abs)链路的出发角(aod)和到达角(aoa),ω为天线间距;
21、非视距分量的每个元素都服从独立同分布的复高斯分布,均值为零,方差为1;同样,信道hm,r也遵循类似于上述的分布,第m个链路的los分量表示为:
22、
23、其中,为第m个地面设备到uav-ris的链路出发角(aod),到达角(aoa)和出发角(aod)由其相对位置关系确定;
24、最后假设所有信道都遵循块衰落,全局信道信息在空中基站(abs)是已知的,并且在每个时隙保持不变,但从一个时隙到另一个时隙会发生变化;
25、步骤2.2,基于步骤2.1构建的信道模型,构建传输模型;
26、地面设备向空中基站(abs)的上行传输模型中考虑无带内干扰,空中基站(abs)对每个链路采用最大比例合并(mrc),最大比例合并(mrc)波束形成矩阵用f=[f1,...,fm]表示,其中,fm表示第m链路的单位范数波束形成向量;空中基站(abs)接收到来自第m个地面设备的信号表示为:
27、
28、其中,pm为第m个地面设备的发射功率,sm为与监测数据相关联的单位能量信号样本;在空中基站(abs)处产生的噪声向量nm,表示为nm=[n1,...,nm]t,其中
29、有源可重构智能表面(ris)需要额外的功率,并且每个元件都配备了放大器,同时考虑在无人机携带智能反射面系统(uav-ris)处产生的热噪声ni,其中,空中基站(abs)第m链路的上行信噪比(sinr)表示为:
30、
31、因此,第m条链路的速率为cm=blog(1+ηm),其中,b为带宽。
32、所述步骤3的过程如下:
33、无人机携带智能反射面系统(uav-ris)和空中基站(abs)在时隙t的水平位置用和表示,其中,将无人机携带智能反射面系统(uav-ris)和空中基站(abs)的垂直高度分别设置为hr和hb的固定高度,无人机携带智能反射面系统(uav-ris)在下一个时隙t的水平位置由飞行距离dt和方位角变量ξt确定,则在t+1时刻无人机携带智能反射面系统(uav-ris)的水平坐标表示为:
34、依据对无人机携带智能反射面系统(uav-ris)的水平位置给出的设定,无人机携带智能反射面系统(uav-ris)在t时刻的水平飞行速度为最大水平速度,δt是每个时间段的长度;如果表示在t时刻,无人机处于盘旋状态;根据无人机的水平速度,得出在每个时间段无人机推进能源消耗为:
35、
36、其中,p0和p1分别为悬停状态的叶型恒功率和诱导功率,utip是转子叶片的叶尖速度,δt为每个时隙的持续时间,v0为悬停时的平均旋翼诱导速度,d0和s分别为机身阻力比和转子固度,ρ和g分别表示空气密度和转子盘面积。
37、所述步骤4的过程如下:
38、智能反射面在第t个时隙处的反射系数矩阵记为θt,ct,m为步骤2中所得的在第t个时隙处的第m条链路的通信速率,为步骤3中所得的第t个时隙内的无人机推进能源消耗,在长度为t的时间范围内最大化能源效率的目标函数表述为:
39、
40、
41、
42、
43、其中,约束(1)表示每个地面设备需要满足的传输速率要求,υ表示速率限制值;约束(2)限制了可重构智能表面(ris)相位可以调整的范围;约束(3)表示无人机携带智能反射面系统(uav-ris)最大飞行速度的限制。
44、所述步骤5的过程如下:
45、构建深度强化学习算法模型是采用h-ppo算法对无人机携带智能反射面系统(uav-ris)的飞行轨迹和可重构智能表面(ris)相位进行控制,h-ppo算法包括两个相互独立的近端策略优化算法ppo;第一个近端策略优化算法ppo用于优化飞行动作以进行轨迹控制;第二个近端策略优化算法ppo用于可重构智能表面(ris)相位值以增强信道增益;采用相互独立的近端策略优化算法ppo对飞行轨迹和可重构智能表面(ris)相位的控制进行优化;
46、近端策略优化算法ppo是一种深度强化学习(drl)的优化算法,近端策略优化算法ppo通过迭代更新策略来学习最优策略,使期望累积奖励最大化;近端策略优化算法ppo的策略被参数化并由两个网络表示,即演员网络和评论家网络其中,θa和θc表示相应的参数实例;近端策略优化算法ppo使用代理目标函数和剪切机制来约束策略更新;近端策略优化算法ppo中的目标函数为:
47、
48、其中,表示策略与旧策略之间的重要抽样权值;为对应的优势函数,其中γ为折现因子;裁剪机制将策略更新限制在预定义的范围内,其中clip()表示剪辑函数,而λ是一个超参数,用于将ρt(θa))控制在区间[1-ε,1+ε];
49、在训练阶段,使用i批与环境交互的经验来更新网络;对于行动者网络的参数更新方式为:
50、
51、同时为了更新θc,使用均方误差函数作为损失函数,表示为:
52、
53、其中,αc表示学习率,表示以时间差分方式导出的目标状态值函数。
54、所述步骤6对于状态空间、动作空间和奖励函数的设置如下:
55、1)状态空间:在时隙t处,第一个近端策略优化算法ppo的状态包含全局位置信息,表示为表示第m个地面设备在时隙t时的水平坐标;此外,第二个近端策略优化算法ppo的状态包含全局通道信息,表示为将此复数信道状态输入到网络前,将信道的实部与虚部分开,同时输入至神经网络中;
56、2)动作空间:在时隙t时,第一个近端策略优化算法ppo(上层)的动作是无人机携带智能反射面系统(uav-ris)的飞行距离和飞行方位,表示为第二个近端策略优化算法ppo(下层)在时隙t的动作为有源ris的相位值,记为θt;
57、3)奖励函数:第一个近端策略优化算法ppo的奖励结构由两个部分组成;首先为实时奖励,其包括当前时隙的通信量与能量消耗的比值以及无人机携带智能反射面系统(uav-ris)与所有地面设备之间水平距离与上一时隙的差值,表示为其中,pt,m表示第m个地面设备在时隙t满足速率阈值时的额外正奖励值,其次,设置反映整个服务周期能源效率的终止奖励,表示为λ表示一个正的固定值,用于调整终止奖励值与最终奖励的比例;此外,第一个近端策略优化算法ppo的奖励函数表示为:
58、
59、最后,在时隙t,第二个近端策略优化算法ppo的奖励函数表示为:
60、
61、所述步骤7的过程如下:
62、步骤7.1,初始化网络
63、随机初始化每个近端策略优化算法ppo的行动者网络θa以及批评家网络θc的参数;
64、步骤7.2,训练深度强化学习训练模型
65、随机初始化每个地面设备,无人机携带智能反射面系统(uav-ris)的位置,空中基站(abs)的位置;
66、在每个时隙t,第一个近端策略优化算法ppo与动态环境进行交互,得到状态基于当前的状态,第一个近端策略优化算法ppo从其actor网络中得到无人机飞行动作以控制无人机的轨迹;
67、第二个近端策略优化算法ppo与动态环境进行交互,得到状态基于当前的状态,第二个近端策略优化算法ppo从其actor网络中得到ris相位的动作以控制智能反射面;最后采取动作与环境交互,计算从环境中获得的奖励rt;
68、将状态状态动作动作和奖励rt存储在经验池中;
69、当经验池中的经验积累到一定量时,从中采取nd大小的样本来更新critic和actor网络的参数,一次训练结束后清空经验池,不断重复上述的过程,直至模型训练收敛,得到无人机搭载智能反射面辅助节能应急通信决策模型;
70、步骤7.3,决策阶段
71、将无人机搭载智能反射面辅助节能应急通信决策模型使用在随机的动态无人机搭载智能反射面辅助节能应急通信中,在每个时隙都决策出最优的可重构智能表面(ris)反射系数矩阵和无人机飞行动作,使得整个过程中的通信系统的能耗比最小,同时确保所有个体地面用户的通信质量。
72、本发明还提供了一种智能反射面辅助的无人机应急通信系统,包括:
73、无人机应急通信场景构建模块,用于构建无人机搭载智能反射面辅助节能应急通信场景;
74、通信过程建立模块,用于对无人机搭载智能反射面辅助节能应急通信场景中的无人机携带智能反射面系统(uav-ris)辅助多个地面设备的通信过程进行建模;
75、无人机推进能耗建立模块,用于对无人机推进能耗进行建模;
76、优化目标以及目标函数构建模块,用于结合无人机搭载智能反射面辅助节能应急通信场景中的无人机携带智能反射面系统(uav-ris)辅助多个地面设备的通信过程以及无人机推进能耗模型,对最终能耗比的优化目标进行建模,构建模型求解时的目标函数;
77、深度强化学习算法模型构建模块,用于根据提出的优化目标构建深度强化学习算法模型;
78、状态空间、动作空间和奖励函数设置模块,用于根据深度强化学习算法模型构建深度强化学习训练模型,结合无人机搭载智能反射面辅助节能应急通信场景和目标函数,设置深度强化学习训练模型的状态空间、动作空间和奖励函数;
79、深度强化学习算法模型训练模块,用于对深度强化学习训练模型进行训练,得到无人机搭载智能反射面辅助节能应急通信决策模型,得到优化问题的最优解。
80、本发明还提供了一种智能反射面辅助的无人机应急通信设备,包括:
81、存储器:存储上述一种智能反射面辅助的无人机应急通信方法的计算机程序,为计算机可读取的设备;
82、处理器:用于执行所述计算机程序时实现所述的一种智能反射面辅助的无人机应急通信方法。
83、本发明还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时能够实现所述的一种智能反射面辅助的无人机应急通信方法。
84、与现有技术相比,本发明的有益效果在于:
85、1.现有的传统优化,在面对高复杂度和高动态性的场景下,无法用数学方法推理出低复杂度的最优解方案。此外大多数研究采用离散drl算法来优化无人机的轨迹和可重构智能表面(ris)的相位偏移。但是用于处理轨迹和相位的离散动作算法限制了设计空间,会对其性能产生负面影响。本发明采用解决连续优化问题的深度强化学习算法,同时优化无人机的飞行轨迹以及智能反射面的相位,能够适应动态场景下的实时决策需求,以及解决联合无人机(uav)的轨迹和可重构智能表面(ris)的相移的复杂优化问题。
86、2.目前还没有研究无人机搭载智能反射面同时解决在需要长时间决策序列的场景中优化能效和确保单个用户服务质量的问题,本发明所提出的h-ppo算法有效解决联合轨迹与相位设计,并通过对h-ppo算法的奖励函数有效设计,能够在实现最大化系统的能耗比的同时,保证每个地面用户的个体服务质量。
87、3、本发明通过无人机携带智能反射面进行辅助应急通信,利用无人机的高机动性,使得作为移动中继的智能反射面的部署范围更广。能够为恶劣的应急场景下提供灵活度更高,更为持久的通信服务。
88、综上,本发明通过无人机携带智能反射面进行辅助应急通信,并提出h-ppo算法来同时优化无人机的飞行轨迹以及智能反射面的相位,在奖励函数中考虑个体地面用户的服务质量,解决了联合无人机(uav)的轨迹和可重构智能表面(ris)的相移的复杂优化问题,实现了最大化系统的能耗比的同时,保证每个地面用户的个体服务质量的要求,具有能够为恶劣的应急场景下提供灵活度更高,更为持久的通信服务优点。
本文地址:https://www.jishuxx.com/zhuanli/20241204/340637.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表