基于模型预测和深度强化学习的轮腿机器人控制算法
- 国知局
- 2024-07-31 23:41:40
本发明涉及机器人控制领域,尤其涉及基于模型预测和深度强化学习的轮腿机器人控制算法。
背景技术:
1、随着机械产业的不断发展,各种替代人类生产生活的机器人被设计并制造出来,而为了满足勘察、运输等需求,轮腿机器人应运而生,其具有速度快、效率高等优点,但轮腿机器人在实际应用时,由于其腿部结构的限制,在经过路况较差的位置时,容易产生侧翻等问题,缺乏在非结构化崎岖路段的适应能力和作业能力,为了解决这一问题,亟需设计一种针对轮腿机器人的控制算法。
技术实现思路
1、本发明针对现有技术存在的不足,提供如下技术方案:
2、基于模型预测和深度强化学习的轮腿机器人控制算法,包括:
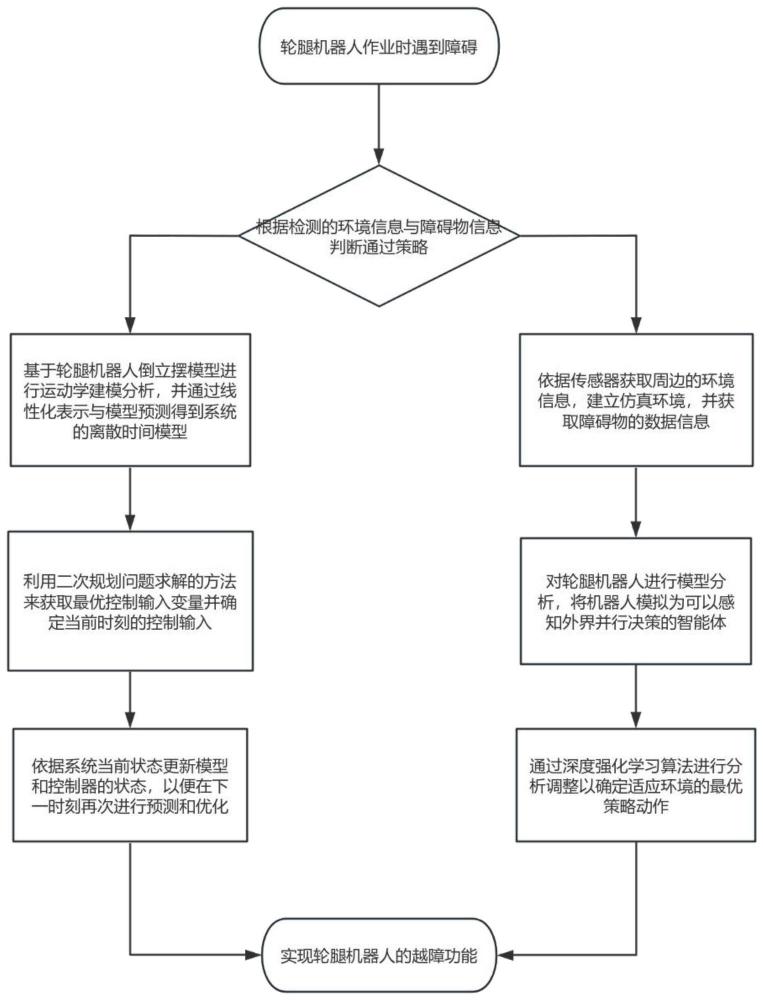
3、s1:根据检测的环境信息与障碍物信息判断通过策略,若通过策略判断为绕行时,执行步骤s2,若通过策略为变化姿态来越过障碍时,则执行步骤s3。
4、s2:基于轮腿机器人倒立摆模型进行动力学建模分析,并通过线性化表示与模型预测得到系统的离散时间模型,利用二次规划问题求解的方法来获取最优控制输入变量并确定当前时刻的控制输入。
5、s3:对轮腿机器人进行模型分析,将机器人模拟为可以感知外界并行决策的智能体,通过深度强化学习算法进行分析调整以确定适应环境的最优策略动作。
6、作为上述技术方案的改进,所述步骤s1包括以下步骤:
7、s11:依据轮腿机器人自带的传感器获取周边的环境信息,并通过建立仿真环境,获取障碍物的数据信息。
8、s12:将障碍物的数据信息与轮腿机器人的机身高度、轮腿长度进行对比以确定采用绕行或变化姿态来越过障碍。
9、作为上述技术方案的改进,所述步骤s2包括以下步骤:
10、s21:将预测时间段分解为k个时间节点,并建立系统的状态模型。
11、s22:基于倒立摆模型,对轮腿机器人进行动力学分析并将系统建模为一个离散时间的状态空间模型。
12、s23:对系统的状态模型进行线性化表示,并建立轮腿机器人的动力学模型。
13、s24:根据动力学模型进行模型预测求解,将动力学模型离散化,得到系统的离散时间模型,并建立离散的时间节点上模型输入、输出与控制变量之间的关系。
14、s25:利用二次规划问题求解的方法,获取最优控制输入变量,并根据最优控制输入变量确定最优控制策略以确定当前时刻的控制输入。
15、作为上述技术方案的改进,所述二次规划问题求解方法包括如下步骤:
16、s251:引入预测过程后,并考虑轮腿机器人的控制问题的情况下加入惩罚函数.
17、s252:并根据惩罚函数获取
18、所述步骤s251得到的模型为:
19、j=x(k)tgx(k)+u(k)thu(k)+2x(k)teu(k)
20、其中,x(k)为状态变量矩阵,u(k)为控制变量矩阵,k表示第k个时间节点,g为x(k)的二次项系数矩阵,h为u(k)的二次项系数矩阵,e为x(k)和u(k)的交叉项系数矩阵。
21、具体的:
22、
23、
24、
25、
26、其中,q、r是对角矩阵,f为施加到小车上的外力。
27、作为上述技术方案的改进,所述步骤s23包括以下步骤:
28、s231:基于平衡点对状态空间模型进行线性化,并得到连续时间的状态方程。
29、s232:利用泰勒展开对所述模型进行线性化并省略二阶小量,获取轮腿机器人的动力学模型。
30、所述步骤s232得到的动力学模型为:
31、
32、
33、其中,m为倒立摆质量,m为小车质量,i为摆的长度,x为小车位置,θ为倒立摆偏角,l为倒立摆的转动惯量,f为施加到小车上的外力。
34、所述步骤s25结束后还需要执行以下步骤:
35、s26:依据系统当前状态更新模型和控制器的状态,以便在下一时刻再次进行预测和优化。
36、作为上述技术方案的改进,所述步骤s3包括以下步骤:
37、s31:将轮腿机器人运动控制器抽象为可感知和进行决策的智能体,同时根据马尔可夫决策过程将此智能体描述为四元数组。
38、s32:建立策略网络、决策网络以及双网络结构的actor网络与critic网络,通过输入机器人状态观测值和机器人关节力矩的输出来计算q网络的输出值。
39、s33:根据随机迷你批采样数据来获取输出值的最小贝尔曼误差,并根据最小贝尔曼误差计算策略网络的损失函数。
40、s34:根据单步梯度衰减下降最小贝尔曼误差损失函数以更新q网络的参数。
41、s35:通过在线网络的延迟更新目标网络函数以得出最优策略动作。
42、作为上述技术方案的改进,所述步骤s34更新后的q网络的参数包括下式:
43、
44、其中,r表示奖励值,m表示随机迷你批,γ表示奖励折扣参数,q'和μ‘表示q网络和策略网络的目标网络。
45、作为上述技术方案的改进,所述机器人在遇到障碍时还执行以下步骤:
46、s41:将状态空间以机器人与障碍物的相对距离表示。
47、s42:对相对距离表示进行归一化处理,得到机器人的实际移动动作姿态在空间上的表示。
48、作为上述技术方案的改进,所述状态空间以机器人与障碍物的相对距离表示如下:
49、
50、其中,表示所处环境中障碍物的个数,和分别表示机器人与障碍物在x和y方向上的相对距离,所述相对距离表示为下式:
51、
52、
53、其中,[x0,y0]为机器人的位置坐标,[xi,yi]为障碍物的位置坐标,w为环境的宽度,h为环境的高度。
54、所述机器人的实际移动动作姿态在空间上的表示如下式所示:
55、dx=step*a[0],dy=step*a[1]
56、其中,a为策略网络输出的最优执行的策略动作姿态,step为预设的长度,用于控制距离障碍物的远近,从而及时做出对应的姿态调整。
57、本发明的有益效果:
58、通过为轮腿机器人提供双模式的选择,能够保证机器人在遇上障碍物之类的意外情况时,能够自我调整通过模式,选择最高效的通过方法,不仅能够加快整体的工作效率,而且能够在某些不寻常的非结构化崎岖路段有着较好适应能力和作业能力,解决了轮腿机器人的避障问题。
技术特征:1.基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于,包括:
2.根据权利要求1所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述步骤s1包括以下步骤:
3.根据权利要求1所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述步骤s2包括以下步骤:
4.根据权利要求3所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述二次规划问题求解方法包括如下步骤:
5.根据权利要求3所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述步骤s23包括以下步骤:
6.根据权利要求1所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述步骤s3包括以下步骤:
7.根据权利要求6所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述步骤s34更新后的q网络的参数包括下式:
8.根据权利要求1-7任意一项所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述机器人在遇到障碍时还执行以下步骤:
9.根据权利要求8所述的基于模型预测和深度强化学习的轮腿机器人控制算法,其特征在于:所述状态空间以机器人与障碍物的相对距离表示如下:
技术总结本发明涉及机器人控制领域,尤其涉及基于模型预测和深度强化学习的轮腿机器人控制算法,包括:S1:判断通过策略判断为绕行时,执行步骤S2,判断通过策略为变化姿态来越过障碍时,则执行步骤S3;S2:基于轮腿机器人倒立摆模型进行动力学建模分析,并通过线性化表示与模型预测得到系统的离散时间模型,利用二次规划问题求解的方法来获取最优控制输入变量并确定当前时刻的控制输入;S3:对轮腿机器人进行模型分析,通过深度强化学习算法进行分析调整以确定适应环境的最优策略动作。本发明通过为轮腿机器人提供双模式的选择,能够保证机器人在遇上障碍物之类的意外情况时,能够自我调整通过模式,选择最高效的通过方法。技术研发人员:刘晓黎,崔宇鑫,马好,马方彤,崔博渊受保护的技术使用者:安徽大学技术研发日:技术公布日:2024/6/18本文地址:https://www.jishuxx.com/zhuanli/20240730/198116.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表