一种网络化无中心式多节点协同决策控制方法
- 国知局
- 2024-07-31 23:41:46
本发明涉及高速飞行器协同决策控制,具体涉及一种网络化无中心式多节点协同决策控制方法,特别适用于多飞行器协同执行任务的场景。
背景技术:
1、速度在5马赫以上的飞行器均可称为高速飞行器,其包括高超音速巡航导弹、高超音速飞机、航天飞机。在高速飞行器决策控制领域,传统的协同决策控制方法通常采用集中式的架构。整个系统的决策和控制过程由一个中心节点负责,其优势在于简化系统设计和管理。然而,面向高速飞行器,上述设计方法面临一系列挑战。
2、(1)集中式设计容易受到单点故障的威胁。由于整个系统的决策核心位于一个节点,一旦该节点发生故障,高速飞行器的系统性能将受到重大损害,甚至可能导致系统崩溃。
3、(2)节点间的通信成为系统性能的瓶颈。在信息量巨大或需要实时响应的情况下,集中式方法存在的节点通信延迟可能会显著影响整个系统的性能。对于高速飞行器这类对实时决策要求极高的对象,上述风险显然是无法接受的。
4、(3)传统的飞行器决策系统在应对复杂、动态环境时适应性不足。传统方法通常缺乏有效机制来动态调整决策策略,从而难以适应环境的快速变化,导致高速飞行器的性能大打折扣。
5、因此设计面向高速飞行器的网络化无中心式多节点协同决策控制方法,以改变现有技术在协同决策控制中产生的单点故障威胁、决策实时度差且无法动态调整的缺陷,是目前已有技术尚未解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种网络化无中心式多节点协同决策控制方法,能够通过多智能体强化学习决策算法,实现了去中心化决策,同时避免了单点故障的风险。此外,算法充分考虑了动态环境的影响,通过针对性的自适应调整机制对决策进行动态调整,提高了系统的适应性。这一创新能够使得高速飞行器的决策系统更具效率、灵活性和可靠性。
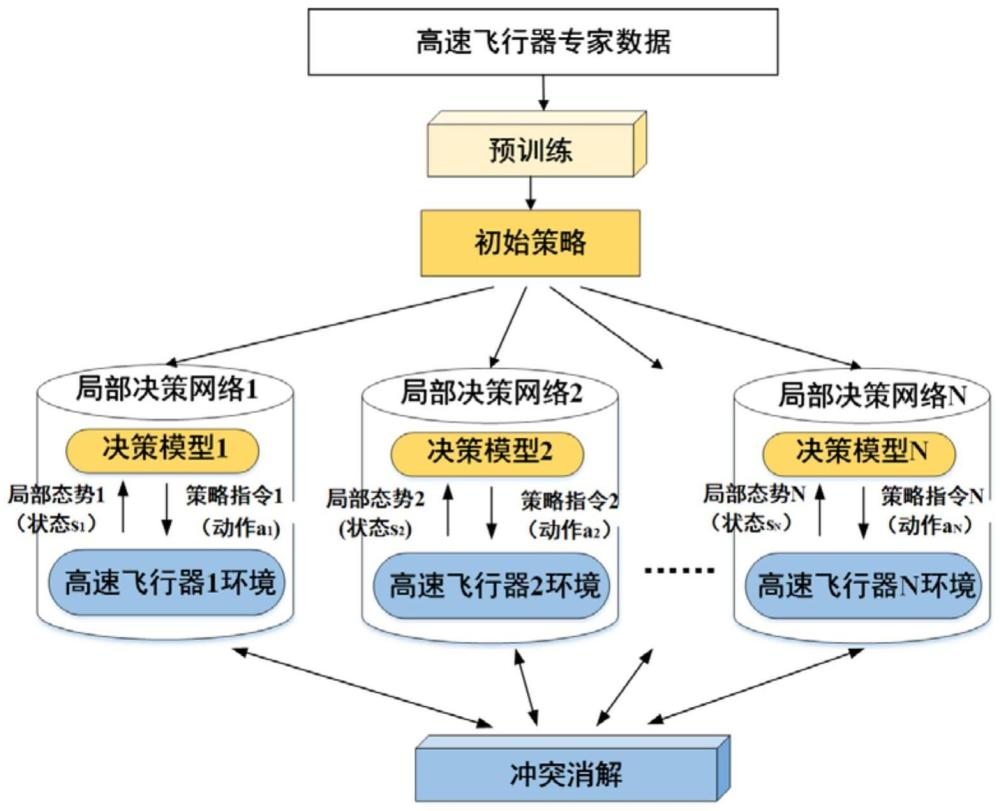
2、为达到上述目的,本发明的技术方案——一种网络化无中心式多节点协同决策控制方法,数量为n的高速飞行器,共同执行一任务,每个高速飞行器都是一个单独节点,根据感知获得的自身态势和通信获得的友方态势,包括如下步骤:
3、步骤一:以状态-动作对为中心设计预训练网络,根据专家数据以状态-动作对为中心进行预训练。
4、步骤二:构建高速飞行器决策控制模型,包含初始策略网络以及局部决策网络;初始化其中的所有网络,其中初始策略网络初始化为预训练网络,针对每个高速飞行器构建各自的局部决策网络,局部决策网络包含决策模型以及对应高速飞行器所处环境;预训练网络的输出即为初始策略。
5、执行如下步骤三~步骤五对高速飞行器决策控制模型进行训练。
6、步骤三:让决策模型与各自环境进行交互;其中,决策模型输出的动作为初始策略与目标策略的组合,以决策模型的输出构建样本存储到经验池;存储一定数量样本之后执行步骤四。
7、步骤四:从经验池采样并随机获取一个样本,然后更新目标策略πtar。
8、步骤五:在更新后的目标策略指挥下各决策模型与环境再次交互,采集获取当前环境下的状态st,交互后的样本放入样本池。
9、返回步骤四,迭代执行步骤四和步骤五,直至获得最优的高速飞行器决策控制模型。
10、在重复执行步骤四和步骤五的过程中,以一定的频率汇总所有局部决策网络的输出进行冲突消解并反馈给各局部决策网络,各局部决策网络根据反馈结果更新奖励函数,然后继续训练过程。
11、步骤六:得到最优的高速飞行器决策控制模型,将其装载至高速飞行器的决策系统中进行使用。
12、进一步地,以状态-动作对为中心设计预训练网络,具体为:
13、预训练网络在引入的采样分布和奖励函数之间进行迭代,其中鉴别器为奖励函数,生成器为采样分布,原始的鉴别器dθ如公式(3)所示。
14、
15、其中t为时刻,at为t时刻飞行器i对应的动作,st为t时刻飞行器i的状态,π(at|st)是待更新的采样分布的策略,rθ(st,at)是学到的奖励函数。
16、通过softmax函数或sigmoid函数保证概率值的归一化,最终获得在最优情况下的rθ(st,at),即r*(st,at):
17、r*(st,at)=logπ*(at|st)=a*(st,at) (4)
18、其中π*(at|st)代表最优的采样分布的策略,a*(st,at)为最优策略的优势函数。
19、对塑造术语函数hφ进行多参数化,其参数为φ,由此,鉴别器dθ,φ如公式(5)所示:
20、
21、其中,rθ,φ仅与奖励近似器gθ和塑造术语hφ有关,如公式(6)所示:
22、rθ,φ(st,at,st+1)=gθ(st,at)+γhφ(st+1)-hφ(st) (6)
23、其中γ为折扣因子。
24、预训练模块的输出π*(at|st)为最优的采样分布的策略。
25、进一步地,让决策模型与各自环境进行交互;其中,决策模型输出的动作为初始策略与目标策略的组合,具体为:
26、决策模型输出的高速飞行器的动作a由初始策略πini和目标策略πtar共同得出,如公式(7)所示。
27、a=ρaini(s)+atar(s) (7)
28、其中aini(s)为初始策略πini在初始状态为s时输出的初始动作,atar(s)为初始策略πini在当前状态s下输出动作指令,ρ等于迭代次数的倒数。
29、进一步地,以决策模型的输出构建样本存储到经验池,具体地所构建的样本形式为(st,atar,st+1,rt),st、st+1分别为t时刻和t+1时刻的状态,atar为初始策略输出的动作,rt为奖励函数。
30、进一步地,获得最优的高速飞行器决策控制模型,判断方式为:奖励函数曲线收敛时,即获得最优的高速飞行器决策控制模型。
31、有益效果:
32、针对传统飞行器决策控制方法所存在的单点故障、通信延迟、动态调整性能不足等问题,本发明提出了一种名为“组合策略学习”的网络化、无中心化的多节点协同决策控制方法。该方法在强化学习训练之前加入针对高速飞行器的预训练,并且对强化学习训练过程中策略网络更新的方式进行改进。本发明的主要工作及有益效果如下。
33、第一,本发明提出了一种预训练结合强化学习的决策模型生成方法,提高了模型的收敛效率,降低了训练成本。该方法在强化学习训练之前加入针对高速飞行器的预训练,并且对强化学习训练过程中策略网络更新的方式进行改进,从两方面同时减少样本需求量、提高训练效率,从而提升协同决策模型的收敛速度和收敛结果。
34、第二,本发明提出了一种网络化、无中心化的多节点协同决策控制方法,提高了系统的鲁棒性。由于决策过程不再集中在单一的中心节点上,系统对于单点故障的容忍能力得到了显著提升。每个节点都可以独立地做出决策,因此即使某个节点发生故障,其他节点仍然可以保持正常运行,从而增加了整个系统的稳定性和可靠性。
35、第三,本发明通过多智能体决策网络的方式引入了自适应调整机制,使得系统更好地适应动态环境的变化。高速飞行器经常面临着快速变化的外部条件,例如气象、空中交通状况等,传统方法往往难以灵活应对。而无中心式多节点的方法能够根据实时的环境信息进行自适应调整,使得系统能够更好地适应不断变化的外部条件,提高了系统的适应性和灵活性。
36、第四,本发明中分布式决策过程降低了单一节点的通信负担,有助于提高系统的实时性。在高速飞行器的控制系统中,实时响应是至关重要的,而传统的集中式方法可能因通信瓶颈而导致延迟。通过分布式决策,系统的通信负担得以分散,从而降低了延迟的风险,提高了系统在实时性方面的表现。
37、综上,本发明提出的一种针对高速飞行器的网络化无中心化多节点协同决策控制方法,提高了决策模型的收敛效率、鲁棒性、适应性和实时性,有助于高速飞行器在复杂、动态的环境中更加高效地完成任务。
本文地址:https://www.jishuxx.com/zhuanli/20240730/198126.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。