一种空中动作控制强化学习模型的训练方法和系统与流程
- 国知局
- 2024-07-31 23:50:23
本发明涉及飞行器控制,特别涉及空中动作控制强化学习模型的训练方法和系统。
背景技术:
1、演员-评论家actor-critic算法,例如proximal policy optimization(ppo)和asynchronous advantage actor-critic(a3c)严重依赖智能体与环境的交互来提高其性能表现。特别是在学习的早期阶段,强化学习算法需要大量的探索经验,在现实场景下成本非常昂贵且耗时。
2、在开始的训练过程中,强化学习模型无法内化专家知识和人类行为先验知识,这使得模型在早期阶段通常进行大量无用且昂贵的探索,最终导致模型会在很晚的阶段收敛到次优策略。因此,有许多研究集中在强化学习算法与专家示范数据的结合上。其中,预训练策略网络和评论家网络是利用专家示范的最常见方法。但在示范数据有限的情况下,训练过程中容易出现过拟合的问题,导致网络参数病态,性能不佳。
3、另一种方式是从演示数据学习(learning from demonstrations,lfd)来加速模型的学习过程,在lfd框架内,通常的做法是将示范数据集作为重放缓冲区(replaybuffer)的一部分,然后利用优先级重放缓冲区提高专家示范数据的比例来训练网络。然而,这种方式仅限于将它们与自生成数据做相同的处理,无法充分利用示范数据的能力,所以需要大量的示范数据来维持性能。
4、此外,利用示范数据来加速强化学习训练的方法可能无法有效地处理不明确的示范数据。专家经验示范也可能存在模糊性。由于初始状态不同,在训练时智能体如果简单地复制示范数据可能会导致失败。
技术实现思路
1、本发明的目的是提供空中动作控制强化学习模型的训练方法,本发明通过为过去经历的轨迹数据分配分数来识别良好的策略行为。为了有效地学习过去的良好策略,本发明引入排名缓冲区来存储高分的动作轨迹,然后强化学习算法利用这些数据更新策略网络,学习到最优策略。
2、解决了模型训练中,训练轨迹数据有效性低、收敛性差,从而训练时间长的问题。为解决上述问题,本发明的第一方面提供了空中动作控制强化学习模型的训练方法,空中动作控制强化学习模型的架构中包括策略网络。
3、空中动作控制强化学习模型的训练方法包括:
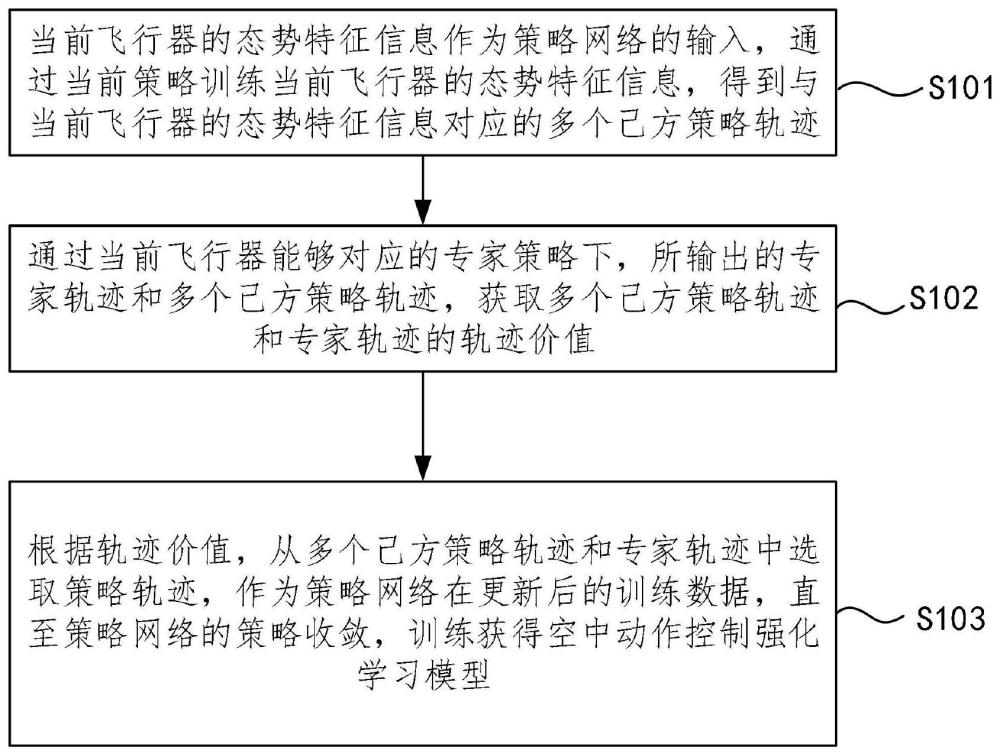
4、当前飞行器的态势特征信息作为策略网络的输入,通过当前策略训练当前飞行器的态势特征信息,得到与当前飞行器的态势特征信息对应的多个己方策略轨迹。
5、通过当前飞行器能够对应的专家策略下,所输出的专家轨迹和多个己方策略轨迹,获取多个己方策略轨迹和专家轨迹的轨迹价值。
6、根据轨迹价值,从多个己方策略轨迹和专家轨迹中选取策略轨迹,作为策略网络在更新后的训练数据,直至策略网络的策略收敛,训练获得空中动作控制强化学习模型。
7、本发明的上述技术方案具有如下有益的技术效果:
8、本发明提出的基于示范数据的新型强化学习方法适用于所有基于actor-critic的算法,能够加速强化学习的收敛并提高最终性能。与其他方法相比,本发明不只从单个状态-动作对的相似度判断示范数据的好坏,而是通过为过去经历的轨迹数据分配分数来识别良好的策略行为,能够充分地利用示范数据,在示范数据质量不高、示范经验模糊时能取得更好的训练效果。
9、此外本发明提供的基于行为树框架设计的专家策略能够快速产生不同风格的专家策略,提供多样的示范数据,有利于算法的稳定性。从而提高了飞行器在高空对抗时的控制信息准确性和精度。
技术特征:1.一种空中动作控制强化学习模型的训练方法,其特征在于,所述空中动作控制强化学习模型的架构中包括策略网络;
2.根据权利要求1所述的训练方法,其特征在于,还包括:
3.根据权利要求2所述的训练方法,其特征在于,当所述当前飞行器为多个己方飞行器时,所述当前飞行器的多个态势信息包括:
4.根据权利要求3所述的训练方法,其特征在于,当所述当前飞行器为多个己方飞行器时,所述当前飞行器的多个态势信息包括:
5.根据权利要求4所述的训练方法,其特征在于,还包括:将所述多个态势信息组合成一个和多个态势信息组合;
6.根据权利要求3或4所述的训练方法,其特征在于,还包括:将所述一个和多个态势信息组合、识别图像组合和一个和多个态势综合信息组合,作为飞行器特征识别模型的输入,所述飞行器特征识别模型识别所述一个和多个态势信息组合、识别图像组合和一个和多个态势综合信息组合中的特征,得到固定长度的特征向量或特征向量的组合;
7.根据权利要求2所述的训练方法,其特征在于,当前飞行器的态势特征信息作为策略网络的输入,通过当前策略训练所述当前飞行器的态势特征信息,得到与所述当前飞行器的态势特征信息对应的多个己方策略轨迹包括:
8.根据权利要求1所述的训练方法,其特征在于,获取多个己方策略轨迹和专家轨迹的轨迹价值包括:
9.根据权利要求8所述的训练方法,其特征在于,若所述态势为连续状态空间,则通过本回合中所有状态的标准差,得到所述策略效果值。
10.根据权利要求1所述的训练方法,其特征在于,根据所述轨迹价值,从所述多个己方策略轨迹和专家轨迹中选取策略轨迹,作为所述策略网络在更新后的训练数据包括:
11.根据权利要求10所述的训练方法,其特征在于,所述空中动作控制强化学习模型的架构中还包括价值网络;
12.一种空中动作控制强化学习模型的训练系统,其特征在于,所述空中动作控制强化学习模型的架构中包括策略网络;
13.根据权利要求12所述的训练系统,其特征在于,还包括:
14.根据权利要求13所述的训练系统,其特征在于,当所述当前飞行器为多个己方飞行器时,所述当前飞行器的多个态势信息包括:
15.根据权利要求14所述的训练系统,其特征在于,当所述当前飞行器为多个己方飞行器时,所述当前飞行器的多个态势信息包括:
16.根据权利要求15所述的训练系统,其特征在于,所述态势参数提取单元,还配置为:将所述多个态势信息组合成一个和多个态势信息组合;
17.根据权利要求14或15所述的训练系统,其特征在于,所述态势参数提取单元,还配置为包括:将所述一个和多个态势信息组合、识别图像和一个和多个态势综合信息组合,作为飞行器特征识别模型的输入,所述飞行器特征识别模型识别所述一个和多个态势信息组合、识别图像组合和一个和多个态势综合信息组合中的特征,得到固定长度的特征向量或特征向量的组合;
18.根据权利要求13所述的训练系统,其特征在于,所述策略网络还配置为获得当前飞行器的态势特征信息通过当前策略,得到本回合中的己方初始策略动作;
19.根据权利要求12所述的训练系统,其特征在于,轨迹提取单元还配置为:
20.根据权利要求19所述的训练系统,其特征在于,若所述态势为连续状态空间,则通过本回合中所有状态的标准差,得到所述策略效果值。
21.根据权利要求12所述的训练系统,其特征在于,轨迹提取单元,还配置为根据所述轨迹价值,从所述多个己方策略轨迹和专家轨迹中选取策略轨迹,作为所述策略网络在更新后的训练数据包括:
22.根据权利要求21所述的训练系统,其特征在于,所述空中动作控制强化学习模型的架构中还包括价值网络;
23.一种利用空中动作控制强化学习模型控制外部设备的方法,其中,所述空中动作控制强化学习模型是根据权利要求1至11的任意一项所述的方法所训练获得的,其特征在于,包括:
24.一种电子设备,其特征在于,包括:
25.一种计算机可读存储介质,其特征在于,包含有空中动作控制强化学习模型的程序指令和/或利用空中动作控制强化学习模型处理己方飞行器的状态数据的程序指令,当所述程序指令由处理器执行时,使得实现根据权利要求1-11的任意一项所述的方法和/或根据权利要求23所述的方法。
技术总结本发明公开了一种空中动作控制强化学习模型的训练方法,包括:当前飞行器的态势特征信息作为策略网络的输入,得到与当前飞行器的态势特征信息对应的多个己方策略轨迹。通过专家轨迹和多个己方策略轨迹,获取多个己方策略轨迹和专家轨迹的轨迹价值。根据轨迹价值选取策略轨迹,作为策略网络在更新后的训练数据,训练获得空中动作控制强化学习模型。解决了模型训练中,训练轨迹数据有效性低、收敛性差且训练时间长的问题。从而,本发明能够充分地利用示范数据,在示范数据质量不高、示范经验模糊时能取得更好的训练效果且有利于算法的稳定性。提高了飞行器在高空对抗时的控制信息准确性和精度。技术研发人员:兴军亮,詹员,史元春,陶品受保护的技术使用者:启元实验室技术研发日:技术公布日:2024/6/23本文地址:https://www.jishuxx.com/zhuanli/20240730/198769.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。