一种基于GRU最大熵强化学习的高速欠驱动AUV运动控制方法
- 国知局
- 2024-08-01 00:14:15
本发明属于水下航行器运动控制,尤其是涉及一种基于gru最大熵强化学习的高速欠驱动auv运动控制方法。
背景技术:
1、近年来,自主水下航行器(auv)在各个领域获得了越来越多的关注。它们高度的自主性使其成为海洋科学研究、水下地质探索和海洋生态系统保护等应用的理想选择。然而,在复杂的水下环境中实现auv的高自主性是一个重大挑战,尤其是当其执行高速的任务时。auv在运动中面临高度的参数非线性和时变的外界干扰,因此确保它们实现稳定的路径跟随仍是控制领域的一个重要研究课题。
2、在工业界,auv的运动控制最常用的方案仍然是比例积分微分(pid)控制,这归因于其原理简单且高效、易于理解和实施、以及具有清晰的物理意义。对于基于pid的auv运动控制,需要首先建立尽可能精确的物理模型,然后在此模型上预整定出合适的pid参数。然而在实验中,由于auv系统的复杂性和不可避免的建模误差,这些通过模拟预整定出的参数通常表现不佳。因此需要进一步的通过大量试验优化参数,以最终获得合适的pid控制器,但这套pid参数很可能不会进一步适用于其他多种工况(比如不同的速度、不同的路径跟随任务等)。auv的试验成本巨大,通常需要大量人力物力并且存在较高的危险性,因此需要一种不依赖于精确模型并且能够自适应优化的智能控制算法来解决上述问题。
3、强化学习方法的快速发展在各个领域引起了广泛关注,特别是在控制领域具有特殊意义。该方法在面对动态环境和多样的系统需求时,能够从现实世界的观察中学习和优化控制策略。以auv的运动控制为例,强化学习可以不依赖其动力学模型,通过auv与环境的交互获得反馈的奖励值,以最大化累积奖励为优化目标找到最优策略。其中最大熵强化学习通过引入熵正则化,来进行探索与开发的权衡,避免算法陷入局部最优解,更适用于水下auv的运动控制问题。尽管强化学习算法在计算机模拟auv控制任务时表现出色,但其策略的黑箱性质会使其在复杂多变的真实环境中容易受到意外状态的影响(jiang p,song s,huang g.attention-based meta-reinforcement learning for tracking control ofauv with time-varying dynamics[j].ieee transactions on neural networks andlearning systems,2021,33(11):6388-6401),这可能会导致灾难性的决策后果,如auv航行过深、跃出水面或造成碰撞。此外,想探究清楚这些异常现象的根本原因也相当具有挑战性。因此,目前在强化学习算法方面仍缺少的实地试验的验证。
4、综上所述,目前欠驱动auv的控制存在以下两点难点:
5、1.工程中常用的pid控制器,不能应对多种工况的控制任务,所需要调整参数的试验成本巨大;
6、2.强化学习等数据驱动算法因其黑箱性质,直接运用在实际工程中容易导致灾难性的未知后果。
7、pid控制器具有相对更成熟的应用背景,其原理简单且高效、易于理解和实施、以及具有清晰的物理意义刚好可以补偿强化学习算法的缺陷。(anderlini e,parker g g,thomas g.docking control of an autonomous underwater vehicle usingreinforcement learning[j].applied sciences,2019,9(17):3456)文中采用ppo结合pid的方法来实现auv的控制,但算法收敛效果仍有待提高,传统的神经网络对于时序信息的处理能力也较差,并且不适用于高速工况。
技术实现思路
1、本发明提供了一种基于gru最大熵强化学习的高速欠驱动auv运动控制方法,可以实现稳定的控制效果,在工程上易于实现并且能保证可靠安全。
2、一种基于gru最大熵强化学习的高速欠驱动auv运动控制方法,包括:
3、(1)建立高速欠驱动auv的六自由度运动数学模型;
4、(2)设计智能体观测的状态空间和奖励函数,以组成完整的马尔可夫过程;
5、其中,状态空间包括:当前auv位置与当前期望位置的偏差e1,当前auv角度与其位置瞄准下一时刻位置角度的偏差e2,当前auv的角度、速度、执行机构状态;
6、奖励函数包括:当前auv位置与当前期望位置的偏差e1相关奖惩项,当前auv角度与其位置瞄准下一时刻位置的角度的偏差e2相关奖惩项,auv执行机构的奖惩项,终止状态奖惩项;
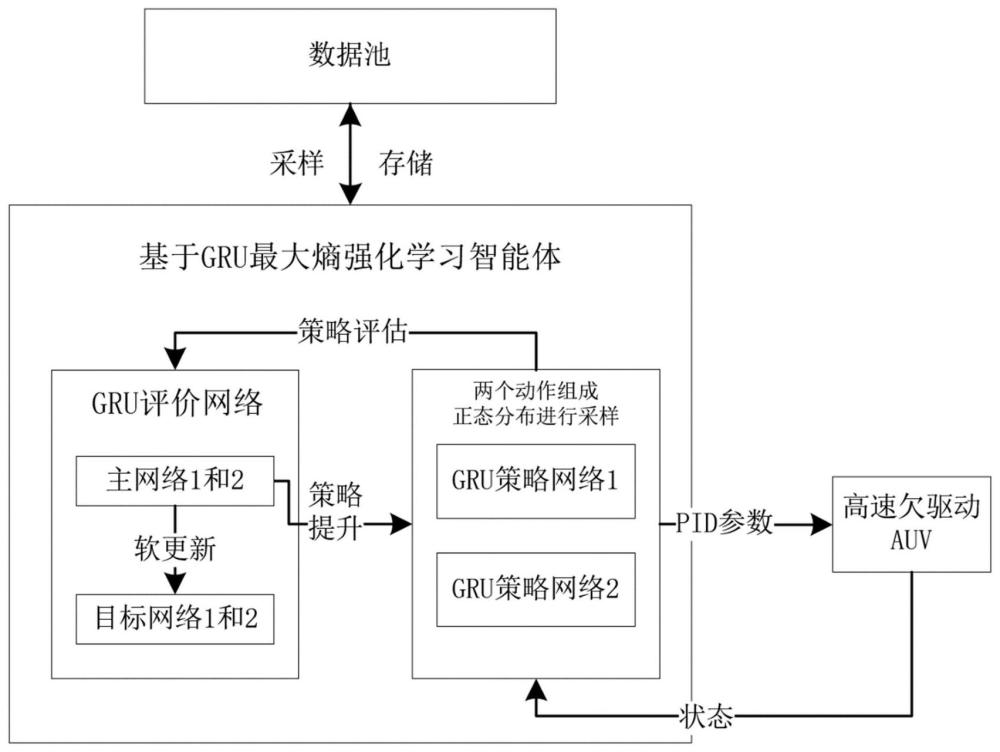
7、(3)基于gru建立策略网络和评价网络,对高速欠驱动auv的运动控制任务进行训练;
8、(4)训练后,智能体根据高速欠驱动auv的状态,实时输出控制动作。
9、步骤(1)中,高速欠驱动auv中,执行机构的力分为推进器的力和尾舵的舵力;建立六自由度运动数学模型时,推进器和尾舵的模型通过计算流体力学模拟方法建立,推进器模型需要计算推力系数和扭矩系数曲线,尾舵模型需要计算舵力关于进速的一次项和二次项系数。
10、步骤(2)中,设计奖励函数时,定义算子γ如下
11、
12、式中,emin是直到当前时刻误差的最小值;k是放缩系数,用于保证奖励值在-1和1之间;
13、
14、式中,r为奖励值,e1为航向角偏差,e2为俯仰角偏差,d是当前auv位置和下一时刻期望位置的距离,δδ是执行机构的变化量,k1是其奖惩放缩系数,
15、
16、式中,rfinal为任务完成时额外获得的奖励,中途控制效果较差而终止任务则无法获得该奖励,此项用于激励智能体以实现完成整个控制任务为优先,提高控制效果和收敛速度。
17、步骤(3)中,基于gru建立策略网络和评价网络,具体结构为:
18、由输入层开始,通过两层gru层,接着经过第一层全连接层用于特征提取,之后分别是评价网络和策略网络对应的第二层全连接层;gru层之间传递的信息是隐藏状态,即第一个gru层的隐藏状态传递到第二个gru层,第二个gru层的隐藏状态传递到第一层全连接层;
19、其中,评价网络对应的第二层全连接层,输出维度为1,不使用激活函数,用于评估状态动作的价值;策略网络对应的第二层全连接层,输出维度为9,采用softmax激活函数,输出动作概率分布,其中9是动作空间的大小。
20、步骤(3)中,对高速欠驱动auv的运动控制任务进行训练,具体包括:
21、先进行预训练,在数据池中预先积攒n组数据,其中,数据以(st,at,st+1,r,done)数据对的形式存储,st是当前状态,at是采取的动作,st+1是下一个状态,r是收到的奖励,done表示是否终止了该回合;
22、在预训练后,将auv与环境交互来进行训练,其中,策略网络将当前状态st作为输入,;同时,评价网络估计状态-动作值函数q(st,at);这些网络通过迭代更新参数来最大化预期累积奖励。
23、在每个训练迭代中,从数据池中采样一个批次的数据,策略网络通过采样和当前评价网络来最大化预期回报进行更新,评价网络通过最小化估计值和目标值之间的时序误差来进行更新,目标值通过bellman方程和当前策略计算。
24、本发明中,同时采用两个独立的基于gru的策略网络来输出动作,两个输出动作的均值作为正态分布的均值,对该分布采样的结果作为最终实际选取的动作。
25、优选地,训练过程中,奖励函数折扣因子为0.99~0.995,目标平滑因子设定为0.85~0.95,每次采样用于训练的数据量为256,训练策略相较训练评价网络的延迟为2~4,熵正则化因子设置为0.2。
26、进一步地,奖励函数的终止状态奖惩项中,设置了除去航行时间外的其他终止条件,第一部分是航行偏差e1过大,限制为水平面内的距离偏差不超过10m,深度偏差不超过3m;第二部分是横滚角和俯仰角过大,分别限制其绝对值的最大值为30°和40°。
27、与现有技术相比,本发明具有以下有益效果:
28、本发明将pid作为底层控制器的同时采用最大熵强化学习自动学习训练运动控制器,同时保证了可行性和智能性。同时,引入gru作为策略网络和评价网络,明显优于传统的神经网络,更适用于提取auv运动过程的时序信息,并为高速欠驱动水下无人航行器设计了合适的状态空间和奖励函数,最终实现了稳定的控制效果,在工程上易于实现并且能保证可靠安全。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200150.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表