一种基于跨模态感知注意机制的轻量级四足机器人运动方法
- 国知局
- 2024-09-14 15:00:00
本发明涉及机器人运动,具体涉及一种基于跨模态感知注意机制的轻量级四足机器人运动方法及系统。
背景技术:
1、近年来,腿足式机器人作为新式的边缘智能设备,能够使用各种传感器(如摄像头、声音传感器、触觉传感器等)来感知周围的环境,并使用内置的处理器和算法来分析这些数据。根据分析结果,四足机器人可以做出相应的动作或决策,比如避障、执行命令、展示互动行为等。与轮式或履带式机器人或其他可移动边缘智能设备相比,腿足式机器人运动的灵活性和环境的适应性都大大增加,能够穿越复杂的非结构化地形,完成更多样的边缘智能任务。同时,强化学习作为一种新的学习范式,与传统的控制方法如mpc等不同,无需大量的专业知识、稠密的实验数据和繁琐的手动调参即可使机器人学习到自主策略,从而降低了学习方法设计的复杂性。
2、强化学习方法通过在虚拟环境中对机器人进行的全面的端到端训练,获得有效驾驭复杂环境所必需的各种策略。此外,利用强化学习范式使智能主体能够从外部感知和本体感知中提取相关的外部信息,从而能够制定有弹性和适应性的策略。
3、四足机器人利用雷达和深度相机等传感器进行外部感知,如何有效处理和整合来自不同输入的信息仍具有挑战性。用于处理各种模态信息的不同模块必须以连续的方式无缝运行。并且现实世界中的四足机器人面临着计算资源和时间约束的显著约束。这些约束使它们无法在现实世界的动态和资源受限环境中一致且稳健地执行人们部署的任务。大多数现有工作主要基于模拟,没有具体解决这个问题。
4、相反,人类认知在处理多模式信息方面表现出显著的适应性,通过只关注相关信息来优化注意力和资源分配,同时最大限度地减少对无关数据的处理。这种自适应处理策略允许个体基于上下文线索和环境因素选择性地优先考虑或忽略特定的感觉输入。为了说明这种适应性,可以考虑行人在繁忙的街道上穿行,同时打电话的典型场景。人们通常能够熟练地协调自己的动作,避免与同行的行人和车辆相撞,同时流利地交谈。然而,在某些情况下,由于个人过度专注于对话,可能会导致碰撞。
5、基于此,本发明提供了一种基于跨模态感知注意机制的轻量级四足机器人运动方法, 通过端到端的强化学习结合人类跨模态感知注意机制使四足机器人学习运动策略。
技术实现思路
1、本发明主要解决的问题:四足机器人在动态环境中的无法根据任务和环境进行自适应的感知和运动,造成了更多的计算资源和能源的消耗,从而阻碍了其在能源限制环境中的真实部署和应用。本发明提供一种基于跨模态感知注意机制的轻量级四足机器人运动方法及系统,该方法首先基于pybullet物理引擎建立仿真环境,包括机器人建模、地形与障碍物构建;其次设计基础强化学习控制器,包括状态空间、动作空间和奖励函数;然后组合低级多模态信息融合强化学习和高级跨模态感知注意力控制器来控制机器人根据环境和任务选择开关视觉通道来减少算力消耗;最后使用ppo算法进行训练,并在仿真环境和真实环境测试四足机器人复杂环境的自主避障决策能力。
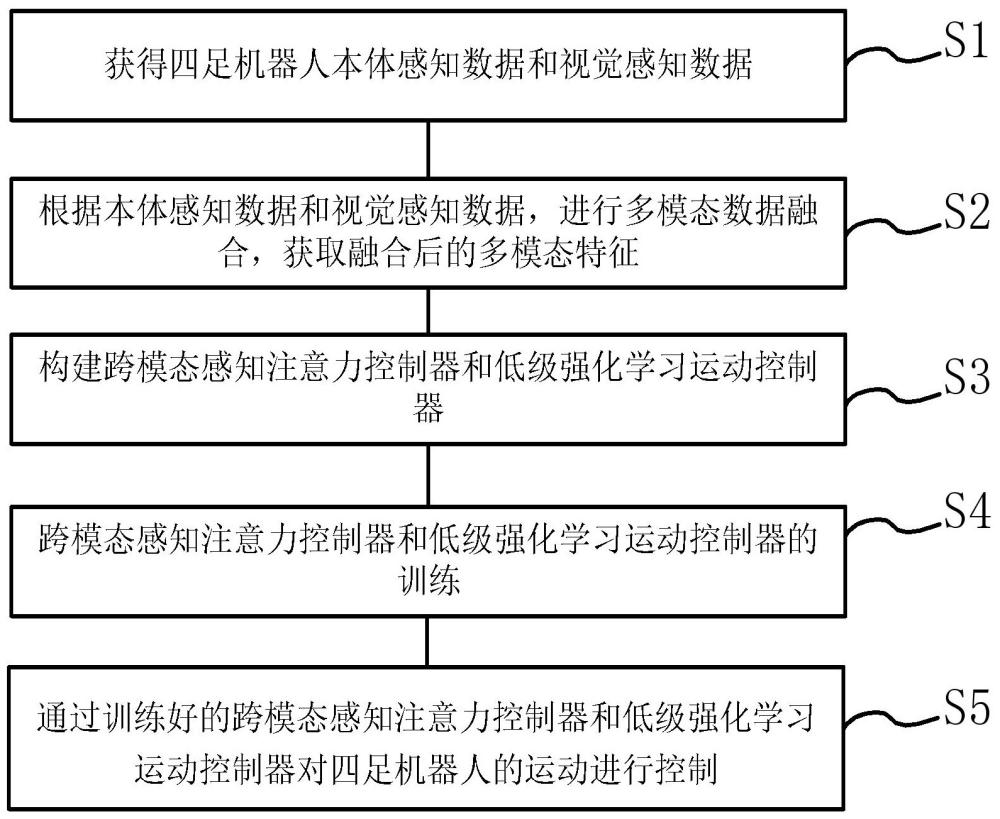
2、本发明第一个目的是提供一种基于跨模态感知注意机制的轻量级四足机器人运动方法,包括:
3、获得四足机器人本体感知数据和视觉感知数据;
4、根据本体感知数据和视觉感知数据,进行多模态数据融合,获取融合后的多模态特征;
5、构建跨模态感知注意力控制器和低级强化学习运动控制器;
6、根据多模态特征,对跨模态感知注意力控制器以及低级强化学习运动控制器在虚拟环境协同训练,训练时,四足机器人与虚拟环境的不断交互,采用强化学习的训练方式进行训练,获得训练好的跨模态感知注意力控制器和低级强化学习运动控制器;
7、其中,训练过程中,将多模态特征输入跨模态感知注意力控制器判断下一时刻是否采集视觉感知数据,同时,将多模态特征输入低级强化学习运动控制器输出多个关节的期望转动角度;
8、通过训练好的跨模态感知注意力控制器和低级强化学习运动控制器对四足机器人的运动进行控制。
9、优选的,所述跨模态感知注意力控制器采用两层mlp,输出为0或1的控制信号,来决定下一时刻是否需要开关视觉感知器;在下一时刻视觉感知数据获取时将视觉感知数据输入乘以控制信号,当输出为0时代表关闭视觉感知器,当输出为1时代表打开视觉感知器。
10、优选的,所述跨模态感知注意力控制器在收集来自多模态特征的后积累决策信号,当累积的信号达到预定阈值时,跨模态感知注意力控制器做出感知行为的决定,并调节机器人感知的输入。
11、优选的,所述跨模态感知注意力控制器的损失函数为:
12、
13、式中,表示感知损失,是将跨模态感知注意力控制器输出的控制信号和目标信号之间差的比率乘以奖励函数输出的当前奖励;
14、表示收敛损失,是见跨模态感知注意力控制器输出的控制信号值向较窄范围收敛的正则化项;
15、,,在训练中用了学习率为的adam优化器。
16、优选的,所述低级强化学习运动控制器包括两层mlp,通过定义的状态空间、动作空间及奖励函数,进行强化学习训练。
17、优选的,所述状态空间包括本体感知和视觉信息;
18、所述本体感知包括关节角度、imu信息和上一个动作,完整的本体感知记录了最后连续3个时刻的状态,以保留历史状态信息,用于推断环境状态;
19、所述视觉信息包括由安装在机器人头部的深度相机拍摄的形状为64×64的连续四张深度图组成,为机器人提供时空视觉信息。
20、优选的,所述动作空间是采用位置驱动方式,控制器输出为12个关节的期望转动角度,并使用0.5作为运动稳定性的动作上限。
21、优选的,所述奖励函数是在机器人的运动任务中,学习的目标是机器人能够自主稳定地向前运动,并不与障碍物发生碰撞,设计了如下奖励函数:
22、
23、式中,表示前进奖励,激励机器人沿着特定任务的方向前进;表示能耗奖励,鼓励机器人使用最少的能量,用于改善运动的自然性,使用欧几里得范数来对电机扭矩进行惩罚;表示存活奖励,鼓励机器人存活时间更久,在每个时间步给出1.0的正奖励,直到终止;表示终止惩罚,当训练轮次提前终止时进行惩罚,摔倒和撞到障碍物等危险行为会导致终止,鼓励机器人避免碰撞等不安全行为;;;;;。
24、优选的,所述低级强化学习运动控制器采用ppo算法训练强化学习智能体,是通过将多模态特征输入至低级强化学习运动控制器,低级强化学习运动控制器中根据获得的状态信息计算出奖励值和下一步动作值,然后将状态、动作、奖励值作为一个训练样本,通过最小化损失函数更新策略网络和价值网络参数。
25、本发明第二个目的是提供一种基于跨模态感知注意机制的轻量级四足机器人运动系统,包括:
26、数据融合模块,用于获得四足机器人本体感知数据和视觉感知数据;根据本体感知数据和视觉感知数据,进行多模态数据融合,获取融合后的多模态特征;
27、控制器训练模块,用于构建跨模态感知注意力控制器和低级强化学习运动控制器;根据多模态特征,对跨模态感知注意力控制器以及低级强化学习运动控制器在虚拟环境协同训练,训练时,四足机器人与虚拟环境的不断交互,采用强化学习的训练方式进行训练,获得训练好的跨模态感知注意力控制器和低级强化学习运动控制器;其中,训练过程中,将多模态特征输入跨模态感知注意力控制器判断下一时刻是否采集视觉感知数据,同时,将多模态特征输入低级强化学习运动控制器输出多个关节的期望转动角度;
28、机器人控制模块,用于通过训练好的跨模态感知注意力控制器和低级强化学习运动控制器对四足机器人的运动进行控制。
29、本发明至少具有如下有益效果:
30、本发明提供了一种基于跨模态感知注意机制的轻量级四足机器人运动方法及系统,本发明基于人类大脑在处理包括视觉、听觉和其他感觉模式的刺激时,可以根据任务需要从特定的感觉模式中选择信息,同时从其他感觉通道中过滤掉无关信息。这种处理不同模态之间信息的注意力被称为跨模态注意力。并且存在着在所有感觉模式中共享的中心注意力资源:超模态注意力资源,可以分配在任务需要的所有模态中。随着超模态注意力资源被耗尽,以不同方式同时执行任务会受到不利影响。受人类系统的启发,在四足机器人的自主避障决策任务中加入跨模态注意力控制模块,从而在机器人上实现具有动态和上下文感知的轻量级四足机器人避障运动,机器人能够根据任务需要自主选择不同模态之间的信息切换。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296632.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表