一种基于非语义极大化剥离的内隐知识学习方法与流程
- 国知局
- 2024-10-15 10:19:44
本发明涉及人工智能,特别涉及一种基于非语义极大化剥离的内隐知识学习方法。
背景技术:
1、近年来,在大数据和人工智能领域,随着“数据红利”的消耗殆尽,知识的挖掘和积累对于人工智能技术的进一步发展显得更为重要。就目前而言,知识的载体是数据,但数据本身又是种类繁多、内容冗杂、价值参差的,因此“从数据到知识”至今仍是人工智能领域的一大研究热点,旨在让ai从“只会区分数据”到“会提炼数据、会加工数据、会运用数据”。
2、当前“数据→知识”的技术方法归纳起来大致分为以下几种:(1)抽取法,即直接从数据中抽取结构化知识,其代表便是知识图谱构建。(2)归纳法,即从一般性事实数据中总结归纳出规律性知识,其代表便是规律挖掘,通过从事实性数据中归纳得到规律性知识。(3)泛化法,即从某条件下的已知知识推广至具有某些共通性特点的其他方面知识,其代表便是知识类比或知识演绎,通过从特定的知识泛化出其他知识;(4)提炼法,即从价值稀疏的数据中凝练出框架性、主干性、概念内涵性的高价值知识,其代表便是研究报告中的思维知识提炼。例如从一篇研判分析某案例的医学报告中提炼出相关的专家分析视角类知识。
3、然而,上述主流方法还存在着各自的问题,抽取法只能实现“有什么抽什么”,不具备进一步总结归纳能力,并且抽取得到的结构化知识从语义上而言与数据中呈现的并无差异,对于大模型等处理能力较强的模型来说,一句包含知识的文本数据与抽取出的一条结构化知识,用于下游任务时并无明显差异;归纳法需要对若干事实性数据进行聚类、对同类数据中的主体进行概念抽象,需要依赖额外规则或其他处理模型;而泛化法和提炼法则过度依赖外部知识库或人工参与,尚无效果较好的智能化实现方法。
4、因此,当下亟需一种能够减少人工指导干预(如标注、制定规则模板等)、降低对外部知识库或其他模型依赖,自动从承载数据中学习到高价值的内隐知识的智能化知识学习方法,以提升从数据到知识的转换效率,更好地支撑知识库构建、知识推理与应用等下游任务。
技术实现思路
1、为解决上述问题,本发明提供了一种基于非语义极大化剥离的内隐知识学习方法,具体技术方案如下:
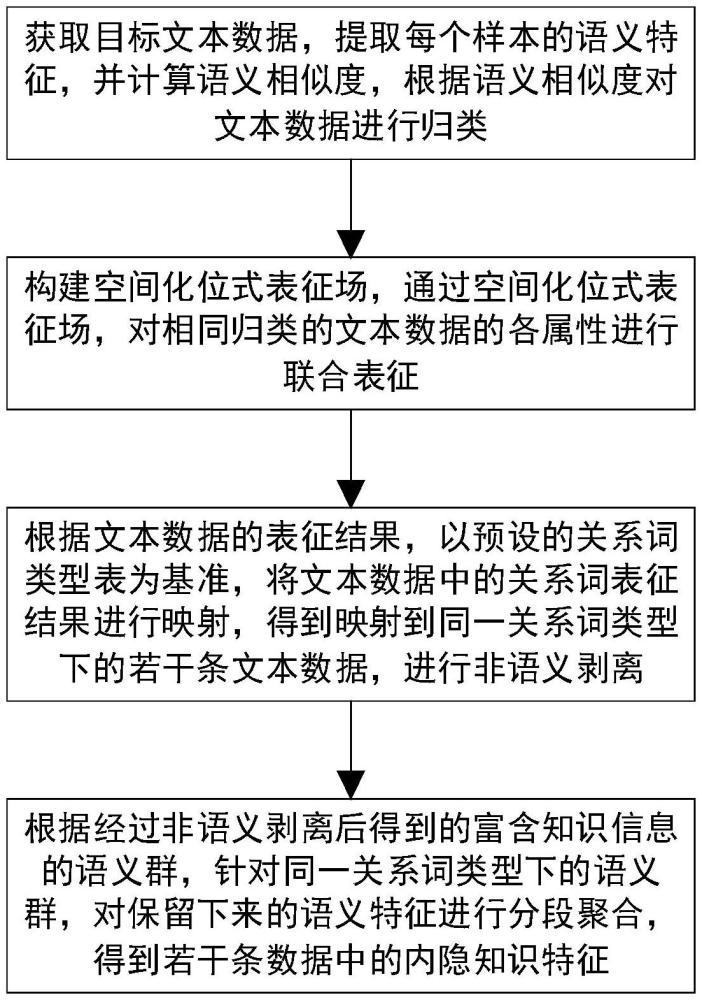
2、s1:获取目标文本数据,提取每个样本的语义特征,并计算语义相似度,根据语义相似度对文本数据进行归类;
3、s2:构建空间化位式表征场,通过空间化位式表征场,对相同归类的文本数据的各属性进行联合表征;
4、s3:根据文本数据的表征结果,以预设的关系词类型表为基准,将文本数据中的关系词表征结果进行映射,得到映射到同一关系词类型下的若干条文本数据,进行非语义剥离;
5、s4:根据经过非语义剥离后得到的富含知识信息的语义群,针对同一关系词类型下的语义群,对保留下来的语义特征进行分段聚合,得到若干条数据中的内隐知识特征。
6、进一步的,步骤s2中,通过空间化位式表征场,对文本数据的内容、位置、词性、关系词标记进行联合表征。
7、进一步的,对归类好的文本数据中的每条数据进行空间化位式表征,得到所述空间化位式表征场;
8、对相同归类的文本数据中的任意一条数据进行空间化位式表征,表示如下:
9、
10、其中,表示数据sj中的字的编码向量,p(ji)表示的位置码,pos(ji)表示的词性码,表示的关系词标记值。
11、进一步的,步骤s3中,将文本数据中的关系词表征结果进行映射,具体如下:
12、对归类好的文本数据中的每条数据,按照定义的多点特征拼接操作进行关系词定位与特征拼接,得到数据的关系词特征;
13、计算得到的关系词特征与所有关系词集合的相似度,将相似度高到的关系词所属的数据映射到同一个关系词类型下。
14、进一步的,步骤s3中,所述非语义剥离,具体如下:
15、对映射到同一关系词类型下的任意若干条文本数据,以关系词为中心进行端位补齐或修饰词侧位补齐操作,同时针对不同词性的词进行位点交或位点并处理。
16、进一步的,在以关系词为中心进行端位补齐或修饰词侧位补齐操作之前,还包括:
17、对所述若干条文本数据以关系词为基准进行三段式按位重排,并将关系词段补零对齐。
18、进一步的,以关系词为中心进行端位补齐或修饰词侧位补齐操作,具体如下:
19、对若干条文本数据的关系词段对齐后,根据文本数据的头段长度与尾段长度以及不同位置的字词性,基于如下规则进行相应的补齐操作:
20、若p=q,则将各文本数据的头段或尾段直接对齐;
21、反之,则对各文本数据的头段或尾段进行远端位补齐或非核心词性位补齐。
22、进一步的,在以关系词为中心进行端位补齐或修饰词侧位补齐操作之后,还包括:
23、对补齐后的文本数据,按照统一的词性排列顺序原则进行字序重排。
24、进一步的,所述词性排列顺序原则如下:
25、各文本数据的关系词保持字序不变;
26、各文本数据的头段按照u,num,adv,adj,n,v顺序进行字序重排;
27、各文本数据的尾段按照n,v,adj,adv,num,u顺序进行字序重排;
28、各文本数据中字的原始位置码保持不变。
29、进一步的,步骤s4中,所述分段聚合的具体过程如下:
30、针对同一关系词类型下的语义群,以关系词段特征为分界点,对语义群构成的集合中的头段特征群进行特征聚类,并得到该类的头段特征质心;
31、再对以头段特征聚类后的表示集合中的尾段特征群进行特征聚类。
32、本发明的有益效果如下:
33、本发明通过语义相似度对文本进行归类,之后对归类的数据进行后续处理,能够基于承载数据,并透过显性知识,自动发掘出数据中所蕴含的内隐知识;通过空间化位式表征场对归类后的数据进行全面的联合表征,并根据文本数据的表征结果,进行映射,对同一映射下的数据进行非语义剥离,在特征层面对承载数据中核心知识信息进行无监督式的快速重排序与筛选,大幅度提升了知识转化效率;最后通过在关系词对齐基础上进行多段式的特征聚合,能够不借助人工构建的知识库等外部信息,自动且准确地将内隐知识核心内涵信息保留下来,起到较好的泛化迁移作用;通过本发明的方法,面向从数据载体中自动学习出其所包涵知识的需求,实现了载体数据的去粗存精,以及数据内隐知识的高效学习。
技术特征:1.一种基于非语义极大化剥离的内隐知识学习方法,其特征在于,包括:
2.根据权利要求1所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,步骤s2中,通过空间化位式表征场,对文本数据的内容、位置、词性、关系词标记进行联合表征。
3.根据权利要求1所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,对归类好的文本数据中的每条数据进行空间化位式表征,得到所述空间化位式表征场;
4.根据权利要求1所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,步骤s3中,将文本数据中的关系词表征结果进行映射,具体如下:
5.根据权利要求1所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,步骤s3中,所述非语义剥离,具体如下:
6.根据权利要求5所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,在以关系词为中心进行端位补齐或修饰词侧位补齐操作之前,还包括:
7.根据权利要求5所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,以关系词为中心进行端位补齐或修饰词侧位补齐操作,具体如下:
8.根据权利要求5所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,在以关系词为中心进行端位补齐或修饰词侧位补齐操作之后,还包括:
9.根据权利要求8所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,所述词性排列顺序原则如下:
10.根据权利要求1所述的基于非语义极大化剥离的内隐知识学习方法,其特征在于,步骤s4中,所述分段聚合的具体过程如下:
技术总结本发明公开了一种基于非语义极大化剥离的内隐知识学习方法,包括S1:获取目标文本数据,提取每个样本的语义特征,并通过计算语义相似度对文本数据进行归类;S2:通过空间化位式表征场,对相同归类的文本数据的各属性进行联合表征;S3:根据文本数据的表征结果,以预设的关系词类型表为基准进行映射,得到映射到同一关系词类型下的若干条文本数据,进行非语义剥离得到的富含知识信息的语义群;S4:针对同一关系词类型下的语义群,对保留下来的语义特征进行分段聚合,得到若干条数据中的内隐知识特征。本发明基于承载数据,透过显性知识,自动发掘出数据中所蕴含的内隐知识,实现了载体数据的去粗存精和数据内隐知识的高效学习。技术研发人员:刘鑫,张海瀛,李春豹,戴礼灿受保护的技术使用者:中国电子科技集团公司第十研究所技术研发日:技术公布日:2024/10/10本文地址:https://www.jishuxx.com/zhuanli/20241014/317279.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。