一种用于眼科OCT的抖动畸变矫正图像处理系统
- 国知局
- 2024-11-25 15:17:16
本发明属于图像处理,具体涉及一种用于眼科oct的抖动畸变矫正图像处理系统。
背景技术:
1、眼底光学相干断层扫描(optical coherence tomography,oct)是一种高分辨率的成像技术,广泛应用于眼科诊断和研究。由于其无创、快速和高分辨率的特点,oct已成为诊断和监测大多数视网膜疾病的成像方法。在对眼底图像采集的过程中,头部运动、呼吸、血管搏动和不自主注视眼球运动会引起图像的畸变。对这种运动的校正是 oct 成像的主要挑战之一,因为运动畸变不仅会影响体积数据的分割效果,还会降低视网膜生物标志物的可靠性,影响对眼部疾病的诊断。因此寻找一种快速,精准的方法来对oct图像配准与分割显得尤为重要。
2、现有的 oct 运动校正方法可分为硬件方法和软件方法,虽然基于硬件的方法效果通常不错,但它们并不可用与所有的oct系统,并且会增加硬件搭建需要的成本。传统软件算法方法大多数需要多个oct体积数据或多模态图像作为参考,这给临床环境带来了额外的负担。深度学习方法在解决oct图像中的运动伪影问题方面展示了巨大的潜力。深度学习模型能够通过学习大量的oct图像数据来提取更具有判别性的特征以生成位移向量来指导oct图像的配准,然而使用深度学习配准仍然面临一些挑战。首先,眼科oct畸变图像的数据量有限,而深度学习模型需要大量的数据训练,以避免过拟合。其次,目前的数据集并没有矫正畸变后的体数据,oct图像的标注过程耗时且需要专业知识,尤其是对于三维体数据的配准标注,难度更大。
技术实现思路
1、本发明一方面提供一种用于眼科oct的抖动畸变矫正图像处理系统,解决目前方法中需要大量的体数据作为参考,且用时长,导致诊断系统复杂的问题。
2、本发明是这样实现的,
3、一种用于眼科oct的抖动畸变矫正图像处理系统,该系统包括:
4、采集数据模块,使用sd-oct采集设备采集人眼视网膜的图像,采集的图像为3d体数据,由眼科专家进行注释,所述注释包括标注是否存在畸形以及是否属于患病的图像,并对视网膜的层结构进行分割处理,所述层结构包括视网膜神经纤维层、神经节细胞层、内丛状层、内核层、外丛状层、外核层、外界膜以及视网膜色素上皮层,在图像中用不同颜色标注出不同层;
5、数据集划分模块,将采集并注释的图像分成不同的子集,所述子集包括正常形态图像数据集和不正常形态图像数据集,将这两个数据集分别按1:3的比例随机划分,分别作为测试数据集和训练数据集;
6、数据增强模块,将训练数据集进行数据增强,通过旋转、翻转、缩放、裁剪、调整亮度和对比度、弹性变换以及色彩空间变换,扩充训练数据集的数据样本;
7、任务建立模块,建立训练任务、测试任务以及检测任务;
8、网络模型,执行训练任务,采用训练数据集进行训练,得到训练好的权重文件用于测试任务;执行测试任务,采用测试数据集对网络模型性能进行评估;执行检测任务,利用训练好的网络模型处理需要检测的人眼视网膜的图像;
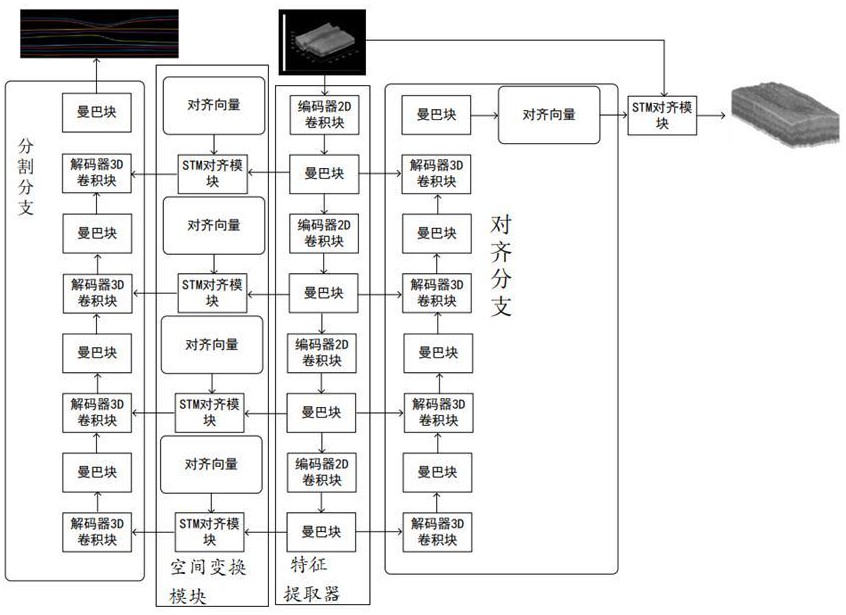
9、所述网络模型包括:
10、特征提取器,将输入的图像编码成特征图;
11、对齐分支,将特征提取器提取的特征图经由对齐分支的解码器3d卷积块处理,输出一个对齐向量;
12、空间变换模块,根据对齐分支输出的对齐向量,调整3d体数据中b扫描的位置,并对特征提取器输出的特征图进行对齐,完成对齐任务;
13、分割分支,采用分割分支解码器将经由空间变换模块对齐的特征图逐步恢复到原始分辨率, 最终将特征图转化为分割结果的概率图,输出每个 a扫描的表面位置分布。
14、进一步地,所述特征提取器包括依次向下输出的四层降采样模块,每层降采样模块包括编码器2d卷积块和曼巴块,每个降采样模块中的编码器2d卷积块的输出端设置一个曼巴块,上层的编码器2d卷积块的输出端设置的曼巴块输出到下一层的编码器2d卷积块。
15、进一步地,每层降采样模块的处理过程为:
16、,
17、,
18、其中x为上一层的输出,当前层的输入,在最开始是输入的图像,在中间层为特征图,y为上一层的输出,当前层的输入,z 为当前层的输出 ;norm()是归一化操作,relu()是深度学习中一种激活函数,conv2d()是2维卷积,仅在编码器2d卷积块中使用,表示曼巴操作,最开始输入的图像是3d体数据,表示为 [b,c,h,w,d],b为输入数据的批次,c为输入数据的维度,h,w,d分别为高度、宽度和深度,将输入的图像数据展平为:[b*c,d,h,w]。
19、进一步地,所述对齐分支包括四层对齐分支的解码器3d卷积块,每层对齐分支的解码器3d卷积块均与一个降采样中相同层的曼巴块的输出连接,每层对齐分支的解码器3d卷积块的输出端设置一个曼巴块,数据由下往上经由四层对齐分支的解码器3d卷积块,形成上采样,经过最上层的曼巴块输出对齐向量。
20、进一步地,所述对齐向量表示为:,其中每个元素表示 b扫描在z方向上的位移,,代表3d体数据包含二维数据的个数 ,即oct数据的b扫描个数。
21、进一步地,所述空间变换模块设置在对齐分支中最上层的曼巴块的输出端,并接收3d体数据,根据对齐向量对3d体数据进行对齐;
22、所述空间变换模块还分别设置在每层降采样模块的曼巴块与分割分支对应层的分割分支解码器之间,根据对齐向量对每层降采样模块输出的特征图进行对齐,并输出至分割分支对应层的分割分支解码器中。
23、进一步地,所述空间变换模块包括定位网络、参数化变换模块、采样网格生成模块和重采样器,其中定位网络根据输入特征图预测空间变换参数 θ,
24、,
25、是由输入特征图 x生成空间变换参数的函数, θ为空间变换参数;
26、参数化变换模块使用定位网络预测的空间变换参数 θ来构造一个变换矩阵,变换矩阵为:
27、,
28、是由变换参数 θ构建的一个变换矩阵;
29、采样网格生成器根据输入特征图的大小和变换矩阵生成一个采样网格,采样网格生成器输出一个采样网格,其中g是标准网格坐标,
30、
31、所述重采样器根据采样网格对输入特征图进行采样,输出新的特征图。
32、进一步地,所述分割分支包括四层分割分支解码器,每层分割分支解码器的输入对应一层空间变换模块的输出,每个分割分支解码器的输出设置一个曼巴块,数据由下往上处理形成上采样,由最上层的曼巴块输出最终数据。
33、进一步地,各层编码器2d卷积块输出的特征图经过对齐后与分割分支中对应层的前一层分割分支解码器输出的特征图拼接后,再送入当前层的分割分支解码器进行解码。
34、进一步地,所述曼巴块输入的数据为输入张量,对输入张量进行形状重塑,通过调整张量的维度,使输入张量适应ssm算法的输入要求;张量展平后进行归一化处理,用于减少网络模型对输入数据尺度变化的敏感性;归一化处理后分成两个分支,分别进入一个全连接层进行线性投影,其中一个分支通过silu激活函数,引入非线性特性;另一个分支进行1d因果卷积操作,用于确保当前时刻的输出仅依赖于当前及之前的输入,1d因果卷积的输出经过一个silu激活函数后进入ssm算法;之后两个分支的输出数据通过全连接层进行线性投影合并,并重塑张量的形状。
35、本发明与现有技术相比,有益效果在于:
36、传统方法在处理不同设备和患者的数据时,容易受到设备差异和个体差异的影响,导致结果不稳定。本发明通过大量多样化数据的训练,提高了系统的稳定性和鲁棒性,能够适应不同的设备和患者数据。基于硬件的oct图像处理方法通常需要额外的设备和传感器,增加了系统的复杂性和成本。本发明通过纯软件的方法实现高效的图像处理,降低了硬件依赖,显著减少了对大规模参考数据的依赖,提高了处理效率,从而减少了系统搭建的成本和复杂性。
37、本发明方法通过将对齐网络加入到分割网络中从而将两个图像处理任务结合起来。可以通过深度学习网络的一个对齐分支,将图像和特征对齐,改善oct3d图像的分割效果,精准地分割并识别出眼底视网膜的形态变化。将图像对齐和分割任务结合在一个深度学习模型中,实现了协同优化,显著提高了图像处理的整体效果。这种整合方法打破了传统上将对齐和分割任务分开处理的局限,提供了更高效的解决方案。在网络模型训练过程中采用了深度学习技术,如数据增强、迁移学习和多任务学习,确保了网络模型的高效训练。同时,优化的网络模型架构和推理算法保证了快速的图像处理能力,打破了深度学习模型在实际应用中的性能瓶颈。
本文地址:https://www.jishuxx.com/zhuanli/20241125/337119.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表