一种面向骑行者的自动驾驶避撞方法及系统
- 国知局
- 2024-12-06 12:21:47
本公开属于自动驾驶,尤其涉及一种面向骑行者的自动驾驶避撞方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
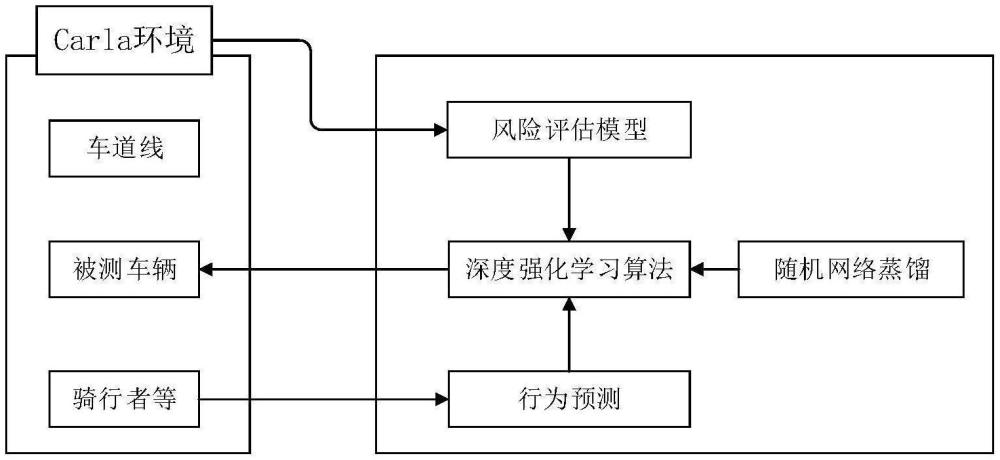
2、避撞(collision avoidance,ca)是自动驾驶汽车实现安全高效驾驶的核心问题。然而,交通环境的不确定性和动态变化使得这成为一项具有挑战性的任务。近年来,随着感知、控制、规划和人工智能技术的迅速发展,各种有效的ca技术相继涌现。
3、现有的避撞方法通常可以分为两类,分别为经典确定性方法和基于学习的方法。其中,经典确定性方法的一个局限性是,它们只产生确定性的行为,受到环境干扰较大,同时忽略了人类驾驶员的学习特征。而基于学习的方法中的监督学习需要大量的标记交通数据,并且需要进行大量的训练,交通数据标记不全,会导致无法识别而造成交通事故,特别是危险场景的数据很难大量获得,这导致训练前期的过程相当繁琐。因此,无需标注数据,在与环境的交互过程中进行“试错学习”的深度强化学习更适用于ca领域。
4、目前的汽车主动安全系统多针对行人保护,然而,在复杂的混合道路交通环境中,骑车者的行为特性与行人显著不同,主要包括以下几个特点:骑行者(可以具有不同骑行工具,如自行车、电动自行车等)占比较大;安全意识薄弱,闯红灯、逆行、载人和违规闯入机动车道等违规现象频繁;目标运动多变,个体行为具有高度的随机性和不确定性,这些骑行者特有的行为属性使得现有主动安全系统难以进行有效的保护,基于上述特点,当前针对行人保护的汽车主动安全系统无法适用于骑行者的避撞。
技术实现思路
1、本发明提供了一种面向骑行者的自动驾驶避撞方法及系统,以解决现有的汽车主动安全系统无法有效适应包括骑行者在内的复杂混合道路交通环境的避障问题。
2、根据本公开实施例的第一个方面,提供了一种面向骑行者的自动驾驶避撞方法,包括:
3、实时获取自车状态信息和周围环境状态信息;其中,所述周围环境状态信息包括静态障碍物、动态障碍物以及道路标志相关信息,所述动态障碍物至少包括动态骑行者;
4、基于获得的自车状态数据和周围环境状态数据,通过预先训练的深度强化学习模型,获得自车输出动作,实现自车的避撞;
5、其中,所述深度强化学习模型的奖励函数基于基准奖励与自车当前位置的风险奖励的差值得到,所述自车当前位置的风险奖励的获取,基于获得的静态障碍物相关信息、动态障碍物相关信息、以及道路标志相关信息,通过预先构建的基于行车风险场的风险评估模型得到,所述动态障碍物相关信息包括预测的动态障碍物的未来动作。
6、进一步的,所述基于行车风险场的风险评估模型,具体由静态障碍物风险场、动态障碍物风险场以及道路标志相关风险场的加权求和得到。
7、进一步的,所述静态障碍物风险场,基于自车当前位置到静态障碍物的距离得到;所述动态障碍物风险场基于预测的动态障碍物的未来动作以及当前的纵横向特征得到,具体表示如下:
8、
9、
10、
11、其中,vitx为动态障碍物在x方向上的速度大小;vity为动态障碍物在y方向上的速度大小;aitx为动态障碍物在x方向上的加速度大小;aity为动态障碍物在y方向上的加速度大小,xobs(t)和yobs(t)为t时刻动态障碍物的位置,x和y为自车当前位置。
12、进一步的,所述动态障碍物的未来动作,基于获取的动态障碍物的横纵向特征,利用预先训练的行为预测模型获得。
13、进一步的,所述道路标志相关风险场,包括车道风险场和车道偏离风险场,所述车道风险场通过自车位置距离车道标线的距离得到;所述车道偏离风险场基于自车位置距离车道中心的距离得到。
14、进一步的,所述深度强化学习模型的奖励函数中还包括随机网络蒸馏输出的内在奖励,通过随机网络蒸馏技术提高深度强化学习模型的收敛速度。
15、根据本公开实施例的第二个方面,提供了一种面向骑行者的自动驾驶避撞系统,包括:
16、状态信息获取单元,其用于实时获取自车状态信息和周围环境状态信息;其中,所述周围环境状态信息包括静态障碍物、动态障碍物以及道路标志相关信息,所述动态障碍物至少包括动态骑行者;
17、避撞单元,其用于基于获得的自车状态数据和周围环境状态数据,通过预先训练的深度强化学习模型,获得自车输出动作,实现自车的避撞;
18、其中,所述深度强化学习模型的奖励函数基于基准奖励与自车当前位置的风险奖励的差值得到,所述自车当前位置的风险奖励的获取,基于获得的静态障碍物相关信息、动态障碍物相关信息、以及道路标志相关信息,通过预先构建的基于行车风险场的风险评估模型得到,所述动态障碍物相关信息为预测的动态障碍物的未来动作。
19、根据本公开实施例的第三个方面,提供了一种电子设备,包括存储器、处理器及存储在存储器上运行的计算机程序,所述处理器执行所述程序时实现所述的一种面向骑行者的自动驾驶避撞方法。
20、根据本公开实施例的第四个方面,提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的一种面向骑行者的自动驾驶避撞方法。
21、根据本公开实施例的第五个方面,提供了一种计算机程序产品,其包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现所述的一种面向骑行者的自动驾驶避撞方法。
22、与现有技术相比,本公开的有益效果是:
23、(1)本公开提供了一种面向骑行者的自动驾驶避撞方法及系统,所述方案通过将动态障碍物(即骑行者)的行为预测与风险评估相结合,将获得的自车风险引入深度强化学习模型的奖励函数中,能够有效应对包括骑行者在内的复杂混合道路交通环境的避障问题。
24、(2)本公开所述方案基于深度强化学习模型,基于周围环境状态信息来在训生成自车动作,其期过程不需要对交通数据进行大量的标记,相对于监督学习更加便捷、简单;同时,在深度强化学习模型中通过引入随机网络蒸馏,有效提高了深度强化学习模型在训练过程中的收敛速度。
25、(3)本公开所述方案通过在carla环境中搭建复杂的交通场景进行测试,可以有效节省测试时间,加速模型的实车部署。
26、本公开附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本公开的实践了解到。
技术特征:1.一种面向骑行者的自动驾驶避撞方法,其特征在于,包括:
2.如权利要求1所述的一种面向骑行者的自动驾驶避撞方法,其特征在于,所述基于行车风险场的风险评估模型,具体由静态障碍物风险场、动态障碍物风险场以及道路标志相关风险场的加权求和得到。
3.如权利要求2所述的一种面向骑行者的自动驾驶避撞方法,其特征在于,所述静态障碍物风险场,基于自车当前位置到静态障碍物的距离得到;所述动态障碍物风险场基于预测的动态障碍物的未来动作以及当前的纵横向特征得到,具体表示如下:
4.如权利要求3所述的一种面向骑行者的自动驾驶避撞方法,其特征在于,所述动态障碍物的未来动作,基于获取的动态障碍物的横纵向特征,利用预先训练的行为预测模型获得。
5.如权利要求2所述的一种面向骑行者的自动驾驶避撞方法,其特征在于,所述道路标志相关风险场,包括车道风险场和车道偏离风险场,所述车道风险场通过自车位置距离车道标线的距离得到;所述车道偏离风险场基于自车位置距离车道中心的距离得到。
6.如权利要求1所述的一种面向骑行者的自动驾驶避撞方法,其特征在于,所述深度强化学习模型的奖励函数中还包括随机网络蒸馏输出的内在奖励,通过随机网络蒸馏技术提高深度强化学习模型的收敛速度。
7.一种面向骑行者的自动驾驶避撞系统,其特征在于,包括:
8.一种电子设备,包括存储器、处理器及存储在存储器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-6任一项所述的一种面向骑行者的自动驾驶避撞方法。
9.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-6任一项所述的一种面向骑行者的自动驾驶避撞方法。
10.一种计算机程序产品,其包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如权利要求1-6任一项所述的一种面向骑行者的自动驾驶避撞方法。
技术总结本公开提供了一种面向骑行者的自动驾驶避撞方法及系统,包括:实时获取自车状态信息和周围环境状态信息;其中,所述周围环境状态信息包括静态障碍物、动态障碍物以及道路标志相关信息,所述动态障碍物至少包括动态骑行者;基于获得的自车状态数据和周围环境状态数据,通过预先训练的深度强化学习模型,获得自车输出动作,实现自车的避撞;其中,所述深度强化学习模型的奖励函数基于基准奖励与自车当前位置的风险奖励的差值得到,所述自车当前位置的风险奖励的获取,基于获得的静态障碍物相关信息、动态障碍物相关信息、以及道路标志相关信息,通过预先构建的基于行车风险场的风险评估模型得到,所述动态障碍物相关信息包括预测的动态障碍物的未来动作。技术研发人员:范新建,范少辉,王勇,车晓波,王磊受保护的技术使用者:山东省科学院自动化研究所技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/340920.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。