可重入生产系统调度方法、装置、介质及电子设备与流程
- 国知局
- 2024-07-31 23:55:51
本发明涉及生产调度,尤其涉及一种可重入生产系统调度方法、装置、介质及电子设备。
背景技术:
1、生产系统调度问题是指通过合理安排工件在各机器上的加工顺序,以提高企业生产效率、降低生产成本。可重入生产系统是继flow-shop(流水车间)和job-shop(作业车间)之后的第三类生产系统,半导体生产车间是可重入生产系统的典型代表,工件在工艺流程的不同阶段使用同一台设备进行加工,由于存在重入,加剧了工件对设备的竞争,给可重入生产系统的调度带来了极大的困难。
2、目前应用广泛的在线调度方法是启发式规则方法,但是启发式规则不具有泛化性,不同的启发式规则适用的加工场景不同。而且,启发式规则具有短视性,即调度结果会随着决策步数的增加远远差于最优解。
3、强化学习作为一种新兴的人工智能技术,也开始被应用于解决车间生产调度问题。强化学习可以根据系统环境变化实时快速地给出优化调度方案,但现有方法均未将强化学习技术有效应用于可重入生产系统调度。强化学习算法用来求解马尔可夫决策过程(mdp),马尔可夫决策过程由<a,s,r,p>表示,其中,a为动作空间集,s为状态空间集,r为奖励函数,p表示状态转移概率(在状态s下执行动作a后,转移到另一个状态s’的概率)。强化学习算法要求求解的问题具有马尔可夫特性:即在时间步t的状态s(t)下,采取动作a(t)后的状态s(t+1)和收益r(t+1)只与当前状态和动作有关,与历史状态无关。与流水车间和作业车间不同,可重入生产系统不具备马尔可夫特性,不能直接使用基于强化学习的调度方法。
技术实现思路
1、本发明的目的在于提供一种可重入生产系统调度方法、装置、介质及电子设备,用以改善可重入生产系统的调度困难的问题。
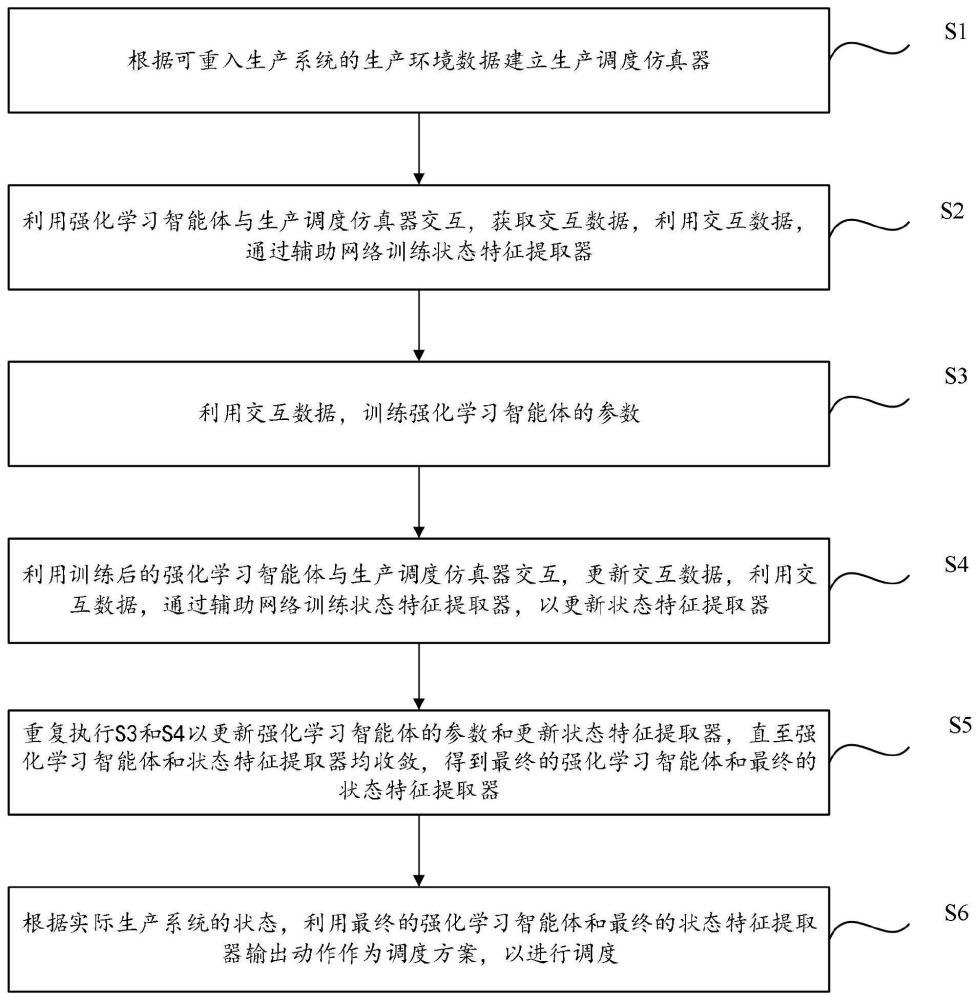
2、第一方面,本发明提供的方法包括:s1:根据可重入生产系统的生产环境数据建立生产调度仿真器;s2:利用强化学习智能体与所述生产调度仿真器交互,获取交互数据,利用所述交互数据,通过辅助网络训练状态特征提取器;s3:利用所述交互数据,训练所述强化学习智能体的参数;s4:利用训练后的所述强化学习智能体与所述生产调度仿真器交互,更新所述交互数据,利用所述交互数据,通过所述辅助网络训练所述状态特征提取器,以更新所述状态特征提取器;s5:重复执行s3和s4以更新所述强化学习智能体的参数和更新所述状态特征提取器,直至所述强化学习智能体和所述状态特征提取器均收敛,得到最终的强化学习智能体和最终的状态特征提取器;s6:根据实际生产系统的状态,利用所述最终的强化学习智能体和所述最终的状态特征提取器输出动作作为调度方案,以进行调度。
3、本发明提供的可重入生产系统调度方法的有益效果在于:针对可重入生产系统的特点,设计了状态特征提取器,通过辅助网络对状态特征提取器进行训练,使得通过状态特征提取器编码的状态具有马尔科夫特性,能够使用强化学习算法进行动态调度。进一步,本发明将状态特征提取器与强化学习智能体交替训练以进行更新,利用强化学习智能体训练后产生的数据更新状态特征提取器的参数,不断提升状态特征提取器和强化学习智能体的精度。
4、一种可能的实施例中,所述生产环境数据包括:生产加工的状态数据、产品工艺流程数据和生产设备配置数据;利用所述强化学习智能体与所述生产调度仿真器交互,包括:利用强化学习智能体与所述生产调度仿真器交互获取状态动作序列;根据所述产品工艺流程数据,计算生产系统的最大可重入步数n;利用所述状态动作序列,得到k组长度为n的系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)},其中,t为时间,s(t)为状态,k和n均为正整数。
5、另一种可能的实施例中,所述交互数据包括:系统状态对和动作a(t);利用所述交互数据,通过辅助网络训练状态特征提取器,包括:将所述系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)}分别输入状态特征提取器,得到提取出的状态特征f(t)和f(t+1);将所述提取出的状态特征f(t)和f(t+1)同时输入辅助神经网络,得到使用梯度下降法训练所述状态特征提取器和所述辅助神经网络,应用的损失函数为与a(t)的交叉熵,当所述损失函数收敛时,得到所述状态特征提取器的参数。
6、其它可能的实施例中,所述交互数据包括:系统状态对和动作a(t);利用所述交互数据,训练所述强化学习智能体的参数,包括:将所述系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)}分别输入所述状态特征提取器,得到提取出的状态特征f(t)和f(t+1);利用所述提取出的状态特征,使用梯度下降法,更新所述强化学习智能体的价值网络的参数和策略网络的参数;反复更新所述强化学习智能体的价值网络的参数和策略网络的参数,直至所述价值网络和所述策略网络收敛。
7、利用所述提取出的状态特征,使用梯度下降法,更新所述强化学习智能体的价值网络的参数和策略网络的参数,包括:将所述提取出的状态特征f(t)和f(t+1)分别输入所述强化学习智能体的价值网络,得到状态价值函数v(s(t))和v(s(t+1));所述交互数据还包括奖励r,所述价值网络的损失函数为td error=[r+γv(s(t+1))-v(s(t))]2,使用梯度下降法更新所述价值网络的参数,其中,γ为参数;将所述提取出的状态特征f(t)输入所述强化学习智能体的策略网络,得到策略π;所述策略网络的损失函数为l=-(r+γv(s(t+1))-v(s(t)))log(π(a|s,θ)),使用梯度下降法更新所述策略网络的参数,其中,θ为参数。
8、根据实际生产系统的状态输出动作,利用所述最终的强化学习智能体和所述最终的状态特征提取器给出调度方案,包括:将生产系统的n步状态输入所述最终的状态特征提取器,得到状态特征,n为生产系统的最大可重入步数;将所述状态特征输入所述强化学习智能体的策略网络,得到调度策略;根据所述调度策略输出动作作为调度方案以进行调度。
9、生产调度仿真器用于模拟生产环境、获取生产系统的状态,状态特征提取器用于对生产系统的n步状态进行编码,使得通过最终的强化学习智能体和最终的状态特征提取器能够输出可重入生产系统的最优调度方案,将最优调度方案交由可重入生产系统执行。
10、第二方面,本发明还提供了一种可重入生产系统调度装置,所述装置包括:
11、生产调度仿真单元,用于根据可重入生产系统的生产环境数据建立生产调度仿真器;
12、第一状态特征提取训练单元,用于利用强化学习智能体与所述生产调度仿真器交互,获取交互数据,利用所述交互数据,通过辅助网络训练状态特征提取器;
13、强化学习单元,用于利用所述交互数据,训练所述强化学习智能体的参数;
14、第二状态特征提取训练单元,用于利用训练后的所述强化学习智能体与所述生产调度仿真器交互,更新所述交互数据,利用所述交互数据,通过所述辅助网络训练所述状态特征提取器,以更新所述状态特征提取器;
15、重复训练单元,用于重复执行所述强化学习单元训练所述强化学习智能体的参数和所述第二状态特征提取训练单元更新所述交互数据并更新所述状态特征提取器的操作,以更新所述强化学习智能体的参数和更新所述状态特征提取器,直至所述强化学习智能体和所述状态特征提取器均收敛,得到最终的强化学习智能体和最终的状态特征提取器;
16、调度单元,用于根据实际生产系统的状态,利用所述最终的强化学习智能体和所述最终的状态特征提取器输出动作作为调度方案,以进行调度。
17、所述生产环境数据包括:生产加工的状态数据、产品工艺流程数据和生产设备配置数据;所述第一状态特征提取训练单元和所述第二状态特征提取训练单元利用所述强化学习智能体与所述生产调度仿真器交互,具体用于:
18、利用强化学习智能体与所述生产调度仿真器交互获取状态动作序列;
19、根据所述产品工艺流程数据,计算生产系统的最大可重入步数n;
20、利用所述状态动作序列,得到k组长度为n的系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)},其中,t为时间,s(t)为状态,k和n均为正整数。
21、所述交互数据包括:系统状态对和动作a(t);所述第一状态特征提取训练单元和所述第二状态特征提取训练单元利用所述交互数据,通过辅助网络训练状态特征提取器,具体用于:
22、将所述系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)}分别输入状态特征提取器,得到提取出的状态特征f(t)和f(t+1);
23、将所述提取出的状态特征f(t)和f(t+1)同时输入辅助神经网络,得到
24、使用梯度下降法训练所述状态特征提取器和所述辅助神经网络,应用的损失函数为与a(t)的交叉熵,当所述损失函数收敛时,得到所述状态特征提取器的参数。
25、所述交互数据包括:系统状态对和动作a(t);所述强化学习单元利用所述交互数据,训练所述强化学习智能体的参数,具体用于:
26、将所述系统状态对{s(t-n),…,s(t)},{s(t+1-n),…,s(t+1)}分别输入所述状态特征提取器,得到提取出的状态特征f(t)和f(t+1);
27、利用所述提取出的状态特征,使用梯度下降法,更新所述强化学习智能体的价值网络的参数和策略网络的参数;
28、反复更新所述强化学习智能体的价值网络的参数和策略网络的参数,直至所述价值网络和所述策略网络收敛。
29、利用所述提取出的状态特征,使用梯度下降法,更新所述强化学习智能体的价值网络的参数和策略网络的参数,包括:
30、将所述提取出的状态特征f(t)和f(t+1)分别输入所述强化学习智能体的价值网络,得到状态价值函数v(s(t))和v(s(t+1));
31、所述交互数据还包括奖励r,所述价值网络的损失函数为td error=[r+γv(s(t+1))-v(s(t))]2,使用梯度下降法更新所述价值网络的参数,其中,γ为参数;
32、将所述提取出的状态特征f(t)输入所述强化学习智能体的策略网络,得到策略π;
33、所述策略网络的损失函数为l=-(r+γv(s(t+1))-v(s(t)))log(π(a|s,θ)),使用梯度下降法更新所述策略网络的参数,其中,θ为参数。
34、所述调度单元根据实际生产系统的状态输出动作,利用所述最终的强化学习智能体和所述最终的状态特征提取器给出调度方案,具体用于:
35、将生产系统的n步状态输入所述最终的状态特征提取器,得到状态特征,n为生产系统的最大可重入步数;
36、将所述状态特征输入所述强化学习智能体的策略网络,得到调度策略;
37、根据所述调度策略输出动作作为调度方案以进行调度。
38、第三方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述可重入生产系统调度方法。
39、第四方面,本发明还提供了一种电子设备,包括:处理器及存储器;所述存储器用于存储计算机程序;所述处理器用于执行所述存储器存储的计算机程序,以使所述电子设备执行上述可重入生产系统调度方法。
40、关于上述第二方面至第四方面的有益效果可以参见上述第一方面的描述。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199232.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表