基于特征融合的半监督学习方法、系统、终端及存储介质
- 国知局
- 2024-09-05 14:36:09
本发明属于深度学习,具体涉及一种基于特征融合的半监督学习方法、系统、终端及存储介质。
背景技术:
1、分类器常被用到设备的故障检测、图像识别等领域,是工业智能化发展的重要技术。分类器在应用之前需要进行数据训练,训练数据应当是被标记对应标签的样本,如此分类器可在训练过程中训练自身的权重,而权重值影响分类器的识别准确度。
2、标记数据的获取通常是非常昂贵和耗时的过程。相比之下,未标记数据的获取成本较低。因此,半监督学习作为一种利用有限标记数据和大量未标记数据进行学习的方法,受到了广泛的关注。半监督学习的目标是通过充分利用未标记数据的信息,提高分类器的性能。传统的方法通常以模型输出的置信度作为判断伪标签的依据,即如果置信度超过阈值,就把网络预测结果作为该样本的伪标签。
3、然而,在模型训练前期,模型并不能对无标签样本做出正确的判断,因此会有大量样本即使置信度高,但模型预测结果仍然是错误的,这种错误将随着模型训练过程不断加强,导致模型效果极差。
4、因此,当标记数据占比较低时,采用半监督学习的分类器准确度较差,无法达到应用需求。
技术实现思路
1、针对现有技术的上述不足,本发明提供一种基于特征融合的半监督学习方法、系统、终端及存储介质,以解决上述技术问题。
2、第一方面,本发明提供一种基于特征融合的半监督学习方法,包括:
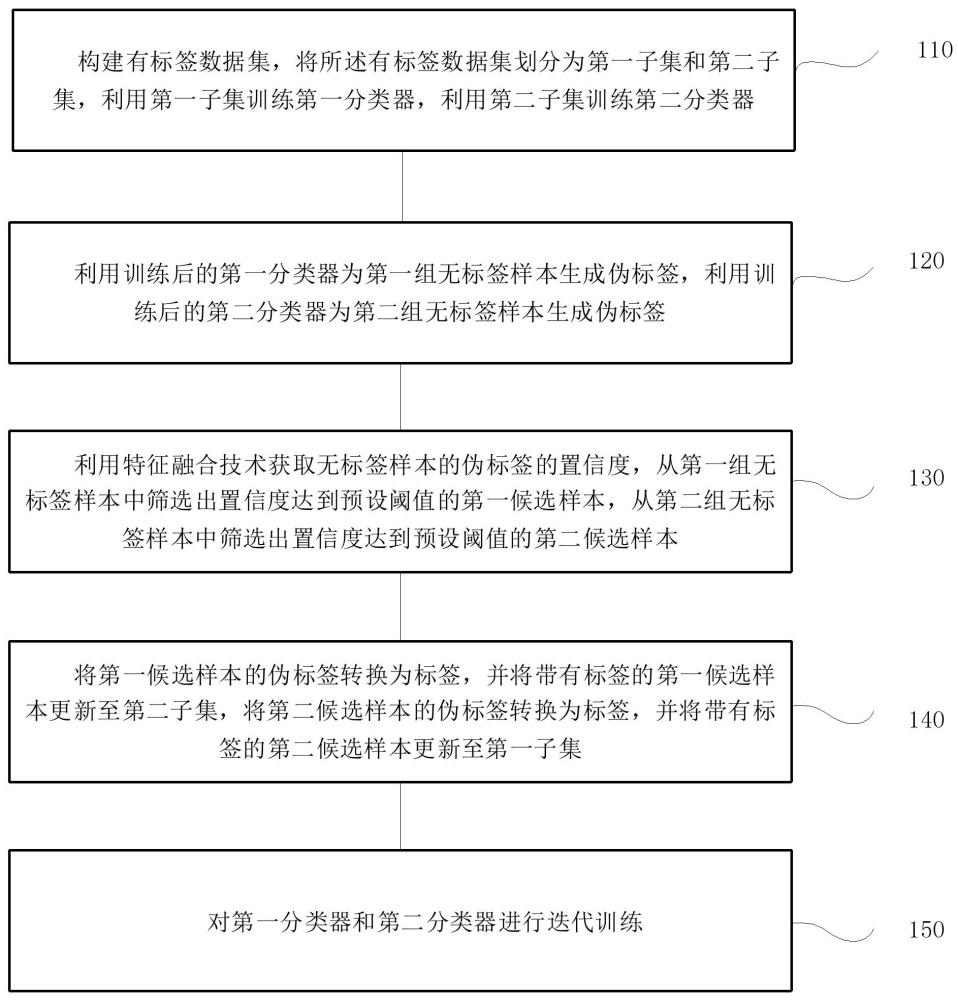
3、构建有标签数据集,将所述有标签数据集划分为第一子集和第二子集,利用第一子集训练第一分类器,利用第二子集训练第二分类器;
4、利用训练后的第一分类器为第一组无标签样本生成伪标签,利用训练后的第二分类器为第二组无标签样本生成伪标签;
5、利用特征融合技术获取无标签样本的伪标签的置信度,从第一组无标签样本中筛选出置信度达到预设阈值的第一候选样本,从第二组无标签样本中筛选出置信度达到预设阈值的第二候选样本;
6、将第一候选样本的伪标签转换为标签,并将带有标签的第一候选样本更新至第二子集,将第二候选样本的伪标签转换为标签,并将带有标签的第二候选样本更新至第一子集;
7、对第一分类器和第二分类器进行迭代训练。
8、在一个可选的实施方式中,构建有标签数据集,将所述有标签数据集划分为第一子集和第二子集,利用第一子集训练第一分类器,利用第二子集训练第二分类器,包括:
9、将有标签数据集按样本数量平均划分为第一子集和第二子集;
10、构建第一分类器,所述第一分类器包括wideresnet和shake_drop2;
11、构建第二分类器,所述第二分类器包括densenet_cifar和shake_drop2;
12、将第一子集设置为第一分类器的训练集,将第二子集设置为第二分类器的训练集。
13、在一个可选的实施方式中,利用训练后的第一分类器为第一组无标签样本生成伪标签,利用训练后的第二分类器为第二组无标签样本生成伪标签,包括:
14、预先收集无标签样本,并将无标签样本保存至无标签数据集;
15、设置无标签样本组的样本数量,基于所述样本数量随机从无标签数据集提取相应数量的无标签样本组,将无标签样本组设置为第一组无标签样本,将无标签样本组的副本设置为第二组无标签样本;
16、利用第一分类器对第一组无标签样本逐一识别,并将识别结果设置为相应无标签样本的伪标签,将添加伪标签的无标签样本保存至第一中间样本集;
17、利用第二分类器对第二组无标签样本逐一识别,并将识别结果设置为相应无标签样本的伪标签,将添加伪标签的无标签样本保存至第二中间样本集。
18、在一个可选的实施方式中,利用特征融合技术获取无标签样本的伪标签的置信度,包括:
19、将有标签样本按标签类别进行分类,利用特征提取网络提取每一类的有标签样本的特征图,并将每一类有标签样本的所有特征图的平均值设置为相应类别有标签样本的特征锚点;
20、选取带有伪标签的无标签样本,利用特征提取网络提取所述无标签样本的特征图;
21、将所述特征图与每个类别的特征锚点进行插值融合得到多个相应的融合特征图;
22、利用对应的分类器分别基于所述无标签样本的特征图和目标类别的融合特征图生成相应的分类结果,并计算分类结果之间的范数;
23、遍历所有类别,将得到的多个所述范数之和作为所述无标签样本特征融合前后的预测结果的总距离;
24、将所述总距离转换为置信度,总距离与置信度成反比。
25、在一个可选的实施方式中,将所述特征图与每个类别的特征锚点进行插值融合得到融合特征图
26、使用插值比 α ∈ [0, 1) d ;
27、插值公式为:zα= αz∗+ (1 − α)zu,其中,zα为融合特征图,zu无标签样本的特征图,z∗是目标类别的特征锚点。
28、在一个可选的实施方式中,对第一分类器和第二分类器进行迭代训练,包括:
29、利用更新的第一子集和第二子集分别对第一分类器和第二分类器进行迭代训练,直至无标签数据集中不存在未处理过的无标签样本。
30、第二方面,本发明提供一种基于特征融合的半监督学习系统,包括:
31、基础训练模块,用于构建有标签数据集,将所述有标签数据集划分为第一子集和第二子集,利用第一子集训练第一分类器,利用第二子集训练第二分类器;
32、标签预测模块,用于利用训练后的第一分类器为第一组无标签样本生成伪标签,利用训练后的第二分类器为第二组无标签样本生成伪标签;
33、标签辨别模块,用于利用特征融合技术获取无标签样本的伪标签的置信度,从第一组无标签样本中筛选出置信度达到预设阈值的第一候选样本,从第二组无标签样本中筛选出置信度达到预设阈值的第二候选样本;
34、样本更新模块,用于将第一候选样本的伪标签转换为标签,并将带有标签的第一候选样本更新至第二子集,将第二候选样本的伪标签转换为标签,并将带有标签的第二候选样本更新至第一子集;
35、迭代控制模块,用于对第一分类器和第二分类器进行迭代训练。
36、在一个可选的实施方式中,所述基础训练模块包括:
37、样本划分单元,用于将有标签数据集按样本数量平均划分为第一子集和第二子集;
38、第一构建单元,用于构建第一分类器,所述第一分类器包括wideresnet和shake_drop2;
39、第二构建单元,用于构建第二分类器,所述第二分类器包括densenet_cifar和shake_drop2;
40、训练设置单元,用于将第一子集设置为第一分类器的训练集,将第二子集设置为第二分类器的训练集。
41、第三方面,提供一种终端,包括:
42、处理器、存储器,其中,
43、该存储器用于存储计算机程序,
44、该处理器用于从存储器中调用并运行该计算机程序,使得终端执行上述的终端的方法。
45、第四方面,提供了一种计算机存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述各方面所述的方法。
46、本发明的有益效果在于,本发明提供的基于特征融合的半监督学习方法、系统、终端及存储介质,借鉴特征融合的思想,将估计出来的伪标签较为确定的无标签样本转化为有标签样本,从而扩增有标签样本的数量,提升有标签样本的占比,进而大大提升了分类器的训练效率和准确度。
47、此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20240905/287233.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表