一种考虑场景文本位置关系的图文检索方法
- 国知局
- 2024-09-14 14:29:58
本发明属于计算机科学和信息学领域,特别是多模态融合和文本处理技术,具体涉及一种考虑场景文本位置关系的图文检索方法。
背景技术:
1、在多模态领域,图文检索是一项重要的研究任务。图文检索的任务是:给定一段文本,在图片数据库中找到与之相似度最高的图片;或者,给定一张图片,在文本数据库中找到相似度最高的文本。由于零样本式学习有一定的困难,现在大多数的图文检索任务都是基于全监督式学习,即在同一种域的数据上进行训练和测试。本发明也是从全监督式学习出发,探究图片中存在的场景文本之间的位置关系,将场景文本的位置关系作为辅助图文检索的额外信息,来进一步提高图文检索的精度。
2、在现有的含场景文本的图文检索方法中,虽然一些方法利用了场景文本信息,但却没有显式的利用场景文本之间原先就存在的位置关系,这种位置关系对模型进行理解图片中的场景文本和图片中的背景或其他物体之间的关系有十分重要的作用。特别是,当训练数据足够大的时候,为了让模型能从人类的思维出发,总结含场景文本的图片中场景文本之间的规律,需要对场景文本之间的位置关系进行显式的建模。
技术实现思路
1、针对上述含场景文本情况下的图文检索技术中存在的不足,本发明提出一种考虑场景文本位置关系的跨模态检索方法。
2、本发明从显式的角度出发,对场景文本之间的位置关系进行了建模,以适应并且提高含场景文本情况下的图文检索精度。
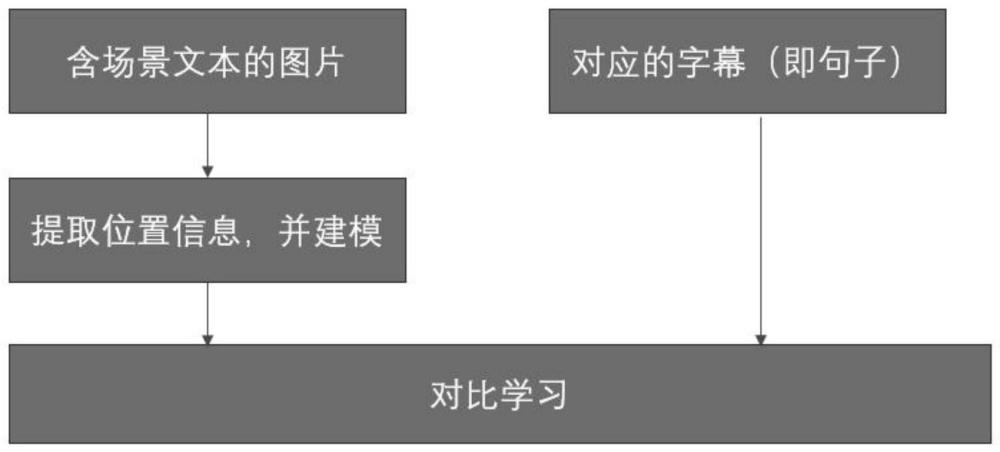
3、因此,针对上述问题,本发明提出了一种考虑场景文本位置关系的图文检索技术,旨在充分利用场景文本之间原先就存在的位置关系来进一步提升在含场景文本情况下的图文检索的精度和效果。本发明利用paddle ocr来对图像中的文字进行检测和识别,得到图片中场景文本的内容和场景文本的位置信息;同时用faster-rcnn来对图片中的显著性物体进行检测和识别,得到图片中显著性物体的视觉表示和显著性物体的位置信息。共同考虑图片中的场景文本和显著性物体组成的集合之间的位置关系,通过对位置关系的挖掘,得到它们的位置关系特征,以让模型显式的对该集合内的位置关系进行学习,利用得到的位置关系以进一步提高图文检索任务的性能。
4、此外,本发明还采用了图网络来对图片中场景文本和显著性物体组成的集合之间的位置信息进行进一步的推理,来习得场景文本和显著性物体之间的位置关系对含场景文本情况下图文检索的好处。
5、本发明主要关注如何利用图片中场景文本和显著性物体之间的位置信息产生的额外联系,来得到更好的图片端的特征,以提高在含场景文本情况下的图文检索的性能与效率。在现今生活中,人们手机中的许多照片都是含有场景文本的,为了解决现有的图文检索模型在含场景文本情况下性能较低的问题,含场景文本情况下的图文检索是一个新兴的研究方向。同时,含场景文本的图文检索也可以用于现在很火的图像生成任务中,通过对场景文本和显著性物体关系之间的建模,可以用于可控图像生成任务。全监督的含场景文本的图文检索一般流程如下:首先,在训练阶段,利用现有的ocr识别工具,如paddle ocr来检测并识别图片中的场景文本,再利用faster-rcnn来对图片中的显著性检测并识别图片中的显著性物体;接着,原先的图片-文本对数据,就变成了图片中的场景文本特征和图片中的显著性物体特征-文本对数据,再对这些特征进行建模;最后,通过输入文本(或者图片对应的特征),模型就能从已有的特征数据库中检索得到匹配度最高的图片对应的特征(或者文本)。这一任务的挑战在于同时考虑图片和文本,以及图片中的场景文本的多样性和复杂性,通常需要使用深度学习和自然语言处理技术来处理这种任务,以实现高效的图文检索。通常地,图文检索利用对比学习将图片端的特征和文本端的特征在公共空间中进行拉近和拉远操作,将正确的图片端的特征和文本端的特征拉近,将不匹配的图片端的特征和文本端的特征拉远。本发明中的图片端的特征由图片的显著性物体特征和图片中的场景文本特征进行融合得到。其中,图片端的场景文本特征从多个角度对场景文本进行特征嵌入(如fasttext语义嵌入、phoc字符级嵌入、视觉特征嵌入等)。
6、一种考虑场景文本位置关系的图文检索方法,包括步骤如下:
7、步骤1,数据准备。收集数据集,采用ctc(coco-text captioned)数据集,此数据集是从coco数据集中选取包含场景文本的图片组成的数据集。它由含场景文本的图片和对应文本组成。
8、步骤2,特征提取。对图片中的显著性物体和场景文本进行特征提取,得到显著性物体的视觉特征和位置信息以及场景文本的内容信息、位置信息和视觉特征,为后续步骤提供必要的基础特征。
9、步骤3,图片端场景文本的特征融合。首先,基于步骤2中得到的场景文本的内容信息,利用fasttext和phoc对场景文本进行语义嵌入和字符级嵌入。接着,将这些嵌入与场景文本的视觉特征进行融合,以获取更丰富和更全面的场景文本表示,最终得到图片端的场景文本特征。
10、步骤4,位置关系建模。通过对图片端的场景文本的位置信息和图片端的显著性物体的位置信息进行显式的建模,得到场景文本和显著性物体构成的总集合中任意两两元素之间的位置关系。接着分别与步骤2得到的显著性物体的视觉特征以及步骤3得到的图片端的场景文本特征进行更新,利用图卷积网络gcn进行上述更新操作,分别得到图片端含位置关系的显著性物体特征和图片端含位置关系的场景文本特征。
11、步骤5,将图片端含位置关系的显著性物体的特征与图片端含位置关系的场景文本特征进行融合,得到图片端的总特征。
12、步骤6,提取文本端的总特征。先将与图片对应的文本进行tokenize化,然后再经过双向长短期记忆网络(bi-lstm),得到文本端的总特征。
13、步骤7,将得到的文本端的总特征与图片端的总特征通过对比学习进行训练,使得正样本对在图片-文本的公共空间中的距离更近,同时,使得负样本对在图片-文本的公共空间中的距离更远。有助于检索到匹配的数据。最后,根据文本总特征和图片总特征之间的相似度,取相似度最高的图片-文本对作为检索的结果。
14、具体的,步骤1包括以下步骤:
15、数据准备。为了利用图片中场景文本和显著性物体的位置信息,我们对ctc(coco-text captioned)数据集的注释进行扩充,从原先的一张图片对应五句描述加上图片中的场景文本的内容,扩展为一张图片对应五句描述加上图片中的场景文本的内容和场景文本的位置信息(场景文本在图片中所处位置的边界框)以及显著性物体的位置信息。
16、具体的,步骤2包括以下步骤:
17、特征提取。对于图片中的显著性物体,使用现有的经过预训练的faster-rcnn进行特征提取,得到显著性物体的视觉特征和位置信息(边界框的中心点、边界框的长和边界框的宽)。对于图片中的场景文本,使用现有的ocr系统(本发明使用的ocr系统是百度的paddle ocr)进行检测和识别,得到场景文本对应的内容信息(如图片中含有的文字“cocacola”)和位置信息(边界框的中心点、边界框的长和边界框的宽);同时,根据场景文本的位置信息使用faster-rcnn进行视觉特征提取,最终得到场景文本的视觉特征这些基础特征将为后续步骤提供必要的支持。
18、具体的,步骤3包括以下步骤:
19、图片端场景文本的特征融合。在使用ocr系统检测并读取到图片中的场景文本之后,根据步骤2,我们已经得到了场景文本的视觉特征为了获取更丰富和更全面的场景文本表示,基于场景文本的内容(如,图片中有的“coca cola”),我们使用fasttext进行语义嵌入,将场景文本的内容(如“coca cola”)嵌入为一个300维的向量同时,使用phoc进行字符级的嵌入,将场景文本的内容嵌入为一个604维的向量最后,将300维的fasttext特征和604维的phoc特征以及场景文本的视觉特征进行融合,得到图片端场景文本更细粒度的特征
20、具体的,步骤4包括以下步骤。
21、位置关系建模。基于步骤2得到的显著性物体和场景文本的位置信息,首先用如下式子对位置信息进行归一化表示:
22、
23、其中,(xi,yi)为边界框中心点坐标,w,h为边界框的宽和高,w,h为图片的宽和高。
24、接着,进行位置关系建模。将图片中的显著性物体的位置信息和图片中的场景文本的位置信息组成的集合称为总集合,对总集合中任意两两元素之间的位置关系进行建模,分为以下几个部分:(1).宽高关系。(2).距离关系。(3).iou关系。(4).角度关系。
25、(1).宽高关系。总集合内两两元素之间的宽高关系用一个六维度的向量表示:
26、
27、其中,hi表示元素i的长、hj表示元素j的长、wi表示元素i的宽、wj表示元素j的宽、δhi,j表示元素i与j长的差值、δwi,j表示元素i与元素j宽的差值。注意:这里的长和宽都是归一化之后的长宽。
28、(2).距离关系。采用两个元素边界框的中心点之间连线的距离来对距离关系di,j进行建模,公式表示如下:
29、
30、(3).iou关系。总集合内两两元素之间的iou关系ioui,j,采用一个三维的向量来表示它们之间的iou关系,如果两个边界框有交集,用如下公式对iou关系进行表示:
31、
32、其中,a为两个边界框的交集区域面积,au为两个边界框的并集区域面积,ai为元素i边界框的区域面积,aj为元素j边界框的区域面积。如果两个边界框没有交集,则两个边界框的交集区域面积a的值为0。
33、(4).角度关系ki,j。总集合内两两元素之间的角度ai,j,用两个元素边界框的中心点之间的连线与水平线之间的夹角来表示,公式表示如下:
34、
35、注意:由于夹角是一个连续的值,为了将连续的值转化为离散的值,将角度的值分为八个区域,以便于学习两两元素之间的角度关系ki,j。这八个区域分别是[0°,45°)、[45°,90°)、[90°,135°)、[135°,180°)、[180°,225°)、[225°,270°)、[270°,315°)、[315°,360°),其对应的离散值即角度关系ki,j分别为1、2、3、4、5、6、7、8。
36、最后,将四个有关位置信息的特征表示进行拼接融合,组成两元素之间的位置关系ri,j,即:
37、
38、对图片中的场景文本和显著性物体都进行以上操作,得到显著性物体和场景文本组成的总集合中任意两两元素之间的位置关系。
39、接着,利用场景文本和显著性物体构成的总集合中任意两两元素之间的位置关系ri,j来对步骤2得到的显著性物体的视觉特征以及步骤3得到的融合后的图片端的场景文本特征进行更新,具体利用图卷积网络gcn的特性,将显著性物体的视觉特征和融合后的图片端的场景文本特征作为顶点,将它们的位置关系作为两个顶点之间的边,以对特征进行迭代更新。最后,得到更新后的包含位置关系的显著性物体特征xobj和更新后的包含位置关系的场景文本特征xocr。
40、具体的,步骤5包括以下步骤。
41、经过步骤4后,尽管图网络中由总集合构成的顶点数量不变,但是经过更新后,集合中的顶点融入了任意元素间的位置关系,为了得到图片端的总特征,将所有顶点的特征进行汇总,采用平均加权的方法,对包含位置关系的显著性物体特征xobj和包含位置关系的场景文本特征xocr进行融合,得到图片端的总特征。
42、具体的,步骤6包括以下步骤。
43、对于文本端的总特征。使用tokenizer来对图片对应的文本进行tokenize化,然后将tokenize后的单词输入到一个双向长短期记忆网络(bi-lstm),bi-lstm从前向和后向考虑词之间的关系,输出每个位置对应的的隐藏层状态,将最后一个时间步的隐藏层状态作为整个文本端的总特征。
44、本发明有益效果如下:
45、(1)提高图文检索的精度:精确的文本-图片匹配,通过考虑场景文本的位置关系,本发明可以更精确地将文本与对应的图片匹配。这意味着用户可以获得与其查询最相关的图像,从而提高了检索结果的质量。减少误报,传统的图文检索可能会产生误报,即返回与查询文本不相关的图像。通过考虑位置关系,误报的可能性降低,因为系统更能理解文本在图像中的实际位置和上下文。
46、(2)改进多模态信息融合:综合性能,本发明将场景文本和显著性物体的信息有效地融合在一起,产生更丰富、更有信息量的特征表示。这有助于模型更好地理解图像和文本之间的关系,从而提高了图文检索的性能。深度理解场景:通过考虑位置关系,系统能够深入理解场景文本与显著性物体之间的联系。这有助于系统更好地捕捉图像的含义,而不仅仅是简单地匹配关键词。
47、(3)适用于含场景文本的任务:广泛应用领域,本发明在图文检索领域尤其有用,因为它专门关注处理含有场景文本的情况。然而,它不仅仅适用于图文检索,还可以在其他应用领域发挥作用,如图像生成、自动标注等需要多模态信息处理的任务。处理真实场景,由于越来越多的图片包含场景文本,本发明有助于处理现实世界中的图像数据,使其适用于实际应用。
48、综上所述,通过考虑场景文本的位置关系,本发明提供了一种改进的方法,可以提高图文检索的准确性,改善多模态信息融合,并在处理含场景文本的任务中表现出色。这对于多种应用领域都具有重要意义,包括图像检索和图像生成。
本文地址:https://www.jishuxx.com/zhuanli/20240914/294400.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表