基于预测轨迹的安全强化学习智能车汇入决策方法及系统
- 国知局
- 2024-11-18 18:16:50
本申请涉及自动驾驶行为决策,具体涉及一种基于预测轨迹的安全强化学习智能车汇入决策方法及系统。
背景技术:
1、决策层作为自动驾驶的关键核心部分,承接感知预测层,根据当前环境交通态势做出包括换道与加减速在内的高级行为决策,对自动驾驶车辆的安全性与交通效率起着重要作用。然而,在复杂的人类驾驶与自动驾驶车辆混行的交通场景下,尤其是合流区的匝道汇入,自动驾驶的安全决策仍面临着挑战。
2、在城市道路中,合流区汇入是最常见的驾驶任务之一。目前应用于合流区匝道汇入的决策方法主要分为基于规则的方法和基于学习的方法两类。其中,基于规则的决策方法预先设定规则,能够应对常见和简单的交通场景,具有简单高效的优点。然而,基于规则的方法往往需要足够的先验知识,且现实的交通环境是复杂多变的,设定好的规则难以应对复杂交通场景,从而无法做出安全而高效的决策。而基于学习的决策方法则通过不断训练,采用数据驱动的方法使得决策模型能够应对更多的情况,且能在不同交通态势下做出对应的最优决策。基于深度强化学习的决策方法通过对环境的探索,接受环境的反馈奖励,从而不断优化决策模型,这使得强化学习决策模型对环境具有更好的泛用性,在面对复杂交通场景时被认为有着巨大的潜力。
3、然而强化学习需要训练才能得到最优决策模型,而训练收敛前的过程中智能体做出的决策往往安全性较差,同时训练的周期长,成本高,这使得基于强化学习的自动驾驶决策方法难以投入实际应用。安全强化学习是一种提高训练过程安全性,减少训练成本的有效手段,但现有安全强化学习往往只聚焦于当前的交通态势,而未能考虑到交通态势的变化。
技术实现思路
1、本申请提供了一种基于预测轨迹的安全强化学习智能车汇入决策方法,以解决现有技术中,强化学习需要训练才能得到最优决策模型,而训练收敛前的过程中智能体做出的决策往往安全性较差,同时训练的周期长,成本高,使得基于强化学习的自动驾驶决策方法难以投入实际应用的问题。
2、相应的,本申请还提供了一种基于预测轨迹的安全强化学习智能车汇入决策系统、一种电子设备、一种计算机可读存储介质,用于保证上述方法的实现及应用。
3、为了解决上述技术问题,本申请公开了一种基于预测轨迹的安全强化学习智能车汇入决策方法,所述方法包括:
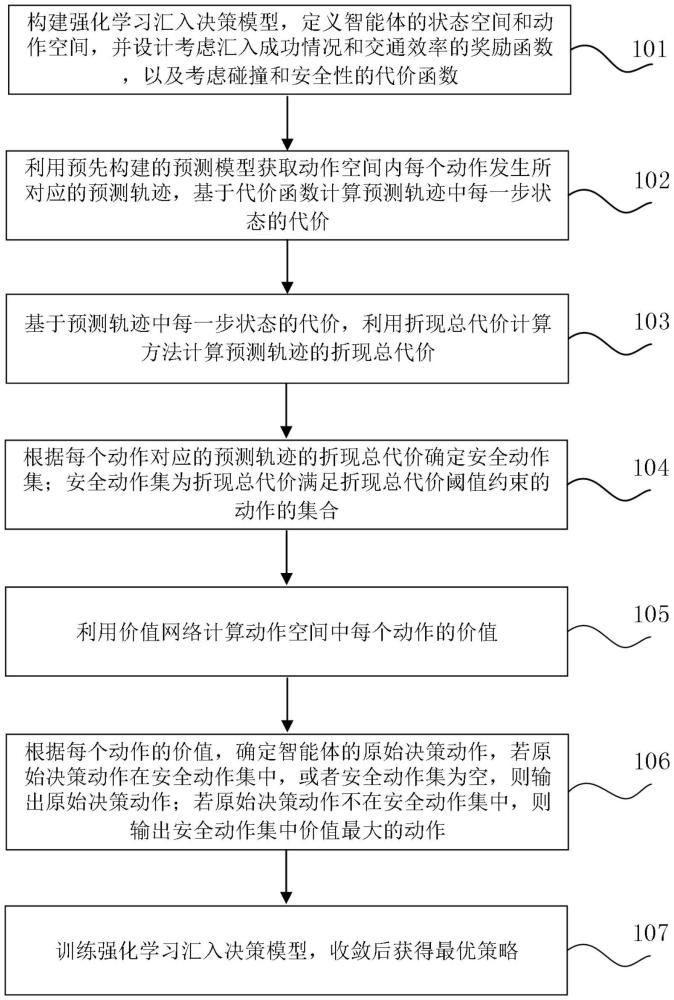
4、构建强化学习汇入决策模型,定义智能体的状态空间和动作空间,并设计考虑汇入成功情况和交通效率的奖励函数,以及考虑碰撞和安全性的代价函数;
5、利用预先构建的预测模型获取动作空间内每个动作发生所对应的预测轨迹,基于代价函数计算预测轨迹中每一步状态的代价;
6、基于预测轨迹中每一步状态的代价,利用折现总代价计算方法计算预测轨迹的折现总代价;
7、根据每个动作对应的预测轨迹的折现总代价确定安全动作集;安全动作集为折现总代价满足折现总代价阈值约束的动作的集合;
8、利用价值网络计算动作空间中每个动作的价值;
9、根据每个动作的价值,确定智能体的原始决策动作,若原始决策动作在安全动作集中,或者安全动作集为空,则输出原始决策动作;若原始决策动作不在安全动作集中,则输出安全动作集中价值最大的动作;
10、训练强化学习汇入决策模型,收敛后获得最优策略。
11、本申请还公开了一种基于预测轨迹的安全强化学习智能车汇入决策系统,所述系统包括:
12、模型构建模块,用于构建强化学习汇入决策模型,定义智能体的状态空间和动作空间,并设计考虑汇入成功情况和交通效率的奖励函数,以及考虑碰撞和安全性的代价函数;
13、代价计算模块,用于利用预先构建的预测模型获取动作空间内每个动作发生所对应的预测轨迹,基于代价函数计算预测轨迹中每一步状态的代价;
14、代价计算模块,还用于基于预测轨迹中每一步状态的代价,利用折现总代价计算方法计算预测轨迹的折现总代价;
15、安全动作约束模块,用于根据每个动作对应的预测轨迹的折现总代价确定安全动作集;安全动作集为折现总代价满足折现总代价阈值约束的动作的集合;
16、价值评估模块,用于利用价值网络计算动作空间中每个动作的价值;
17、安全动作输出模块,用于根据每个动作的价值,确定智能体的原始决策动作,若原始决策动作在安全动作集中,或者安全动作集为空,则输出原始决策动作;若原始决策动作不在安全动作集中,则输出安全动作集中价值最大的动作;
18、模型训练模块,用于训练强化学习汇入决策模型,收敛后获得最优策略。
19、本申请还公开了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现本申请中一个或多个所述的方法。
20、本申请还公开了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现如本申请中一个或多个所述的方法。
21、本申请中,构建强化学习汇入决策模型,定义智能体的状态空间和动作空间,并设计考虑汇入成功情况和交通效率的奖励函数,以及考虑碰撞和安全性的代价函数。利用预测模型获取动作空间内每个动作发生所对应的预测轨迹,基于代价函数计算预测轨迹中每一步状态的代价,基于预测轨迹中每一步状态的代价,利用折现总代价计算方法计算预测轨迹的折现总代价,然后根据每个动作对应的预测轨迹的折现总代价确定安全动作集。根据智能体的原始决策动作是否在安全动作集中,若在安全动作集中,或者安全动作集为空,则输出原始决策动作;若不在安全动作集中,则输出安全动作集中价值最大的动作。本申请中,将预测轨迹融入安全强化学习,通过将不安全动作替换为安全动作,有效地减少了训练过程中的碰撞次数,从而缩短了训练周期,降低了训练成本,提高了汇入决策的安全性。
22、除此之外,本申请中决策考虑了轨迹预测,实现了预测层与决策层的结合,使得决策考虑了未来交通态势的演化,在自动驾驶安全决策中有着巨大潜力。并且,本申请考虑了预测轨迹的不安全因素。
23、本申请附加的方面和优点将在下面的描述部分中给出,这些将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:1.一种基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述构建强化学习汇入决策模型,定义智能体的状态空间和动作空间,并设计考虑汇入成功情况和交通效率的奖励函数,以及考虑碰撞和安全性的代价函数之前,所述方法还包括:
3.根据权利要求2所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述利用预先构建的预测模型获取所述动作空间内每个动作发生所对应的预测轨迹,并基于所述代价函数计算所述预测轨迹中每一步状态的代价,包括:
4.根据权利要求1或3所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述代价函数为:
5.根据权利要求1所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述奖励函数为:
6.根据权利要求1所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述折现总代价计算方法为:
7.根据权利要求1所述的基于预测轨迹的安全强化学习智能车汇入决策方法,其特征在于,所述训练强化学习汇入决策模型,收敛后获得最优策略,包括:
8.一种基于预测轨迹的安全强化学习智能车汇入决策系统,其特征在于,所述系统包括:
9.一种电子设备,其特征在于,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现权利要求1-7中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1-7中任一项所述的方法。
技术总结本申请涉及自动驾驶行为决策技术领域,公开了一种基于预测轨迹的安全强化学习智能车汇入决策方法及系统。构建强化学习汇入决策模型,利用预测模型获取每个动作对应的预测轨迹,基于代价函数计算预测轨迹中每一步状态的代价,利用折现总代价计算方法计算预测轨迹的折现总代价。然后根据每个动作的折现总代价确定安全动作集。若智能体的原始决策动作在安全动作集中,或者安全动作集为空,则输出原始决策动作;若不在安全动作集中,则输出安全动作集中价值最大的动作。本申请中,将预测轨迹融入安全强化学习,通过将不安全动作替换为安全动作,有效地减少了训练过程中的碰撞次数,从而缩短了训练周期,降低了训练成本,提高了汇入决策的安全性。技术研发人员:金立生,付浩岩,谢宪毅,周和平,刘艺昕,魏青嵩,周心晴受保护的技术使用者:燕山大学技术研发日:技术公布日:2024/11/14本文地址:https://www.jishuxx.com/zhuanli/20241118/327995.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。