一种基于改进DDPG算法的车辆跟驰行为决策方法
- 国知局
- 2024-11-19 09:53:14
本发明涉及车辆行为决策的,特别是涉及一种基于改进ddpg算法的车辆跟驰行为决策方法。
背景技术:
1、随着车联网、车路协同、人工智能等学科技术等高速发展,如今的车辆驾驶正逐渐往智能化、高效化、安全化发展。作为智能化驾驶的一大分支,跟车已经成为日常驾驶中的最常见的驾驶行为。跟车的主要目标是驾驶员将自身车速调整到与慢车车速一致,并将车距保持在期望值内。
2、近年来,深度强化学习(deep reinforcement learning,drl)在自动驾驶领域展现出了巨大的潜力,如公告号为cn112904864b的发明专利中公开的基于深度强化学习的自动驾驶方法和系统和公告号为cn116052412b的发明专利中公开的融合物理信息和深度强化学习的自动驾驶车辆控制方法等,均可实现车辆的自动驾驶。
3、而深度确定性策略梯度(deep deterministic policy gradient,ddpg)算法作为一种先进的深度强化学习算法,结合了深度学习和强化学习的优势,能够在连续动作空间中高效学习和决策。因此,ddpg算法在自动驾驶中的应用研究逐渐增多,基于传统ddpg算法的车辆跟驰行为决策方法在实际应用中,一方面传统ddpg算法在训练过程中,容易受到噪声和随机性因素的影响,导致训练过程不稳定,容易陷入局部最优解,这会使得车辆在复杂交通环境中无法做出最优决策,影响决策精度;另一方面在高维状态空间的处理能力不足,车辆跟驰行为涉及大量的环境感知信息和决策变量,传统ddpg算法难以在短时间内有效处理和学习这些信息,导致决策延迟下降。由此,现有的基于传统ddpg算法的车辆跟驰行为决策方法的决策效率和精度均不高,存在较大的提升空间,因此亟需一种决策效率和精度均较高的基于改进ddpg算法的车辆跟驰行为决策方法对上述问题进行改善。
技术实现思路
1、为解决上述技术问题,本发明提供一种通过双重经验回放池帮助存储和重用历史经验数据,引入两个独立回放池和进行延迟的间隔随机采样进行数据获取拟提高决策的效率,奖励函数综合考虑了三方面,安全性、效率性和舒适性,使得智能体能考虑到当前时间步的综合表现,从而达到精度较高的车辆跟驰行为决策的一种基于改进ddpg算法的车辆跟驰行为决策方法。
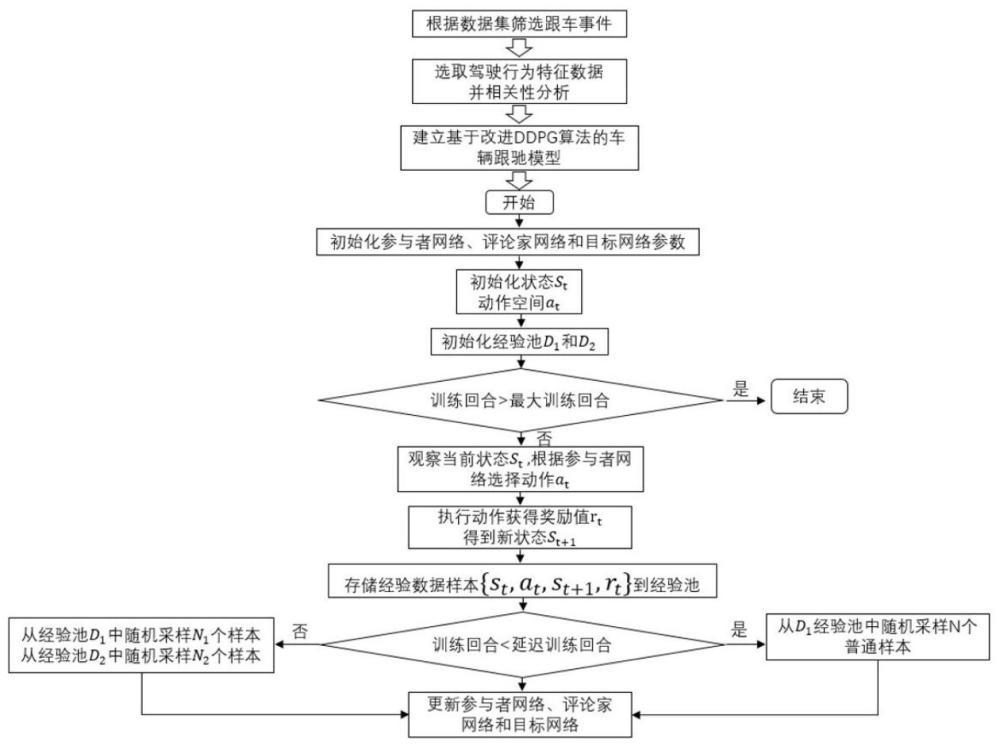
2、本发明的一种基于改进ddpg算法的车辆跟驰行为决策方法,包括以下步骤:
3、s1、根据原始自然数据集,筛选出符合条件的跟车事件数据,筛选出的跟车事件,默认考虑的是前车的跟驰,不直接考虑后面的车辆,因为当驾驶员在高速公路行驶过程中,通常驾驶员认为位于他们后面的车辆的驾驶行为是合理的,即默认后车不会估计追尾前车。最后将筛选出来的跟车事件,70%用于训练数据集,30%作为测试数据集;
4、s2、选取数据集中合适的驾驶行为数据特征,具体选取的特征数据有fv_vel、fv_acc、space_headwauy、v_rel、lv_vel和lv_acc与thw和ttci,分别表示跟随车辆的速度、加速度、跟随车辆与领先车辆的相对距离、相对速度、领先车辆的速度和加速度;
5、s3、明确数据集中驾驶行为特征参数之间的相关性,针对数据集中选取的数据特征,进行皮尔逊相关性分析;
6、s4、建立基于改进ddpg算法的车辆跟驰模型,设置车辆跟驰场景下的强化学习环境,包括状态空间、动作空间和奖励函数;
7、s5、设置状态空间,选取纵向车辆的速度vfv、相对速度和纵向轨迹上的位置变化来反映行驶轨迹,根据跟随车辆的速度和加速度来迭代更新纵向的速度和纵向位置,不断重复此步骤,ddpg代理能够通过控制跟随车辆的速度来控制车辆行驶的轨迹,利用ddpg算法得到车辆跟驰过程中的加速度值,状态的更新状态通过经典运动点学模型来计算,所述经典运动点学模型是用于描述车辆运动的物理模型,在车辆纵向运动过程中,用于计算车辆的速度、相对速度和位置随时间的变化;
8、s6、设置动作空间:动作空间输出的为车辆的加速度值,然后根据运动点方程迭代生成未来的速度、相对速度和相对距离;
9、s7、奖励函数r综合考虑三方面因素,用于评价车辆的行为并根据这些行为提供反馈,促使模型朝着期望的方向发展,主要考虑的因素是安全性、效率性、舒适性;
10、s8、初始化参与者网络参数θμ和评论家网络参数θq,初始化参与者目标网络θμ′和评论家目标网络θq′,初始化经验池d1和经验池d2,其中参与者网络负责的是网络参数的迭代更新,负责根据当前状态st选择当前动作at,该动作用于与环境进行交互,目标参与者网络负责根据经验回放池中采样的下一个状态st+1)选择出最佳的下一个动作at+1,评论家网络负责价值网络参数的迭代更新,负责计算当前的动作价值q(st,at),评论家目标网络负责计算目标的动作价值的q(st+1,at+1)部分;
11、s9、开始训练,观察当前状态st,根据策略网络选择动作at,执行动作at获取奖励rt并观察新的状态st+1;
12、s10、根据奖励值的反馈情况将{st,at,st+1,rt}的四元组经验数据分为正样本和负样本,并分别存储到两个经验回放池中,其中正样本为完成跟驰任务的样本、既没有完成跟驰任务又没有发生碰撞的样本,负样本为发生碰撞的样本;
13、s11、从经验池中采样,先从正样本经验池d1中采样,在延迟固定的间隔后再按比例从d1经验池和d2经验池中随机采样,随后进行网络的更新
14、s12、使用评论家目标网络计算目标的q值:
15、yt′=rt′+γq(st′,at′|θq)
16、其中,yt′表示目标q值,用于更新评论家网络,rt′在时间步ti获得的即时奖励,γ表示折扣因子,并且γ介于0和1之间,表示未来奖励的重要性,q(st′,at′|θq)表示评论家执行网络在参数θq下基于状态st′和动作at′,计算得到的q值;
17、s13、通过最小化损失函数来更新评论家网络的参数θq,损失函数l采用了均方误差的形式,即实际q值和目标q值之间差异的平方和,然后取平均值:
18、
19、其中,l为损失函数的值;n为批量大小,即在每次参数更新时使用的样本数量,yi表示第i个样本的目标q值,目标q值通过步骤s12得到,q(si-aiθq)表示q网络对第i个样本的状态si和动作ai的预测q值;
20、s14、使用策略梯度更新参与者网络的参数θμ;
21、s15、基于更新后的评论家网络的参数来更新评论家目标网络的参数,基于更新后的参与者网络的参数来更新参与者目标网络的参数;按照软更新方式进行更新:
22、
23、其中,←表示赋值,v为预设的超参数,介于0和1之间的一个小值,用于控制目标网络参数更新的速度,θμ为参与者网络参数,θμ′为参与者目标网络参数,θq为评论家网络参数,θq′为评论家目标网络参数;
24、s16、当策略收敛或达到预设的训练轮数时,终止训练过程。
25、优选的,筛选出跟车事件的规则包括:
26、s1.1、为方便跟车事件的分析,选取数据集中的车辆类型为小轿车,排除摩托车和大型车;
27、s1.2、雷达识别出的车辆编号保持不变,表示跟驰事件的前后车都是唯一不变的一组车;
28、s1.3、跟驰的车辆都在同一车道上;
29、s1.4、跟车的持续时间需要>15s并且是一段连续的,保证跟驰时间有足够的数据进行分析。
30、优选的,所述thw和ttci的表示方式为:
31、thw(t)=dfv,lv(t)/vfv(t)
32、ttci(t)=δvrel(t)/dfv,lv(t)
33、其中,thw表示的是从fv车辆的前中心移动到前面车辆lv的前中心的时间,dfv,lv(t)时间t中跟随车辆fv与前车lv之间的距离,vfv(t)表示在时间t跟随车辆的速度;
34、ttc指的是跟驰过程中两车相撞所需要的时间,也被称之为最小碰撞时间,保证了车辆在危险制动下的最小距离,当辆车相对速度为0时,ttc将会无解,所以采用ttc的变形为ttci,即取ttc的倒数,δvrel(t)表示在时间t跟随车辆与前车之间的相对速度,dfv,lv(t)表示在时间t跟随车辆与前车之间的距离。
35、优选的,所述皮尔逊相关性分析计算公式:
36、
37、其中,ρ(x,y)为皮尔逊相关系数,表示变量x和y之间的线性相关程度,cov(x,y)表示变量x和y之间的协方差,σ(x)为变量x的标准差,σ(y)为变量y的标准差,e[(x-μx)(y-μy)]为变量x和y的协方差计算公式,e表示期望值,μx为变量x的均值,μy为变量y的均值,其中相关系数ρ(x,y)取值范围为[-1,1],正负值分别表示两个变量之间存在着正、负相关,当两个变量之间的相关系数绝对值大于0.8时,两个变量极度相关,相关系数绝对值小于0.4时,两个变量相关性较弱。
38、优选的,所述奖励函数r,计算公式为:
39、rtotal=w1r1+w2r2+w3r3+w4r4+w5r5
40、其中,r1表示为安全性的奖励函数,采用最小碰撞时间的倒数ttci来衡量,确保车辆行驶在一个特定的阈值内,安全性奖励函数通过考虑车辆的最小碰撞时间,并采用对数函数形式来定义奖励值,鼓励车辆在跟驰过程中保持安全的距离,避免碰撞风险,其设计使得当车辆接近或低于安全时距阈值时,智能体会受到惩罚,而在安全距离之外时,奖励值为零,保持了奖励函数的平滑性和合理性;
41、所述安全性奖励函数为:
42、
43、ttci表示当前最小碰撞时间的倒数值,ttci*表示安全阈值,即在该阈值下认为当前车距是安全的,如果当前时距小于这个阈值,则认为存在碰撞风险,α表示权重参数;
44、r2表示为效率性的奖励函数,根据跟驰场景中的车头时距thw来衡量,效率性奖励函数通过考虑车头时距thw并结合核密度估计,使智能体能够在车辆跟驰过程中保持高效和安全的跟车距离,函数在车头时距较小时给予较高的奖励,而在车头时距过大时逐渐减少奖励值,确保智能体能够在各种情况下做出最优决策;
45、所述效率性奖励函数为:
46、
47、thw(t)表示当前车头时距,即当前车辆与前车之间的时间间隔,threshold*是阈值,当车头时距大于这个阈值时,效率性奖励将受到惩罚,β是调整参数,用于控制奖励值衰减的速度,fkde是基于核密度估计计算的thw分布函数值,k为核函数,用于核密度估计,h为带宽参数,用于控制核密度估计的平滑程度,x为当前的thw值,xi为独立分布的采样点,n是数据量;
48、r3表示为舒适性的奖励函数,舒适性奖励函数通过考虑车辆的jerk,并结合基准值jvalue,鼓励智能体在车辆跟驰过程中保持平稳的驾驶行为,从而提高乘客的舒适性,函数在jerk较大时给予负奖励,推动智能体优化其控制策略以减少加速度变化,从而提高驾驶的舒适度;
49、所述舒适性函数为:
50、
51、jerk表示车辆的加加速度,即加速度的变化率,定义为jvalue表示为基准值,定义为一段时间内加速度变化的平方和,amax表示在一段时间δt内车辆的最大加速度,amin表示再一段时间δt内车辆的最小加速度。
52、优选的,所述r4和r5用于车辆跟驰行为决策中的碰撞和提早停车情景,分别定义发生碰撞和提早停车时的惩罚值情况;
53、r4是通过对发生碰撞时的相对速度差进行惩罚,鼓励智能体在车辆跟驰过程中避免发生碰撞,由于碰撞是不希望发生的事件,通常这个函数的值是负的,通过对数函数,可以平滑地增加惩罚值,使其与相对速度差成对数关系;
54、r5是通过对提早停车时的相对距离差进行惩罚,鼓励智能体在跟驰过程中避免发生早停,这个函数通常用于鼓励车辆保持距离进行跟驰,为了防止车辆频繁的提早停车,因此其值通常是负的,以避免不合理的早停行为;
55、公式为:
56、
57、δ和η表示权重参数,用于调整奖励值的大小,表示前后车之间的相对速度,iscollision是一个布尔变量,当发生碰撞时为true,表示前后车之间的相对距离,isstop是一个布尔变量,当车辆早停时为true。
58、优选的,所述s14中,使用策略梯度更新参与者网络的参数θμ:
59、
60、其中,表示策略的梯度,表示希望最大化的目标函数j对策略参数θμ的梯度,通过最大化期望奖励j,可以优化策略网络参数θμ,表示对批量样本中的n个样本进行平均,q(s,aθq)表示评论家网络用于估计在状态s下执行动作a所得到的未来累计奖励,参数为θq,μ(s;θμ)表示参与者网络在给定状态s输出动作a,参数为θμ,si为第i个样本的状态,μ(si)表示策略网络在状态si下输出的动作,a=μ(si)表示q函数q(s,aθq)对动作a的梯度,评估在状态si处使用策略μ计算出动作μ(si)的q值梯度,表示策略函数μ(s;θμ)对策略参数θμ的梯度,评估在状态si下策略网络输出的动作μ(si)对参数θμ的梯度。
61、优选的,所述参与者网络和评论家网络均由输入层、隐藏层和输出层组成,并且参与者网络和评论家网络的隐藏层均为30个神经元,参与者网络的输入层有三个输入,分别为纵向车辆的速度vfv、相对速度δvt和纵向轨迹上的相对位置δdt,输出层为加速度a值,这也会作为评论家网络的输入,因此评论家网络有4个输入,输出层为q值。
62、与现有技术相比本发明的有益效果为:本发明是提供一种决策效率和精度均较高的基于改进ddpg算法的车辆跟驰行为决策方法,双重经验回放池可以帮助存储和重用历史经验数据,引入两个独立回放池和进行延迟的间隔随机采样进行数据获取拟提高决策的效率,奖励函数综合考虑了三方面,安全性、效率性和舒适性,这使得智能体能考虑到当前时间步的综合表现,从而达到精度较高的车辆跟驰行为决策,这对未来自动驾驶系统的发展提供了新的研究方向和技术支持。
本文地址:https://www.jishuxx.com/zhuanli/20241118/330504.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
电池箱托架总成的制作方法
下一篇
返回列表