基于强化学习的自动驾驶汽车改进PID横向跟踪控制方法
- 国知局
- 2024-08-02 16:56:13
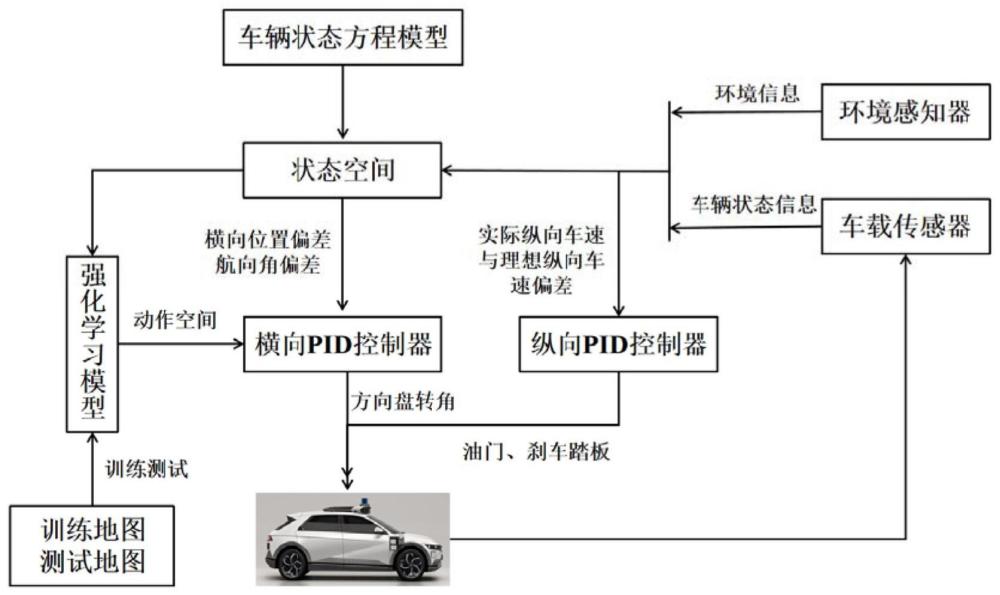
本发明涉及自动驾驶汽车运动控制领域,尤其是涉及一种自动驾驶汽车横向跟踪控制方法。
背景技术:
1、自动驾驶技术作为现代信息技术的新兴产物,被认为具有显著的潜力,可有效提升道路交通安全、减少城市道路交通拥堵,并为现有社会道路交通体系带来巨大改变。车辆轨迹跟踪控制作为车辆运动控制的核心组成部分,其主要任务是确保自动驾驶汽车按照预设路径行驶。因此,稳定准确的轨迹跟踪控制被视为实现自动驾驶汽车底层目标的关键。
2、目前,常用的自动驾驶汽车横向运动控制算法主要分为无模型控制算法和有模型控制算法。无模型控制算法主要采用pid控制算法,而有模型控制算法则包括lqr控制、纯跟踪控制、前馈控制、模型预测控制等。然而,自动驾驶汽车的行驶条件复杂多变,实际车辆动力学模型存在高度不确定性,且易受外部干扰影响。因此,基于模型的横向控制算法的有效性严重依赖于模型精度。pid控制算法虽然是无模型控制算法,但其具有快速收敛、良好稳定性和简单实现等优点,在控制系统中被广泛应用。然而,由于pid控制未考虑车辆自身特性,其对外部干扰的鲁棒性较差,因此在高速行驶、道路曲率较大等工况下应用受到限制。因此,传统的控制策略已经无法完全满足自动驾驶汽车轨迹跟踪控制的要求。
3、强化学习是一种不基于模型的交互式学习算法,其核心特征是通过与环境的在线交互,利用试错机制来最大化未来回报,从而实现序列学习。由于其交互式特性,强化学习能够有效地通过环境反馈信息学习系统控制策略,因此被广泛认为是实现智能决策和控制的有效手段,可以使系统具备持续自学习的能力,从而增强系统性能。然而,强化学习需要大量的训练时间来找到最优策略,尤其在复杂环境中,训练时间可能会很长。同时,在训练过程中可能会陷入局部最优解,并且需要大量样本数据。
4、综合考虑pid控制策略和基于强化学习算法的控制策略的不足,采用两者结合的方式可以充分发挥它们各自的优势。pid控制算法的先验知识大大减少了强化学习的探索空间,可以有效避免训练过程中陷入局部最优解,从而解决训练不稳定的问题。同时,强化学习机制可以实时更新pid控制参数,实现自适应pid控制,解决了定参数pid控制在面对复杂环境时鲁棒性较差的问题。因此,研究基于强化学习的改进pid控制具有重要的实践意义。
技术实现思路
1、针对现有技术存在的问题,本发明提出了一种基于强化学习的自动驾驶汽车改进pid横向跟踪控制方法。该方法将强化学习与pid控制相结合,有效解决了强化学习训练不稳定、容易陷入局部最优解以及pid控制无法适用于车辆高速行驶、道路曲率较大工况的问题。
2、为实现本发明的目标,提出以下技术方案:
3、s1、通过分析车辆特性和横纵解耦需求,基于横纵解耦控制策略分别建立纵向pid控制方法和横向pid控制方法;
4、s2、建立车辆动力学方程,获取基于横向位置误差和航向角误差的车辆状态方程;
5、s3、利用车辆状态信息和车辆状态方程建立强化学习的状态空间和动作空间,基于状态空间和动作空间构建actor-critic网络;
6、s4、设置奖励函数,利用深度确定性策略梯度算法对actor网络进行更新,实时更新横向pid控制参数;
7、s5、整定横纵向pid控制器参数,使用训练地图进行actor-critic网络的强化学习训练,使模型达到预定的跟踪控制效果。
8、所述的步骤s1中,通过分析车辆特性和横纵解耦需求,基于横纵解耦控制策略分别建立纵向pid控制方法和横向pid控制方法;具体过程为:
9、步骤s1.1:分析车辆解耦控制需求;
10、步骤s1.2:建立纵向pid控制方法;
11、步骤s1.3:建立横向pid控制方法;
12、所述的步骤s1.1中,车辆解耦需求分析如下:
13、在速度不太高的行驶工况下,常规车辆的转向结构往往限定在30度角以内,行车路径的曲率有限,转向轮横向力在车身纵轴的分量很小,纵向控制基本不受横向状态影响,可独立进行,这意味着横向控制的变化不会直接影响纵向控制。此外,横向和纵向运动往往受到不同的外部因素和驾驶需求的影响,车辆在转弯时需要进行横向控制以跟踪道路弯曲,而在直线行驶时需要进行纵向控制以保持稳定的速度,将横向和纵向控制分开处理有助于简化控制系统的设计和实现。通过解耦,可以更轻松地设计和调整每个控制器,而不会过度依赖其他控制器。通过独立处理横向和纵向运动,可以更好地适应不同的驾驶情况和路况变化,从而提高车辆的整体性能和安全性。
14、所述的步骤s1.2中,建立纵向pid控制方法如下:
15、纵向控制主要调节车辆的纵向车速,通过调整加速和制动来实现。设定直道和弯道的目标纵向车速,旨在模仿驾驶员在遇到弯道时进行制动踏板减速的驾驶习惯,以确保行车安全。
16、通过计算预设路径点的曲率得到道路曲率,其中弯道目标纵向车速vxwref与直道目标纵向车速vxzref的关系如下式:
17、vxwref=vxzref-kref*χ
18、其中,kref是期望路径曲率,χ为相关系数。
19、由于积分项的存在可能导致系统对扰动过度敏感,增加系统的振荡或者超调,为了避免这种情况,只使用pd控制器可以更好地控制系统的动态响应,此时的pd控制率为:
20、
21、δvx(t)=vx(t)-vxref(t)
22、其中,u(t)为当前时刻t的纵向加速度,kp0、kd0分别为纵向pid控制器的比例、微分系数,δvx(t)为当前时刻t实际纵向车速与目标纵向车速误差,vxref(t)为当前时刻t的目标纵向车速,vx(t)为当前时刻t的实际纵向车速。
23、pid控制的输入为纵向车速与当前纵向车速的速度差,输出为纵向加速度,以此来实现纵向车速的跟随。
24、所述的步骤s1.3中,建立横向pid控制方法如下:
25、横向控制是指在车辆运动方向上垂直的转向控制,其目标是使汽车保持预设的行车路线,主要通过控制方向盘转角来实现。横向控制以横向位置误差和航向角误差作为输入参数,输出方向盘转角作用于被控车辆。忽略积分项的影响,pd控制率为:
26、
27、kp1(t)、kd1(t)分别为当前时刻t横向位置误差pid控制器的比例、微分系数,kp2(t)、kd2(t)分别为当前时刻t航向角误差pid控制器的比例、微分系数,err(t)是当前时刻t相对车道中心线的横向位置误差,是当前时刻t相对车道中心线的横向位置误差变化率,是当前时刻t相对车道的车辆航向角误差,是当前时刻t相对车道的车辆航向角误差变化率。
28、所述的步骤s2中,建立车辆动力学方程,获取基于横向位置误差和航向角误差的车辆状态方程,具体过程为:
29、步骤s2.1:构建二自由度车辆动力学模型;
30、步骤s2.2:获取基于横向位置误差和航向角误差的车辆状态方程模型;
31、所述的步骤s2.1中,二自由度车辆动力学模型构建过程如下:
32、忽略x轴的受力情况,假设前轮转角δ很小,则有y轴和z轴的动力学方程:
33、may=2fyf+2fyr
34、
35、其中,m为车辆的整车质量,ay为车辆的y轴方向加速度,fyf、fyr分别为车辆前后轮受到的y方向的力,iz为车辆绕z轴转动的转动惯量,为车身航向角,a、b分别为车辆的前悬长度和后悬长度。
36、
37、fyf=cafαf,fyr=-carαr
38、
39、
40、其中,y为车身坐标系下的质心横向位置,αf、αr分别为前轮侧偏角与后轮侧偏角,caf、car分别为前后轮的侧偏刚度,vx、vy分别为车辆的纵向车速和横向车速,δ为前轮转角。
41、二自由度车辆动力学模型为:
42、
43、所述的步骤s2.2中,基于横向位置误差和航向角误差的车辆状态方程模型如下:
44、
45、
46、
47、
48、
49、
50、
51、
52、其中,为道路期望航向,为道路期望航向变化率,r为转弯半径,vxref是x方向期望速度,kref是期望路径曲率,dx为全局坐标系下车辆质心到轨迹上最近点的x方向距离,dy为全局坐标系下车辆质心到轨迹上最近点的x方向距离,y为全局坐标系下的y轴位置,err是横向位置误差,是相对车道的航向角误差。
53、基于横向位置误差和航向角误差的车辆状态方程模型:
54、
55、其中,vxref是x方向期望速度。
56、所述的步骤s3中,利用车辆状态信息和车辆状态方程建立强化学习的状态空间和动作空间,基于状态空间和动作空间构建actor-critic网络,具体过程如下:
57、步骤s3.1:建立强化学习的状态空间;
58、步骤s3.2:建立强化学习的动作空间;
59、步骤s3.3:建立actor-critic网络;
60、所述的步骤s3.1中,建立强化学习的状态空间如下:
61、横向控制器的目的是使得车辆横向位置误差最小和航向角误差最小,针对横向控制器的控制任务,考虑到车辆参数的特性,选择横向位置误差err、横向位置误差变化率车辆航向角误差车辆航向角误差变化率四个状态参数组成车辆状态空间。
62、所述的步骤s3.2中,建立强化学习的动作空间如下:
63、pid控制率为:
64、
65、为了使系统自动适应环境和参数的变化,设计了基于强化学习的改进pid横向轨迹跟踪控制器,控制参数可以根据实时性能要求进行在线调整,此时的横向pid控制率为:
66、
67、通过调节控制参数,实现轨迹跟踪控制过程中的动态补偿,因此动作空间选择四个控制参数的变化量δkp1、δkp2、δkd1、δkd2,最终控制量为输出的方向盘转角控制序列。
68、所述的步骤s3.3中,建立的actor-critic网络具体为:
69、定义状态空间为动作空间为a={δkp1,δkd1,δkp2,δkd2};
70、建立所述动作actor网络act=μ(s|θμ),其中,μ表示actor网络,状态变量s为网络输入,θμ为网络参数,act为网络输出动作;
71、建立所述价值critic网络q(s,act|θq),其中,q表示critic网络,状态变量s和当前奖励函数值为网络输入,θq为网络参数,q为网络输出;
72、所述动作actor网络和所述动作价值critic网络均为单隐层神经网络。
73、所述的步骤4中,设计奖励函数,利用深度确定性策略梯度算法对actor网络进行更新,实时更新横向pid控制参数,具体过程为:
74、步骤s4.1:建立强化学习的奖励函数:
75、步骤s4.2:建立深度确定性策略梯度算法;
76、步骤s4.3:利用强化学习机制实时更新横向pid控制参数:
77、所述的步骤s4.1中,建立强化学习的奖励函数如下:
78、第一类奖励函数在时刻t设置为:
79、
80、为了使得横向位置误差最小,第一类奖励函数的设计思路是:某一时刻横向位置误差越小,给予网络当前时刻的奖励值奖励则越多。当横向位置误差为零时,这是轨迹跟踪最好的效果,不过考虑到实际运行情况和控制算法的鲁棒性,可以设置参数err0,当横向位置误差满足|err(t)|≤err0时,认为车辆轨迹跟踪效果较好,给予最大的奖励函数值r1(t)=0;当横向位置误差满足err0<|err(t)|≤err1时,可认为车辆跟踪误差较小,给予较大的奖励函数值r1(t)=a0(a0<0);当横向位置误差满足err1<|err(t)|≤err2时,此时误差已经较大,为了保证智能体学习到较好的控制策略,设置线性奖励函数值r1(t)=a1|err|(a1<0);当横向位置误差满足|err(t)|>err1,此时跟踪误差非常大,给予与横向误差成幂级数的奖励函数值r1(t)=a2err2(a2<0)。
81、第二类奖励函数在时刻t设置为:
82、
83、第二类奖励函数则是根据车辆航向角误差为主要计算参数来进行设计,目标是使得车辆沿着预设轨迹平行运动。通过最大化道路坐标系的纵向速度分量、最小化道路坐标系的横向速度分量可以使得车辆的运动方向尽可能平行于预设轨迹方向。
84、整个奖励函数设置如下:
85、r(t)=r1(t)+r1(t)
86、
87、所述的步骤s4.2中,建立的深度确定性策略梯度算法ddpg具体为:
88、ddpg计算公式具体为:
89、
90、
91、yi=ri+γθq′(si+1,π′(si+1|θu′)|θq′)
92、更新方式为:
93、θu′←τθu+(1-τ)θu′
94、θq′←τθq+(1-τ)θq′
95、其中,τ是训练超参数,可以防止训练过程中网络出现过拟合的现象,保证训练过程稳定进行。
96、具体的步骤如下:
97、s4.2.1输入状态s、当前网络权重系数θu和θq初始化;
98、s4.2.2目标网络权重系数θu′和θq′初始化;
99、s4.2.3清空经验回放池;
100、s4.2.4基于状态st选择动作actt,执行动作后获得新状态st+1、奖励rt;
101、s4.2.5将四元组<st,st+1,actt,rt>存入经验池;
102、s4.2.6从经验池中采样大小为n的经验数据<si,si+1,acti,ri>;
103、s4.2.7根据transition计算tdtarget:yi=ri+γθq′(si+1,π′(si+1|θu′)|θq′);
104、s4.2.8最小化mseloss:更新critic网络;
105、s4.2.9计算策略梯度:
106、s4.2.10更新目标网络权重系数:θu′←τθu+(1-τ)θu′,θq′←τθq+(1-τ)θq′,返回步骤s4.2.4;
107、所述的步骤s4.3中,利用强化学习机制实时更新横向pid控制参数如下:
108、当前时刻t的pid控制参数为[kp1(t)、kp2(t)、kd1(t)、kd2(t)],当前时刻接收车辆的横向位置误差err(t)、横向位置误差变化率车辆航向角误差车辆航向角误差变化率四个状态参数,通过err(t)、vx(t),vy(t)得到当前时刻t的动作奖励值,通过actor-critic网络输出动作空间[δkp1(t)、δkp2(t)、δkd1(t)、δkd2(t)],得到t+1时刻更新后的pid控制参数如下:
109、
110、此时基于pid参数计算得到横向控制的方向盘转角作用于被控车辆,实现横向pid控制的参数在线优化,t+1时刻的方向盘转角如下:
111、
112、所述的步骤5中,设计合适的训练地图进行强化学习的训练,设计测试地图对训练好的模型进行测试,评估其在真实场景下的跟踪控制效果,具体过程为:
113、步骤s5.1:纵向pid控制参数的整定;
114、步骤s4.1:横向pid控制参数的整定;
115、步骤s4.2:强化学习的训练和测试;
116、s5.1纵向pid控制参数的整定步骤如下:
117、s5.1.1选择不同的包含直道和弯道的道路场景,通过离散化道路场景计算道路曲率;
118、s5.1.2设置直道目标纵向车速,利用道路曲率和直道目标纵向车速计算弯道目标纵向车速,生成目标纵向车速序列;
119、s5.1.3选择直道场景,初始化车辆速度为直道目标纵向车速,基于实际纵向车速和目标纵向车速误差进行纵向pid控制的调参;
120、s5.1.4根据实际控制效果,对纵向pid参数进行实时调整,得到最优的纵向pid控制参数。
121、s5.2横向pid控制参数的整定步骤如下:
122、s5.2.1选择包含直道和弯道的道路场景,通过离散化道路场景计算道路曲率和道路航向角;
123、s5.2.2设置直道目标纵向车速,利用道路曲率和直道目标纵向车速计算弯道目标纵向车速,生成目标纵向车速序列;
124、s5.2.3初始化纵向pid控制器的参数为最优参数;
125、s5.2.4选择包含直道和弯道的道路场景,初始化车辆速度为该道路场景下的目标纵向车速序列的第一个值,基于横向位置误差和航向角误差进行横向pid控制的调参;
126、s5.2.5根据实际控制效果,对横向pid参数进行实时调整,得到最优的横向pid控制参数。
127、s5.3强化学习的训练和测试步骤如下:
128、s5.3.1选择包含不同道路场景的训练地图,其中包括较多不同曲率的弯道和直道;
129、s5.3.2分别初始化纵向pid控制器参数和横向pid控制器参数为最优参数,初始化车辆速度为该道路场景下的目标纵向车速序列的第一个值;
130、s5.3.3初始化actor网络和critic网络及其各自的目标网络;
131、s5.3.4根据车辆当前时刻t的状态选择动作[δkp1(t)、δkp2(t)、δkd1(t)、δkd2(t)]进行环境交互,设置ornstein-uhlenbeck噪声项添加到动作中,得到奖励r(t)和下一时刻的状态
132、s5.3.5将当前时刻t的状态动作[δkp1(t)、δkp2(t)、δkd1(t)、δkd2(t)]、奖励r(t)、下一时刻的状态存储在经验池缓冲区中;
133、s5.3.6定期从共享缓冲区中抽取一批经验,通过最小化预测q值和目标q值之间的均方误差来更新critic网络,使用深度确定性策略梯度算法更新actor网络;
134、s5.3.8基于当前和目标网络的权重,对actor目标网络和critic目标网络进行软更新;
135、s5.3.9设计测试道路对训练好的模型进行测试,利用横向位置误差和航向角误差评估控制器的控制性能。
136、本发明的有益效果:
137、本发明针对自动驾驶汽车的横向控制问题,提出了一种基于强化学习的改进pid横向跟踪控制方法。该方法不仅解决了传统pid控制对于自动驾驶汽车在鲁棒性和适应不确定环境方面的不足,同时也解决了强化学习训练不稳定、易陷入局部最优解的问题。该方法充分利用了pid控制的收敛速度快、稳定性好、实现简单等优点,以及强化学习可在线学习、在线交互方面的优势。通过结合这两种方法,提高了自动驾驶汽车横向控制的跟踪精度和鲁棒性,有效地减轻了道路环境不确定性对控制效果的影响。
本文地址:https://www.jishuxx.com/zhuanli/20240718/253109.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。