基于大型语言模型的自动工单处理系统及方法与流程
- 国知局
- 2024-09-05 14:37:00
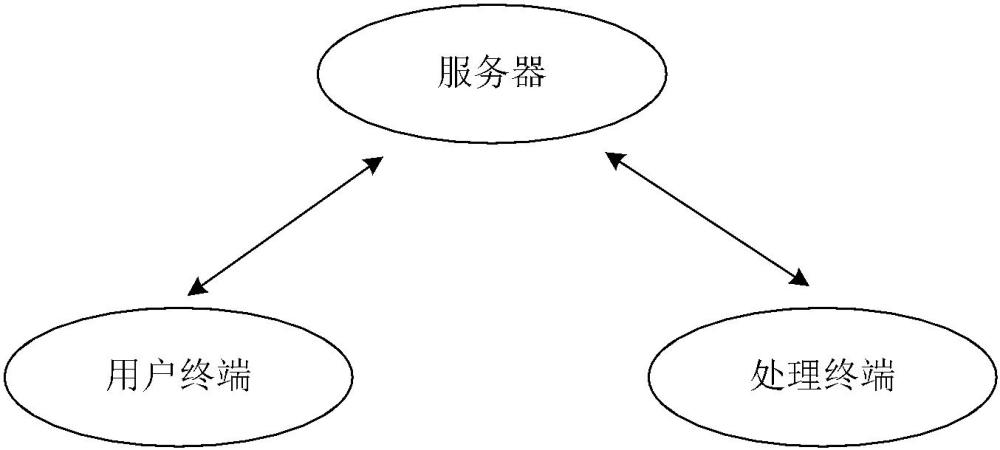
本发明属于工单处理,具体涉及一种基于大型语言模型的自动工单处理系统及方法。
背景技术:
1、工单是企业或组织的服务系统中的一个重要工具,主要用于记录职工的诉求、需求或问题,以及企业或组织对此的响应和处理措施。工单可以看作是职工与企业或者组织之间互动的凭证,也是企业或者组织追踪、解决问题和评估服务效果的基础。
2、在企业数字化转型的时代背景下,随着第三代支撑系统的云化,系统变更日益频繁,同时为了快速响应市场变化和客户需求,企业的业务领域不断扩展,系统的复杂性快速增长,这些现状为业务诉求处理带来了新的挑战。在企业工单系统中,对业务诉求中的非结构化信息的处理是重中之重,非结构化数据包括文本、图片、音频和视频等,同时外部输入的信息具有趋向模糊性、不确定性等一系列问题。
3、而传统的工单系统仅仅依靠人工来处理诉求存在处理质量和效率低下的问题。同时,诉求信息以短文本为主,具有语义稀疏、模糊性、不确定性的特点,传统特征提取方法无法获取文本的完整语义。
技术实现思路
1、本发明的目的是提供一种基于大型语言模型的自动工单处理系统及方法,用以解决传统的工单系统仅仅依靠人工来处理诉求存在处理质量和效率低下的问题。
2、为了实现上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供了一种基于大型语言模型的自动工单处理系统,所述系统包括:用户终端、服务器和处理终端,所述用户终端和处理终端均与服务器通信连接;
4、所述用户终端用于录入用户的服务需求,将用户的服务需求上传至服务器;
5、所述服务器包括:
6、工单创建模块,用于获取用户的服务请求,基于大语言模型对用户的服务请求进行分析,得到用户的服务需求,判断用户的服务需求是否为已有需求,若是,匹配已有的工单;若否,生成工单填写任务,以对用户进行交流问答,采集工单所需的必要信息,根据必要信息创建新的工单;将新的工单或已有工单作为服务工单保存在数据库中,并将该服务工单标记为待分配状态;
7、工单分配模块,用于获取处于待分配状态的服务工单,调用自动分配接口,确定该服务工单所属的处理部门;统计该处理部门的各处理人员的工单量,根据该处理部门的各处理人员的工单量,将处于待分配状态的服务工单分配给该处理部门对应的处理人员,并将该服务工单标记为待处理状态;
8、工单处理模块,用于调用工单处理接口,基于服务工单生成工单处理任务,将工单处理任务下发给处理终端;
9、所述处理终端用于在执行工单处理任务的过程中,记录工单处理任务的执行记录,将执行记录上传给服务器,所述服务器还用于在工单处理任务完成后,将该服务工单标记为已处理状态;并将处于已处理状态的服务工单同步给用户终端。
10、第二方面,本发明提供了一种基于大型语言模型的自动工单处理方法,所述方法包括:
11、基于大语言模型对用户产生的服务请求进行分析,以自动创建该用户的服务工单;
12、确定该用户的服务工单所属的处理部门,统计该处理部门的各处理人员的已有工单量,根据各处理人员的已有工单量,将该服务工单分配给该处理部门的对应的处理人员;
13、在完成对该服务工单的分配后,基于该服务工单生成工单处理任务,在工单处理任务被执行的过程中,记录工单处理任务的执行记录。
14、优选地,基于大语言模型对用户产生的服务请求进行分析,以自动创建该用户的服务工单,包括:
15、获取用户的服务请求,将该服务请求输入到大语言模型中,提取该服务请求的摘要;
16、判断预先构建的工单库中是否存在与该服务请求的摘要相似或相同的关键词,若存在,根据关键词匹配出已有的工单;若不存在,基于大语言模型对摘要进行扩充,得到交流问答文本;
17、基于交流问答文本,获取该用户的问题意图;
18、基于大语言模型提取该用户的问题意图中的必要信息,根据必要信息创建新的工单,以创建的新的工单或者匹配到的已有的工单作为服务工单。
19、优选地,在创建该用户的服务工单后,所述方法还包括:
20、获取创建的该用户的历史工单;
21、判断新建的该用户的服务工单是否与该用户的历史工单重复;
22、若是,删除新建的服务工单,并生成提示文本以告知该用户;
23、统计新建的该用户的服务工单与该用户的历史工单的重复次数;
24、构建该用户历史工单的处理优先级,并根据重复次数生成优先级的提升提示,以告知用户是否提高历史服务工单的处理优先级。
25、优选地,判断新建的该用户的服务工单是否与该用户的历史工单重复,包括:
26、对该用户的历史工单进行内容拆分,得到第一字符集,对新建的该用户的服务工单进行内容拆分,得到第二字符集;
27、对第一字符集进行编码,得到第一字符集中的每个字符的第一词向量、第一位置向量和第一嵌入向量;将第一字符集中的所有字符的第一词向量、第一位置向量和第一嵌入向量进行叠加输入到预先训练好的文本提取模型中,得到第一文本向量;
28、对第二字符集进行编码,得到第二字符集中的每个字符的第二词向量、第二位置向量和第二嵌入向量;将第二字符集中的所有字符的第二词向量、第二位置向量和第二嵌入向量进行叠加输入到预先训练好的文本提取模型中,得到第二文本向量;
29、对第一文本向量进行平均池化处理,得到处理后的第一文本向量;对第二文本向量进行平均池化处理,得到处理后的第二文本向量;
30、计算处理后的第一文本向量与处理后的第二文本向量的相似度;
31、判断处理后的第一文本向量与处理后的第二文本向量的相似度是否大于预设值;
32、若是,新建的服务工单为非重复工单;若否,新建的服务工单为重复工单。
33、优选地,所述处理后的第一文本向量与处理后的第二文本向量的相似度的计算表达式为:
34、;
35、式中, f为处理后的第一文本向量与处理后的第二文本向量的相似度,为余弦相似度函数。
36、优选地,当服务工单为已有的工单时,所述工单处理任务包括至少一个解决方案,所述解决方案用于解决服务工单中需要解决的问题;
37、基于该服务工单生成工单处理任务,包括:
38、提取出服务工单中需要解决的问题;
39、从方案库中推荐出至少一个用于解决服务工单中需要解决的问题的解决方案。
40、优选地,从方案库中推荐出至少一个用于解决服务工单中需要解决的问题的解决方案,包括:
41、基于预设检索模型对服务工单中需要解决的问题进行分词,得到若干词;
42、计算每个词分别与方案库中的各方案文档的相关度;
43、根据每个词分别与方案库中的各方案文档的相关度,确定该服务工单中需要解决的问题与各方案文档的文本相关度评分;
44、筛选出文本相关度评分大于预设评分的方案文档,得到待选解决方案集,所述待选解决方案集中包含有若干待选解决方案;
45、计算各待选解决方案分别与服务工单中需要解决的问题之间的相似性,得到若干相似度值;
46、按从大到小对若干相似度值进行排序,得到相似度序列;
47、取相似度序列前k个相似度值对应的待选解决方案作为解决服务工单中需要解决的问题的解决方案。
48、优选地,所述每个词分别与方案库中的各方案文档的相关度的函数表达为:
49、;
50、式中,为第 i个词与方案文档 d的相关度,为第 i个词在方案文档 d中出现的频率, k1为第一调节因子,b为第二调节因子,为方案文档 d的长度与平均长度的比值。
51、优选地,该服务工单中需要解决的问题与各方案文档的文本相关度评分的函数表达式为:
52、;
53、式中, s为服务工单中需要解决的问题与各方案文档的文本相关度评分,为第 i个词与方案文档 d的相关度,为包含词的文档数, n为方案文档的总数, k0为调教系数, n为词总数。
54、有益效果:
55、本发明利用大型语言模型对用户的服务请求分析,并通过自然语言进行沟通和交流,以完善填报工单所需的必要信息;同时,利用大型语言模型进行工单接口调用,实现工单的自动生成和派发,从而提高工单处理效率和准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240905/287309.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。