动态强化学习使能的重载列车群组协同控制方法、系统、终端及介质
- 国知局
- 2024-08-01 09:00:51
本发明涉及轨道交通控制,尤其涉及一种动态强化学习使能的重载列车群组协同控制方法、系统、终端及介质。
背景技术:
1、随着社会经济的发展,重载列车在物流运输中扮演着重要的角色。然而,随着列车群组规模的增加和运输任务的复杂性提高,传统的列车协同控制方法面临一系列挑战。首先,由于列车群组的规模庞大,传统的控制方法可能难以适应复杂的动态环境和实时变化的运输需求。其次,列车之间的相互影响和协同行为需要更为智能和适应性的控制策略。此外,考虑到列车系统的安全性和运行效率,需要在协同控制中引入更为先进的决策机制。
2、在现有研究中,虽然考虑了安全距离这一约束条件,但在设计控制器时,对速度协同项与安全距离项的权重系数通常是基于经验或试凑得到的。这种做法存在一定的主观性和固定性,未能充分考虑实际运行环境的动态变化。由于权重系数的设定直接影响到速度跟踪的性能以及运行的安全性,缺乏基于环境动态获取的精准调整,可能导致系统在不同条件下的性能表现不一致。
3、中国专利cn117389157a公开了一种虚拟编组高速列车运行滑模控制方法,该发明通过构建虚拟编组高速列车的动力学模型,基于位移和速度信息构建运行模式,并确定运行滑模控制律,用于高速列车的运行。中国专利cn117104305a公开了一种虚拟编组列车分布式协同追踪控制方法,该发明一种虚拟编组列车分布式协同追踪控制方法,包括构建全局最优控制问题、求解本地最优控制子问题、更新本地变量等步骤。通过迭代求解,得到当前列车单元的最优控制命令序列,实现列车的分布式协同控制。中国专利cn116279690a公开了一种虚拟耦合高速列车群协同运行控制方法,进一步压缩列车追踪间隔,实现具有不同初始状态的高速列车群协同运行控制。以上现有技术主要考虑列车间的速度跟踪协同、安全距离控制等目标,缺乏针对动态环境的智能控制策略。
技术实现思路
1、本发明提供一种动态强化学习使能的重载列车群组协同控制方法、系统、终端及介质,引入深度确定策略梯度等强化学习算法,以实现对速度协同项和安全距离项的自适应权衡,从而提高列车群协同运行的性能和适应性。
2、为实现上述技术目的,本发明采用如下技术方案:
3、第一方面,本发明提供一种动态强化学习使能的重载列车群组协同控制方法,包括:
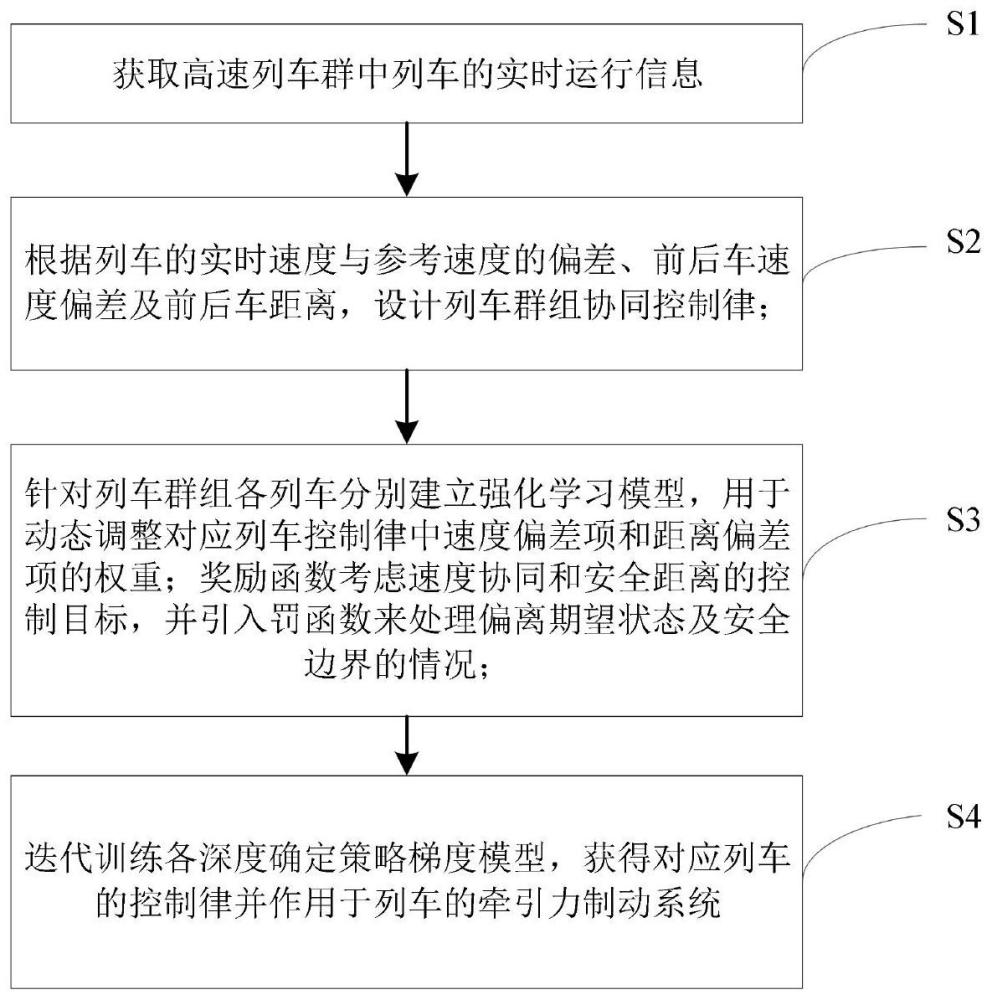
4、s1:获取重载列车群组中列车的实时运行信息;其中,所述运行信息包括每辆列车的速度信息和位置信息;
5、s2:根据列车的实时速度与参考速度的偏差、前后车速度偏差以及前后车距离,设计列车群组协同控制律;
6、s3:针对列车群组中的每台列车分别建立各自的强化学习模型,具体选用深度确定策略梯度模型,用于动态调整对应列车控制律中速度偏差项和距离偏差项的权重;其中,强化学习模型的奖励函数,考虑速度协同和安全距离的控制目标,并引入罚函数来处理偏离期望状态及安全边界的情况;
7、s4:迭代训练各深度确定策略梯度模型,获得对应列车的控制变量并作用于列车的牵引力制动系统。
8、进一步地,所述设计列车群组协同控制律,列车i的控制律设计为:
9、
10、式中,ui(t)为t时刻列车i的控制律;为t时刻列车i的实时速度与参考速度的偏差,为t时刻列车i与前后车辆的速度偏差,为t时刻列车i前后车距离与安全距离偏差,α为列车前后速度偏差项的权重,β为距离偏差项的权重;其中:
11、
12、
13、
14、式中,为t时刻列车i的参考速度,vi(t)为t时刻列车i的实时速度;vj(t)为t时刻列车j的实时速度,n为列车群组中的列车总数,aij为邻接参数,当列车j是列车i的前后车时,aij=1,否则为0;pi(t)为t时刻列车i的实时位置;pk(t)为t时刻列车k的实时位置,列车k为列车i的后车,dsafe为前后车应保持的安全距离。
15、进一步地,对每台列车建立强化学习模型,包括:
16、(1)定义状态空间,即确定系统状态s的表示,包括列车实时速度与参考速度的速度偏差eref、前后车辆速度偏差evel、前后车距离与安全距离偏差epos;
17、(2)定义动作空间,即确定系统的执行动作a及其取值范围,其中执行动作a包括速度偏差项的权重α和距离偏差项的权重权重β;
18、(3)设计奖励函数r为:
19、r=rref+rvel+rpos-p
20、其中,为参考速度跟随奖励项,k1是调节参考速度跟随奖励的常数,为前后车速度协同奖励项,k2是调节前后车速度协同奖励的常数,为前后车安全车距奖励项,k3是调节前后车安全车距奖励的常数;
21、
22、其中,p是罚函数,k4、k5分别为速度惩罚项、距离惩罚项的系数。
23、进一步地,所述深度确定策略梯度模型的训练过程为:
24、s4.1:建立深度确定策略梯度模型,采用actor-critic结构;其中actor网络为:
25、a=actor(s|θactor)
26、其中,a是强化学习的执行动作,s是强化学习的状态表示,θactor是actor网络的参数;
27、critic网络为:
28、q(s,a|θcritic)
29、其中q是值函数,θcritic是critic网络的参数;
30、s4.2:设定优化目标:定义累积奖励其中t是时间步,γ是折扣因子;
31、s4.3:最大化累计奖励:
32、
33、s4.4:迭代训练深度确定策略梯度模型,实时调整执行动作a中的权重α和β,得到t时刻列车i的控制律并作用于列车i的牵引制动系统产生牵引力或制动力;其中,为t时刻列车i的实时速度与参考速度的偏差,为t时刻列车i与前后车辆的速度偏差,为t时刻列车i前后车距离与安全距离偏差。
34、进一步地,在步骤s4.3最大化累计奖励时,使用梯度上升法更新actor网络参数,使用梯度下降法更新critic网络参数:
35、
36、
37、其中,λ、μ是学习率,是累计奖励j对于actor网络参数θactor的梯度,是q值对于critic网络参数的梯度;
38、第二方面,本发明提供一种动态强化学习使能的重载列车群组协同控制系统,包括:
39、测量模块,用于:从车载设备和轨旁设备获取高速列车的实时运行信息,所述运行信息包括每辆列车的速度信息和位置信息;
40、通信模块,用于:对高速列车群组中相邻高速列车之间的实时运行信息进行相互传输;
41、控制模块,用于:根据列车的实时速度与参考速度的偏差、前后车速度偏差以及前后车距离,得到每辆高速列车的控制律,其中控制律包括速度偏差项的权重α和距离偏差项的权重β;
42、强化学习模块,用于:根据列车的实时信息,动态调整控制律中速度偏差项的权重α和距离偏差项的权重β;
43、动力模块,用于:根据控制律输出相应的牵引力或制动力,控制高速列车的速度变化。
44、第三方面,本发明提供了一种电子终端,包括处理器和存储器,所述存储器存储了计算机程序,所述处理器调用所述计算机程序以执行如上所述方法的步骤。
45、第四方面,本发明提供了一种可读存储介质:存储了计算机程序,所述计算机程序被处理器调用时以执行如上所述方法的步骤。
46、有益效果
47、本发明提出了一种动态强化学习使能的重载列车群组协同控制方法、系统、终端及介质,通过实时获取列车的运行信息,运用深度确定策略梯度算法,实现协同控制策略的动态调整。本发明可以智能地根据列车的实时速度、前后车速度偏差以及前后车距离等参数,灵活调整速度协同项和安全距离项的权衡,从而提升列车群组的智能化水平。通过迭代训练,本发明还对协同控制律的速度和距离偏差项权重进行了优化,实现了性能的全面提升,有效提高了列车群组的运行效率。本发明着重强调系统的适应性,通过在线学习和动态调整,使系统能够灵活适应不同的运行环境,极大地提升了系统的适应性和鲁棒性。在安全性方面,本发明设计了奖励函数,全面考虑了速度协同和安全距离的控制目标,并引入罚函数处理异常情况,有效地预防列车偏离期望状态及安全边界。本发明具备实时性和迭代优化的特点,使列车群组能够在不同运输需求和突发状况下快速、灵活地作出响应。总体而言,本发明的技术方案兼顾了智能化、性能优化、适应性、安全性和实时性。
本文地址:https://www.jishuxx.com/zhuanli/20240718/234444.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表