融合先验策略的改进TD3算法的无人机航迹规划方法
- 国知局
- 2024-08-01 00:20:29
本发明涉及无人机路径规划领域,尤其涉及一种融合先验策略的改进td3算法的无人机航迹规划方法。
背景技术:
1、近年来,随着科技的不断发展,无人机(unmanned aerial vehicle,uav)由于其高机动和低成本等特点,在军事、农业、交通以及公共管理等领域展现出了广泛的应用潜力。应用领域广泛的同时,其应用场景也在不断扩展,无人机需要到城市,农田,山区等各种存在障碍物和干扰的非净空环境中飞行。随着无人机任务的多样性和任务环境的复杂性增加,航迹规划成为确保无人机安全和效率的关键挑战。为提升无人机的智能性和自主性,复杂环境中无人机的航迹规划问题成为了国内外学者的研究重点。路径规划算法根据其事先对环境的需求不同,可以分为全局算法和局部算法。全局算法主要针对环境已知的静态环境,常见的算法有dijkstra、rrt、a*等。局部算法则适用于动态的或部分已知的环境,局部算法能够实时感知环境的变化来动态调整路径,常见的算法包括人工势场、蚁群算法、遗传算法等。
2、传统的局部路径规划算法虽然具备一定的适应能力,但也存在容易陷入局部最优、灵活性较差和在复杂环境中表现不佳等问题。相比之下,深度强化学习在处理不确定性和动态变化方面具有显著优势,因为它可以通过经验和训练数据学习处理随机和不可预测的情况。尽管目前许多研究在无人机路径规划领域取得了诸多进展,仍存在一些不足之处。首先,许多研究未考虑动态障碍物,或仅考虑了匀速移动的障碍物,而未考虑实际环境中的随机移动。其次,许多研究未考虑无人机电量对任务完成度的约束。
技术实现思路
1、针对上述提到的不足,本发明提出一种融合先验策略的改进td3算法的无人机航迹规划方法。本发明采用的技术方案如下:
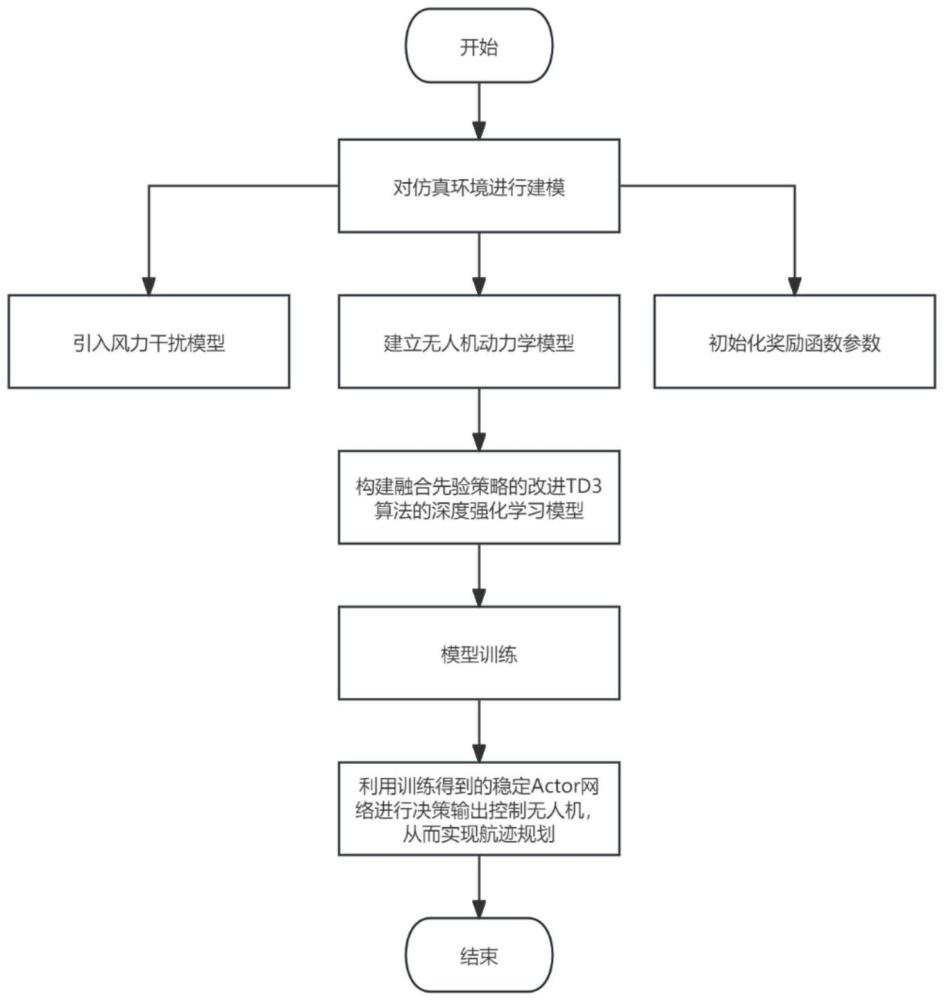
2、一种融合先验策略的改进td3算法的无人机航迹规划方法,具体步骤包括:
3、s1:对初始环境进行建模。
4、s2:建立无人机的动力学模型。
5、s3:构建融合先验策略的改进td3算法的深度强化学习模型后进行模型训练。
6、s4:利用训练得到的稳定actor网络进行决策输出控制无人机,从而实现航迹规划。
7、对于步骤s1中对初始环境进行建模,具体包括:
8、(1)对初始环境建模,包括静态障碍物和动态障碍物,采用以下设定,忽略无人机,动态障碍物的外形差异,将其全部等效为质点,静态障碍物等效为圆柱体,静态障碍物和动态障碍物的初始位置全部随机生成,且动态障碍物的移动完全随机,无人机与静态障碍物以及动态障碍物需要保持安全间隔,距离低于安全间隔即视为碰撞。
9、(2)为了更加符合真实环境和增加环境难度,引入一个风力扰动模型,这个模型用于模拟风力对于无人机在三维空间中的动态影响。风力干扰的模型公式为:
10、
11、其中,hf表示高度因子,这里z是无人机位置向量中的高度,假设高度每增加200米,风力强度增加的比例按平方增长,tf表示时间因子,这里t是时间步,模拟一天中风力的周期变化,表示风力的随机变化量,σ表示风力变化的标准差,用于控制风的随机波动,n(0,1,3)表示三维正态分布,均值为0,标准差为1,表示当前风速向量,imax表示最大风力强度,定义了风力的最大可能值,如果则对风速向量进行缩放。
12、对于步骤s2中,建立无人机的动力学模型,具体包括无人机的动力学方程如下:
13、
14、其中,表示t时刻无人机的实时速度信息,表示t时刻无人机的实时速度变化信息,式中δt表示时间间隔,表示引入风力干扰模型而产生的干扰。
15、对于步骤s3中构建融合先验策略的改进td3算法的深度强化学习模型后进行模型训练,具体包括:
16、(1)模型的输入采用无人机自身状态和目标点位置以及最近障碍物信息组合,共包含13个特征值,公式为(3):
17、
18、其中(xuav,yuav,zuav)表示t时刻无人机的三维位置坐标,表示t时刻无人机的实时速度信息,(xdest,ydest,zdest)表示无人机飞行目标点的三维位置坐标,(xobs,yobs,zobs)表示最近障碍物的三维位置坐标,如果为静态障碍物则为圆柱质心三维位置坐标,euav表示无人机剩余电量。
19、(2)actor网络架构在原本的td3之上引入了conv1d网络,conv1d的卷积核为1×1,步长也为1。1×1卷积。
20、(3)在td3原本的加入噪声的平滑操作改为加入批量噪声后求均值,公式为(4):
21、
22、(4)先验策略主要应用于智能体训练的初始阶段,提供初步的指导以促进智能体对环境的探索,并增加其在初始阶段达到目标的频率,先验策略的输入为无人机当前位置c_p,目标点位置t_p,距离无人机的最近障碍物的位置o_p,强化学习模型输出动作a,动作调整因子adj_f,公式为(5):
23、
24、(5)奖励函数的分为三个部分,第一部分是航迹规划的基础奖励,奖励或惩罚是否完成规划任务,第二部分是借鉴人工势场思想的引导奖励,用密集奖励的方式引导无人机有效避开障碍物并且快速接近终点;第三部分是其他优化目标的奖励,引导无人机在能耗和速度上寻求平衡。
25、(6)训练时,每局采用随机起始点和目标点,风力干扰以20%的概率在训练过程中的每一时刻出现,且持续时间随机,范围为10至20个时间步,处于风力干扰阶段时不会触发下一次干扰,训练最大时间步为100。
26、(7)训练时的先验策略采用线性衰减的策略逐步减弱对无人机策略的指引,最终几乎完全由强化学习主导无人机的航迹规划策略。
27、对于步骤s4中利用训练得到的稳定actor网络进行决策输出控制无人机,从而实现航迹规划,具体步骤为:
28、(1)获取t时刻无人机状态空间st。
29、(2)将状态空间st输入训练得到的actor网络中获取动作策略at。
30、(3)无人机执行动作策略at,得到下一个时间步的状态空间st+1。
31、(4)重复执行(1)-(3)直到仿真结束。
32、本发明的有益效果如下:
33、(1)借鉴人工势场的思想,本文提出了一种类似人工势场的奖励函数。这种奖励函数的设计能够帮助强化学习算法克服稀疏奖励的问题使无人机在训练的过程中每一步行动都能够得到有效反馈,提高了算法的学习效率。
34、(2)为了使强化学习算法在前期探索阶段获得更高质量的样本,提高训练效率,并确保最终训练效果不受限制,提出了一种简单而有效的先验策略。这种策略有助于强化学习算法在前期获得更高的样本质量,提升前期训练效率,从而更快收敛。
35、(3)本文提出了基于td3改进的算法。在无人机路径规划任务中,表现出更高的成功率、更低的碰撞率以及更强的适应能力。这种鲁棒性使得算法在电量充足和略有不足的情况下都能取得卓越的效果,并且展现出优于基础td3的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200671.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表