一种基于吸引力势场法的机器人扰动恢复动态运动基元及建立方法
- 国知局
- 2024-11-06 15:03:38
本发明涉及一种基于吸引力势场法的机器人扰动恢复动态运动基元及建立方法。
背景技术:
1、随着科技的快速发展,机器人被广泛应用于生活中的各行各业。为了避免复杂编程导致费时费力问题,满足机器人快速掌握需求运动以适应新工作任务,动态运动基元方法被广泛应用于机器人轨迹学习过程,并取得了显著成效。但是在轨迹学习过程中,因人为或环境因素的影响,一旦有扰动介入轨迹学习过程,这将会严重影响学习轨迹到达原示教轨迹的预定目标,从而导致机器人轨迹学习过程失败。扰动恢复动态运动基元方法是解决这个问题非常有效的方法,该方法设定机器人系统初始状态、目标状态和示教轨迹,利用时空耦合项和pd控制器通过在线求解微分方程,自适应调节有扰动介入的机器人轨迹学习运动过程,以确保学习轨迹保证运动趋势完好到达原预定运动目标。
2、扰动恢复动态运动基元是由ijspeert在2013年首次提出(ijspeert aj,nakanishi j,hoffmann h,et al.dynamical movement primitives:learning attractormodels for motor behaviors.neural computation,2013,25(2):328–373.brenna),在标准动态运动基元轨迹学习算法的基础上采用时间和空间相耦合的方法,提出一种控制系统,该系统解释为具有增益的比例微分控制器,以控制系统中点质量位置。并增加耦合项,以适应扰动介入的时间演化,达到了动态运动基元算法在轨迹学习过程中扰动恢复的目的,但其控制器增益是在理想的控制信号下设定,这就导致在实际情况下,会产生过大的加速度问题。karlsson]等在扰动恢复动态运动基元的研究内容基础上(karlsson m,carlsonf b,robertsson a,et al.two-degree-of-freedom control for trajectory trackingand perturbation recovery during execution of dynamical movement primitives[j].ifac-papersonline,2017,50(1):1923-1930),在控制器中增加前馈控制,降低控制器增益。并在耦合项中增加常数,以改善轨迹跟踪,实现实际情况下良好的加速度,并进行了机器人抓取实验完成了扰动恢复动态运动基元算法的应用验证。但是,以上针对动态运动基元自适应扰动恢复功能均缺少在轨迹学习过程中提升学习轨迹位置精度的内容。考虑到在型值点处建立吸引力势场函数的方法可用于改进此问题。
3、随着机器人的轨迹学习应用要求越来越精益,为了机器人在轨迹学习过程中既可以自适应扰动的介入,又能提升学习轨迹的位置精度。因此,提出一种基于吸引力势场法的机器人扰动恢复动态运动基元方法,其在无扰动介入和有扰动介入的情况下均可实现提升轨迹位置精度以及扰动恢复功能。
技术实现思路
1、本发明是为了解决上述现有技术存在的问题而提供一种基于吸引力势场法的机器人扰动恢复动态运动基元及建立方法。
2、本发明所采用的技术方案有:
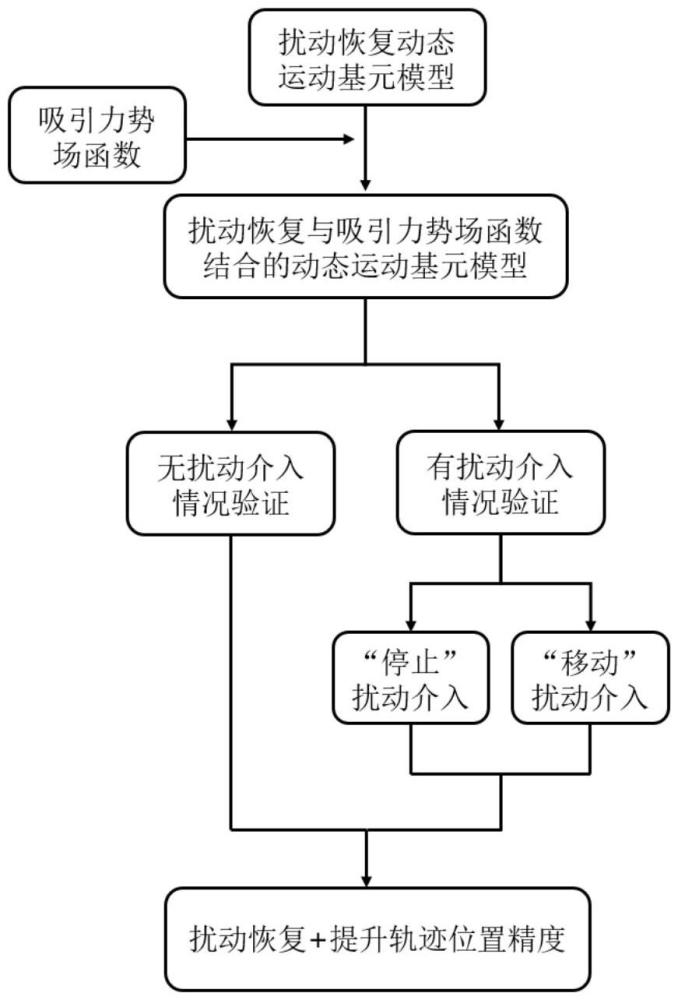
3、一种基于吸引力势场法的机器人扰动恢复动态运动基元建立方法,包括以下步骤:
4、s1:建立具有转换系统函数的基础扰动恢复动态运动基元模型;
5、s2:在示教轨迹型值点处建立吸引力势场函数下的梯度函数,将所述梯度函数耦合到所述转换系统函数中,并通过一阶滤波方法对转换函数进行改进,建立改进的扰动恢复动态运动基元模型;
6、s3:对改进扰动恢复动态运动基元模型进行实验验证。
7、进一步地,基础扰动恢复动态运动基元模型包括转换系统函数、非线性强迫函数、规范系统函数、pd控制器以及耦合项。
8、进一步地,所述转换系统函数定义为:
9、
10、其中,x∈[0,1]为相变量,z为辅助中间变量,τa为时间尺度参数,y=(yx,yy,yz)t定义为机器人末端位置,g为设定的轨迹目标点,αz和βz为常数参数,满足αz=4βz的关系;
11、非线性强迫函数f(x)使转换系统函数输出的轨迹连续光滑逼近设定的学习轨迹,由一组nw个径向基函数ψi(x)线性加权叠加组成,定义为:
12、
13、
14、其中,y0为设定轨迹的起点,ci和σi分别是基函数的宽度和中心,ωi是基函数的权值;
15、规范系统函数定义为:
16、
17、其中,αx为常数参数,满足αx>0;
18、pd控制器定义为:
19、
20、其中,kp和kv是pd控制器增益,ya是机器人实际情况下的运动轨迹,是实际轨迹下的速度,是实际轨迹下的加速度;yc是时间演化下的轨迹,是演化轨迹下的速度,是演化轨迹下的加速度,是参考加速度;
21、参考加速度由加速度进一步求出:
22、
23、耦合项定义为:
24、
25、其中,αe、kc和e是常数参数,耦合项第一项是一个低通滤波器,用来防止状态y的演化偏离实际轨迹ya。
26、进一步地,s2中,在示教轨迹型值点处建立吸引力势场函数下的梯度函数,将所述梯度函数耦合到所述转换系统函数中,步骤为:
27、定义型值点为示教轨迹中少数个重要轨迹点,其记录信息表示为:
28、
29、其中,分别为型值点处的位置和采样时刻点;
30、型值点处的势场能量定义为:
31、
32、其中,i=1,...,nw;j=x,y,z,为机器人末端位置,为第i个型值点位置,为型值点处的刚度因子;刚度因子元素越大,第i个型值点对中的离散轨迹吸引力越大;
33、以高斯函数表示吸引力势场函数在单个型值点处的势场能量定义为:
34、
35、其中,σdmp为型值点处势场能量高斯函数分布宽度;
36、吸引力势场函数在型值点处的总势场能量定义为:
37、
38、吸引力势场函数的总势场能量梯度函数类似于耦合人工势场法形式,其定义为:
39、
40、进一步地,s2中,耦合后的基于吸引力势场法的扰动恢复动态运动基元模型,采用一阶滤波方法避免机器人初始时刻的一阶跳跃导致的速度不连续问题,所述耦合吸引力势场函数的转换系统函数定义为:
41、
42、其中,yr∈r3×1表示位置一阶滤波迭代计算结果;
43、表示为吸引力势场函数在x轴、y轴和z轴方向的刚度矩阵。
44、至此,完成基于吸引力势场法的机器人扰动恢复动态运动基元模型的建立。
45、在无扰动介入和有扰动介入两种情况下分别对所提基于吸引力势场法的扰动恢复动态运动基元建立方法进行实验验证。其为:
46、采用三维空间下四节点样条轨迹进行验证,首先,在“无扰动”介入的情况下,对扰动恢复与吸引力势场函数结合的动态运动基元算法提升轨迹位置精度功能进行验证。
47、其次,在“停止”扰动和“移动”扰动介入的情况下,对基于吸引力势场法的机器人扰动恢复动态运动基元方法的提升轨迹位置精度以及扰动恢复功能进行验证。
48、本发明还公开了一种基于吸引力势场法的机器人扰动恢复动态运动基元,其采用上述方法建立。
49、本发明基于扰动恢复动态运动基元模型,将在示教轨迹中型值点处建立的吸引力势场函数,耦合到扰动恢复动态运动基元模型的转换系统函数中,并采用一阶滤波方法对转换系统函数进行改进。相对于基础的扰动恢复动态运动基元模型,基于吸引力势场法的机器人扰动恢复动态运动基元方法意义主要表现为两方面:一方面,在“无扰动”介入的机器人运动情况下,基于吸引力势场法的机器人扰动恢复动态运动基元能够实现良好的轨迹学习功能,相比基础的扰动恢复动态运动基元方法能够有效提升机器人学习轨迹的位置精度。另一方面,在“停止”扰动与“移动”介入的机器人运动情况下,基于吸引力势场法的机器人扰动恢复动态运动基元能够提高轨迹位置精度以及自适应扰动的介入,并在扰动结束后,逐渐恢复原示教轨迹趋势继续运动,最终到达预定目标,完成扰动介入恢复的轨迹学习进程。
本文地址:https://www.jishuxx.com/zhuanli/20241106/325126.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表