自适应调整用于自动驾驶动作规划中的参数的系统和方法与流程
- 国知局
- 2024-08-02 17:03:33
本公开涉及用于车辆自动驾驶的动作规划的系统和方法,更具体地,涉及自适应调整用于将车辆自动驾驶到目的地的动作规划中的超参数的系统和方法。
背景技术:
1、当前的自动驾驶动作规划系统在车辆操作期间面临许多环境条件和车辆条件方面的挑战。此类条件包括拥堵情况、恶劣天气、未建模的路况和车祸等。当前由一组工程超参数控制的在线动作规划系统通常可能会在不同的场景中遇到自动驾驶的计算挑战,并且可能是次优。因此,时间效率可能会受到影响。
技术实现思路
1、因此,虽然当前的动作规划架构实现了其预期目的,但需要一种新的且改进的系统和方法来自适应调整动作规划中的超参数,以将车辆自动驾驶到目的地,从而防止规划者做出次优的动作选择。
2、根据本公开的一个方面,提供了一种自适应调整用于将车辆自动驾驶到目的地的动作规划中的参数的方法。该方法包括:接收来自车辆的各种传感器的传感器数据、车道或地图数据、到目的地的道路(高级)规划以及由强化学习代理利用的多个第一超参数。强化学习代理具有自适应地优化多个第一超参数的规划策略。
3、在该方面,规划策略可以被建模为神经网络(下面将更详细地讨论)并且可以由至少一个隐藏层组成。在每一层,网络可以由至少一个神经元或节点组成。每个神经元都接收输入并生成输出。
4、该方法还包括:基于所接收的输入经由具有定义输出的至少一个激活函数的规划策略调整多个第一超参数,该多个第一超参数对应于传感器数据和车道数据以及高级道路数据。该至少一个第一激活函数包括:
5、o=f(w*input+b),
6、其中,input包括传感器数据、车道数据以及每个第一超参数;w是用于缩放每个第一超参数的权重矩阵,定义多个缩放后的超参数;b是用于调整每个缩放后的超参数的偏差;并且o是定义多个第二超参数的第一激活函数的输出。
7、在该方面,该方法还包括:基于多个第二超参数、传感器数据、车道数据以及处于最终状态和最终时间戳的轨迹奖励值来确定基线轨迹动作。轨迹奖励值包括:
8、rt=α1x rsearch,
9、其中,rsearch是基于安全函数、舒适度函数和预定道路规则的合规函数中的一者的默认奖励值,α1是基于第一驾驶模式的第一校准参数,并且rt是轨迹奖励值。
10、此外,该方法包括:基于多个第二超参数、传感器数据以及处于初始状态和最终状态的车道数据来修改基线轨迹动作,以定义精确轨迹动作,并且基于相对于传感器数据和车道数据的精确轨迹动作来控制车辆,以自动地将车辆驾驶到目的地。
11、在一个示例中,该方法还包括:在训练代理中接收训练环境数据、训练道路规划数据和多个初始超参数。训练代理被布置为迭代地调整用于自适应调整多个初始超参数的初始策略。初始策略具有至少一个训练激活函数,来定义训练输出。该至少一个训练激活函数包括:
12、ot=ft(wt x inputt+bt),
13、其中,inputt包括环境数据、道路规划数据和每个初始超参数;wt是用于缩放每个初始超参数的权重矩阵,定义多个缩放后的初始超参数;bt是用于调整每个缩放后的初始超参数的偏差;并且ot是训练激活函数的训练输出。
14、在该示例中,该方法包括:通过初始策略的至少一个训练激活函数来调整多个初始超参数,以定义多个超参数。该方法还包括:基于多个训练超参数和轨迹奖励值来确定训练轨迹动作。轨迹奖励值包括
15、rt=α1x rsearch,
16、其中,rsearch是基于安全函数、舒适度函数和预定道路规则的合规函数之一的默认奖励值,α1是基于第一驾驶模式的第一校准参数,并且rt是轨迹奖励值。
17、此外,对于该示例,该方法包括:基于训练轨迹动作和奖励设计值来修改初始策略的至少一个训练激活函数:
18、r=α1rsearch+α2refficiency,
19、其中,α2是基于第二驾驶模式的第二校准参数,refficiency是基于多个初始超参数的改变的计算成本以及基于动作轨迹的搜索的计算成本的效率奖励值,并且r是至少一个训练激活函数的奖励设计值以定义至少一个更新的激活函数。
20、而且,该方法还包括:通过初始策略的至少一个更新的激活函数迭代地调整多个训练超参数,以及基于多个训练超参数、至少一个更新的激活函数以及轨迹奖励值来迭代地确定更新的轨迹动作。
21、在该示例中,该方法还包括:基于更新的轨迹动作和奖励设计值来迭代地修改至少一个更新的激活函数;以及当迭代地最大化至少一个更新的激活函数的奖励设计值时,在强化学习代理中部署初始策略,以定义第一超参数和搜索调控器的规划策略的第一激活函数。
22、在该方面的另一示例中,效率奖励值基于由下式表示的多个初始超参数的改变的计算成本:
23、refficiency=-(β1rcompute+β2rparam_change),
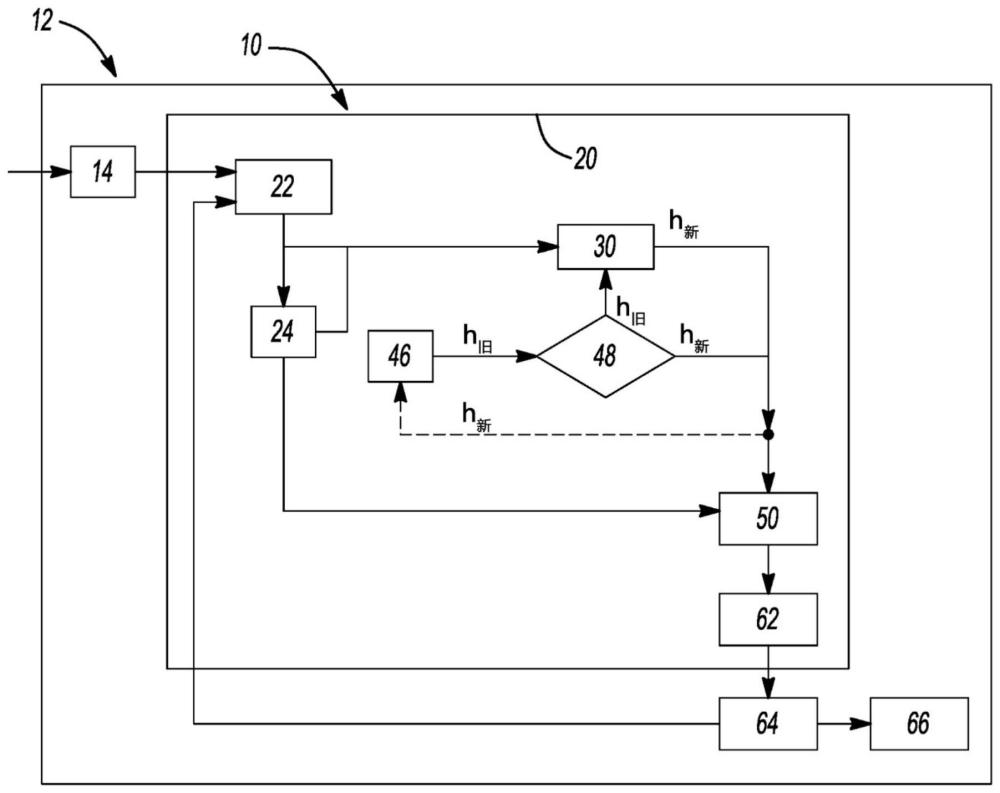
24、其中,rcompute为计算时长值,rparamchange为参数变化对驾驶影响的值,β1为第一校准参数,并且β2为第二校准参数。
25、在另一示例中,第一超参数和第二超参数中的每一个都包括状态数量、时间戳数量、时间戳大小和状态类型之一。在又一示例中,传感器数据包括关于车辆的环境数据、物体数据、天气数据、景观数据和路况数据。
26、在该方面的又一示例中,安全函数包括车辆周围的物体之间的距离、车辆到物体的距离。而且,舒适度函数包括加速度、车速、路况、道路类型。此外,合规函数包括交通流量、交通信号、交通标志和速度限制。
27、在又一示例中,确定基线轨迹动作包括基于第二超参数、传感器数据、车道数据以及处于第一状态和第一时间戳的轨迹奖励值来确定第一动作。另外,确定基线轨迹动作包括基于第二超参数、传感器数据、车道数据以及处于第二状态和第二时间戳的轨迹奖励值来确定第二动作。
28、在一个示例中,以相对于初始时间戳的预定时间频率来执行调整多个第一超参数。例如,预定时间频率在50毫秒至5秒之间。
29、根据本公开的另一方面,提供了一种用于自适应调整用于将车辆自动驾驶到环境的目的地的动作规划中的参数的系统。该系统包括设置在车辆上并且被布置为感测定义传感器数据的环境的至少一个传感器;以及设置在车辆中并且与该至少一个传感器通信的处理单元。
30、在该方面,处理单元包括被布置为从至少一个传感器接收传感器数据的场景模块和被布置为包括到目的地的道路规划的车道数据的路线模块。处理单元还包括搜索调控器,其是与场景模块和路线模块通信的强化学习代理。搜索调控器被布置为包括处于初始状态和初始时间戳的多个第一超参数。强化学习代理具有自适应地优化多个第一超参数的规划策略。搜索调控器被布置为经由规划策略基于传感器数据和车道数据来调整多个第一超参数。
31、规划策略具有用于定义输出的至少一个第一激活函数。该至少一个第一激活函数包括:
32、o=f(w*input+b),
33、其中,input包括传感器数据、车道数据以及每个第一超参数;w是用于缩放每个第一超参数的权重,定义多个缩放后的超参数;b是用于调整每个缩放后的超参数的偏差;并且o是定义多个第二超参数的第一激活函数的输出。
34、在该方面,处理单元还包括行为模块,其与搜索调控器通信并且被布置为基于多个第二超参数、传感器数据、车道数据以及处于最终状态和最终时间戳的轨迹奖励值来确定基线轨迹动作。轨迹奖励值包括:
35、rt=α1x rsearch,
36、其中,rsearch是基于安全函数、舒适度函数和预定道路规则的合规函数之一的默认奖励值,α1是基于第一驾驶模式的第一校准参数,并且rt是轨迹奖励值。
37、而且,处理单元包括与行为模块通信的轨迹模块。轨迹模块被布置为基于多个第二超参数、传感器数据以及处于初始状态和最终状态的车道数据来修改基线轨迹动作,以定义精确轨迹动作。
38、该系统还包括与处理器单元通信的车辆控制单元。车辆控制单元被布置为基于相对于传感器数据和车道数据的精确轨迹动作来控制车辆,以自动地将车辆驾驶到目的地。
39、在一个实施例中,该系统还包括训练框架或模块,其具有训练代理并且在部署期间与搜索调控器通信。训练模块被布置为接收训练环境数据、训练道路规划数据以及训练代理中的多个初始超参数。训练代理被布置为迭代地调整用于自适应调整多个初始超参数的初始策略。初始策略具有至少一个训练激活函数,以定义训练输出。
40、该至少一个训练激活函数包括:
41、ot=ft(wt x inputt+bt),
42、其中,inputt包括环境数据、道路规划数据和每个初始超参数;wt是用于缩放每个初始超参数的权重,定义多个缩放后的初始超参数;bt是用于调整每个缩放后的初始超参数的偏差;并且ot是训练激活函数的训练输出。
43、在该实施例中,训练代理还被布置为通过初始策略的至少一个训练激活函数来调整多个初始超参数,以定义多个训练超参数。训练代理还被布置为基于多个训练超参数和轨迹奖励值来确定训练轨迹动作。轨迹奖励值包括:
44、rt=α1x rsearch,
45、其中,rsearch是基于安全函数、舒适度函数和预定道路规则的合规函数中的一者的默认奖励值,α1是基于第一驾驶模式的第一校准参数,并且rt是轨迹奖励值。
46、在该实施例中,训练代理还被布置为基于训练轨迹动作和奖励设计值来修改初始策略的至少一个训练激活函数:
47、r=α1rsearch+α2refficiency,
48、其中,α2是基于第二驾驶模式的第二校准参数,refficiency是基于多个初始超参数的改变的计算成本的效率奖励值,并且r是至少一个训练激活函数的奖励设计值,以定义至少一个更新的激活函数。
49、而且,训练代理还被布置为通过初始策略的至少一个更新的激活函数来迭代地调整多个训练超参数。另外,训练代理被布置为基于多个训练超参数、至少一个更新的激活函数以及轨迹奖励值来迭代地确定更新的轨迹动作。
50、此外,对于该实施例,训练代理还被布置为基于更新的轨迹动作和至少一个更新的激活函数的奖励设计值来迭代地修改至少一个更新的激活函数。此外,训练代理还被布置为当迭代地最大化至少一个更新的激活函数的奖励设计值时,在强化学习代理中部署初始策略,以定义第一超参数和规划策略的第一激活函数。
51、在另一实施例中,效率奖励值基于由下式表示的多个初始超参数的改变的计算成本:
52、refficiency=-(β1rcompute+β2rparam_change),
53、其中,rcompute为计算时长值,rparamchange为参数变化对驾驶影响的值,β1为第一校准参数,并且β2为第二校准参数。
54、在又一实施例中,第一超参数和第二超参数中的每一个都包括用于在线搜索的多个状态、多个时间戳采样、时间戳大小以及状态类型或状态和动作的选择标准中的一个。在另一实施例中,传感器数据包括关于车辆的环境数据、物体数据、天气数据、景观数据和路况数据。
55、在又一实施例中,安全函数包括车辆周围的物体之间的距离、车辆到物体的距离。而且,舒适度函数包括加速度、车速、路况、道路类型。此外,合规函数包括交通流量、交通信号、交通标志和速度限制。
56、在另一实施例中,确定基线轨迹动作包括基于第二超参数、传感器数据、车道数据以及处于第一状态和第一时间戳的轨迹奖励值来确定第一动作。而且,确定基线轨迹动作包括基于第二超参数、传感器数据、车道数据以及处于第二状态和第二时间戳的轨迹奖励值来确定第二动作。
57、在又一实施例中,以相对于初始时间戳的预定时间频率来执行调整多个第一超参数。例如,预定时间频率在50毫秒至5秒之间。
58、根据本公开的又一方面,提供了一种自适应调整用于将车辆自动驾驶到目的地的动作规划中的参数的方法。该方法包括:接收来自车辆的传感器的传感器数据;到目的地的道路规划的车道数据;以及强化学习代理中处于初始状态和初始时间戳的多个第一超参数。强化学习代理具有自适应地优化多个第一超参数的规划策略。
59、该方法还包括:通过具有至少一个第一激活函数来定义输出的规划策略基于传感器数据和车道数据以相对于初始时间戳的预定时间频率来调整多个第一超参数。该至少一个第一激活函数包括:
60、o=f(w*input+b),
61、其中,input包括传感器数据、车道数据以及每个第一超参数;w是用于缩放每个第一超参数的权重,定义多个缩放后的超参数;b是用于调整每个缩放后的超参数的偏差;并且o是定义多个第二超参数的第一激活函数的输出。
62、在此方面,该方法还包括:基于多个第二超参数、传感器数据、车道数据以及处于最终状态和最终时间戳的轨迹奖励值来确定基线轨迹动作。轨迹奖励值包括:
63、rt=α1x rsearch,
64、其中,rsearch是基于安全函数、舒适度函数和预定道路规则的合规函数中的一者的默认奖励值,α1是基于第一驾驶模式的第一校准参数,并且rt是轨迹奖励值。
65、此外,该方法包括:基于多个第二超参数、传感器数据以及处于初始状态和最终状态的车道数据来修改基线轨迹动作,以定义精确轨迹动作,并且基于相对于传感器数据和车道数据的精确轨迹动作来控制车辆,以自动地将车辆驾驶到目的地。
66、在此方面的一个示例中,预定时间频率在50毫秒至5秒之间。
67、进一步的应用领域将从本文提供的描述中变得显而易见。应当理解,这些描述和具体示例仅用于说明的目的,并不旨在限制本公开的范围。
本文地址:https://www.jishuxx.com/zhuanli/20240718/253777.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。