一种增加车载虚拟助手智能交互体验的方法与流程
- 国知局
- 2024-08-02 16:34:49
本发明涉及一种车载虚拟助手的控制方法,特别涉及一种增加车载虚拟助手智能交互体验的方法。
背景技术:
1、现有的车载虚拟助手通常是显示在车机显示屏上虚拟形象,它的位置、姿态、朝向由固定的参数控制,当用户与其交互的时候,虚拟助手通常不能如同真人般做出注视、倾听的反馈,导致虚拟助手的形象非常机械呆板。
技术实现思路
1、本发明目的是,通过语音、图像等真实环境信息计算出用户的空间位置,实时调整车载虚拟助手的虚拟空间位置和身体朝向,使虚拟助手呈现出与真人相似的注视、倾听反应,增加其智能交互的体验。
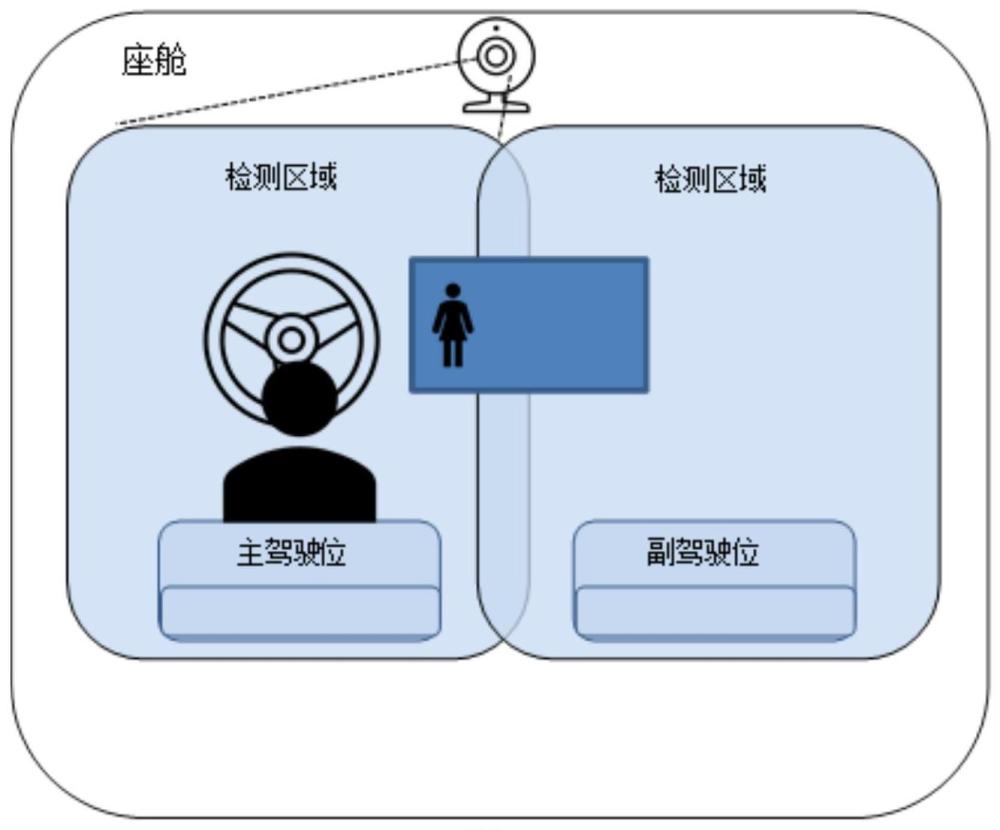
2、为了实现上述目的,本发明提供一种增加车载虚拟助手智能交互体验的方法,其中,座舱内设有声音传感器、图像采集装置,声音传感器、图像采集装置分别与车机信号连接;
3、车机通过分析声音传感器采集的信号,判断信号来源于驾驶位还是副驾驶位,将信号来源的驾驶位设定为目标驾驶位;
4、车机通过图像采集装置获取目标驾驶位的图像帧f后,将虚拟助手设置到更靠近目标驾驶位的虚拟空间位置tvirtual;
5、旋转虚拟助手使其朝向目标驾驶位。产生注视的效果。
6、优选的,车机通过图像采集装置获取目标驾驶位的图像帧f后,将图像帧f输入经过训练的关键点检测网络模型,输出包含眉毛、眼睛、鼻子、嘴巴、脸型在内的68个人脸五官轮廓的2d关键点;
7、根据68个2d关键点的索引关系,取得与关键点索引位置对应的3d人物头部的68组3d顶点,以及初始设置的虚拟相机参数;
8、将3d人物头部的68组3d顶点、初始设置的虚拟相机参数作为输入参数,使用弱透视投影模型得到3d顶点的2d投影点,与之前获得的2d关键点一一相减的差值作为损失函数,输入预训练的回归模型,获得相机焦距和人脸姿态数据,人脸姿态数据包括人脸xyz轴的空间位置坐标和旋转角度值;
9、设置虚拟空间变换矩阵及虚拟助手在虚拟空间参数;
10、将用户的人脸姿态数据通过矩阵变换到虚拟角色所处的虚拟空间;
11、计算获得虚拟助手对用户的朝向向量=虚拟角色所处的虚拟空间-虚拟助手的虚拟空间参数;
12、对朝向向量计算出yaw偏航角θ、pitch俯仰角α、roll翻滚角β,使用ekf算法进行滤波处理,使计算结果更加平滑,不会出现抖动;
13、使用滤波后的yaw偏航角θ′旋转虚拟助手使其朝向用户方向,产生注视的效果。
14、优选的,所述弱透视投影模型公式为:
15、
16、其中a是相机焦距构成的变换矩阵,r是旋转矩阵,t是平移向量,r和t构成了人脸姿态数据。
17、优选的,所述声音传感器数量最优位置为车舱顶部中央,声音采集区域更广,更准确。
18、优选的,所述声音传感器数量为多个,分别设置在座舱内的不同位置,获得更准确的定位效果。
19、优选的,所述图像采集装置是摄像头,设备容易获得,成本有限。
20、优选的,所述图像采集装置最优位置为车舱前部的顶部中央,避免被遮挡。
21、本发明所述的增加车载虚拟助手智能交互体验的方法,虚拟助手能通过语音、图像等真实环境信息计算出用户的真实空间位置,当虚拟助手处于待机状态或用户在与虚拟助手交互时,可以实时调整自己的虚拟空间位置和身体朝向,使虚拟助手呈现出与真人相似的注视、倾听反应,增加其智能交互的体验,使机械的虚拟助手更加人性化、智能化,提高用户对车机系统的信任感。该方法弥补了这块领域的技术空白。
技术特征:1.一种增加车载虚拟助手智能交互体验的方法,其特征在于,座舱内设有声音传感器、图像采集装置,声音传感器、图像采集装置分别与车机信号连接;
2.如权利要求1所述的增加车载虚拟助手智能交互体验的方法,其特征在于,车机通过图像采集装置获取目标驾驶位的图像帧f后,将图像帧f输入经过训练的关键点检测网络模型,输出包含眉毛、眼睛、鼻子、嘴巴、脸型在内的68个人脸五官轮廓的2d关键点;
3.如权利要求2所述的增加车载虚拟助手智能交互体验的方法,其特征在于,所述弱透视投影模型公式为:
4.如权利要求1所述的增加车载虚拟助手智能交互体验的方法,其特征在于,所述声音传感器设置于车舱顶部中央。
5.如权利要求1所述的增加车载虚拟助手智能交互体验的方法,其特征在于,所述声音传感器数量为多个,分别设置在座舱内的不同位置。
6.如权利要求1所述的增加车载虚拟助手智能交互体验的方法,其特征在于,所述图像采集装置是摄像头。
7.如权利要求1所述的增加车载虚拟助手智能交互体验的方法,其特征在于,所述图像采集装置最优位置为车舱前部的顶部中央。
技术总结本发明提供一种增加车载虚拟助手智能交互体验的方法,其中,座舱内设有声音传感器、图像采集装置,声音传感器、图像采集装置分别与车机信号连接;车机通过分析声音传感器采集的信号,判断信号来源于驾驶位还是副驾驶位,将信号来源的驾驶位设定为目标驾驶位;车机通过图像采集装置获取目标驾驶位的图像帧F后,将虚拟助手设置到更靠近目标驾驶位的虚拟空间位置,旋转虚拟助手使其朝向目标驾驶位。本发明通过语音、图像等真实环境信息计算出用户的空间位置,实时调整车载虚拟助手的虚拟空间位置和身体朝向,使虚拟助手呈现出与真人相似的注视、倾听反应,增加其智能交互的体验。技术研发人员:安海川,喻明星受保护的技术使用者:摩斯智联科技有限公司技术研发日:技术公布日:2024/7/4本文地址:https://www.jishuxx.com/zhuanli/20240718/251366.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表